



如果想要阅读源码,首先要选择版本,然后将源代码下载到本地,导入idea中,话不多说,直接看步骤吧
这里我选择5版本,
下载源码
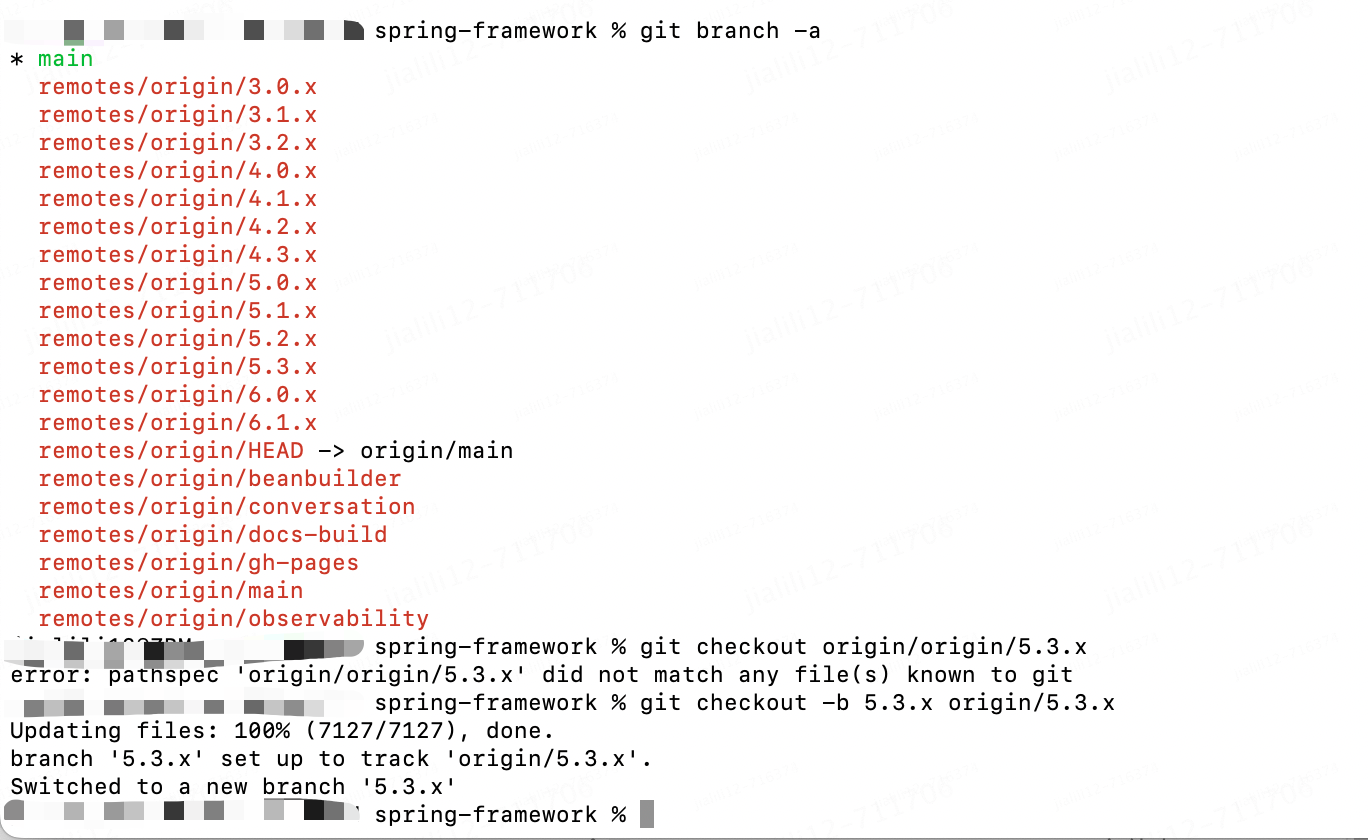
默认是main分支,看想学习的分支,比如我切换到5版本,截图如下:

2.安装gradle
3.转换源码进idea
下载完成后可以看到有个文档叫import-into-idea.md,这里介绍了怎么将代码导进idea,不过对我这种英语不好的真的是费劲,可以参考https://github.com/coderbruis/JavaSourceCodeLearning/blob/master/note/Spring/%E6%B7%B1%E5%85%A5Spring%E6%BA%90%E7%A0%81%E7%B3%BB%E5%88%97%EF%BC%88%E4%B8%80%EF%BC%89%E2%80%94%E2%80%94%E5%9C%A8IDEA%E4%B8%AD%E6%9E%84%E5%BB%BASpring%E6%BA%90%E7%A0%81.md
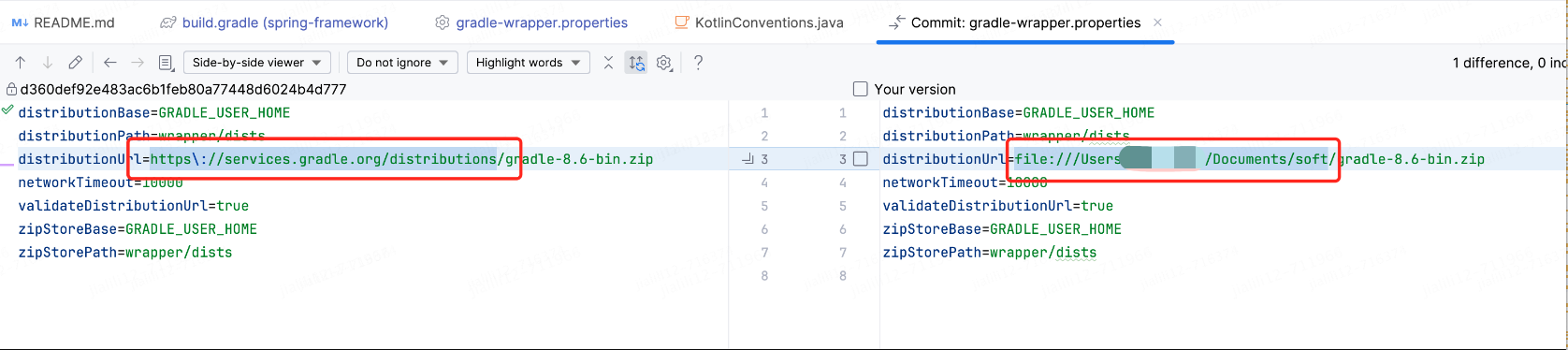
查看spring与gradle的版本对应,目录:spring-framework/gradle/wrapper/gradle-wrapper.properties
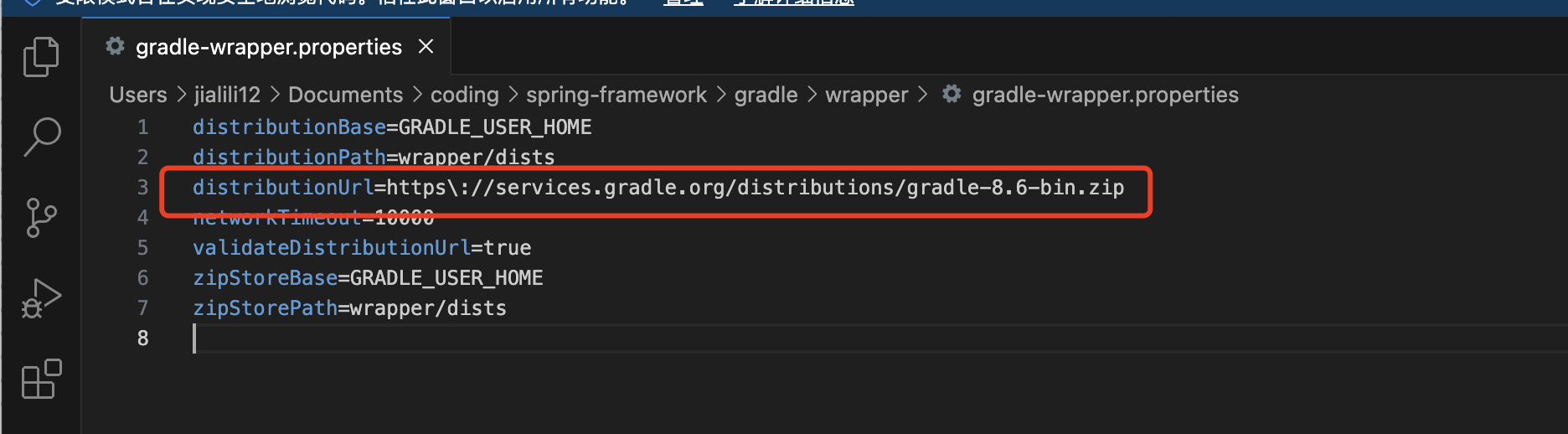
最好是要保持版本一致,否则可能下面的命令执行报错
默认每次都会下载gradle,现改成本地的文件即可
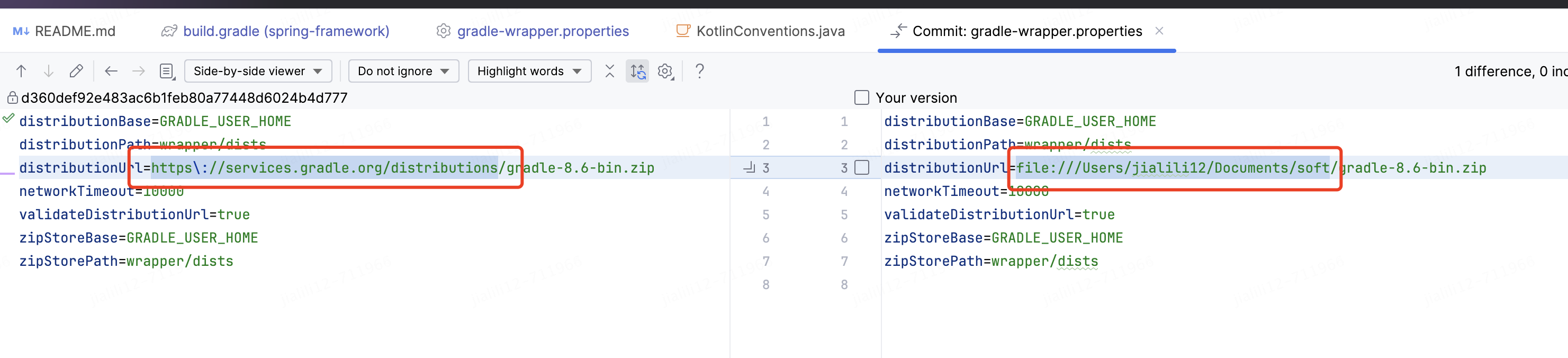
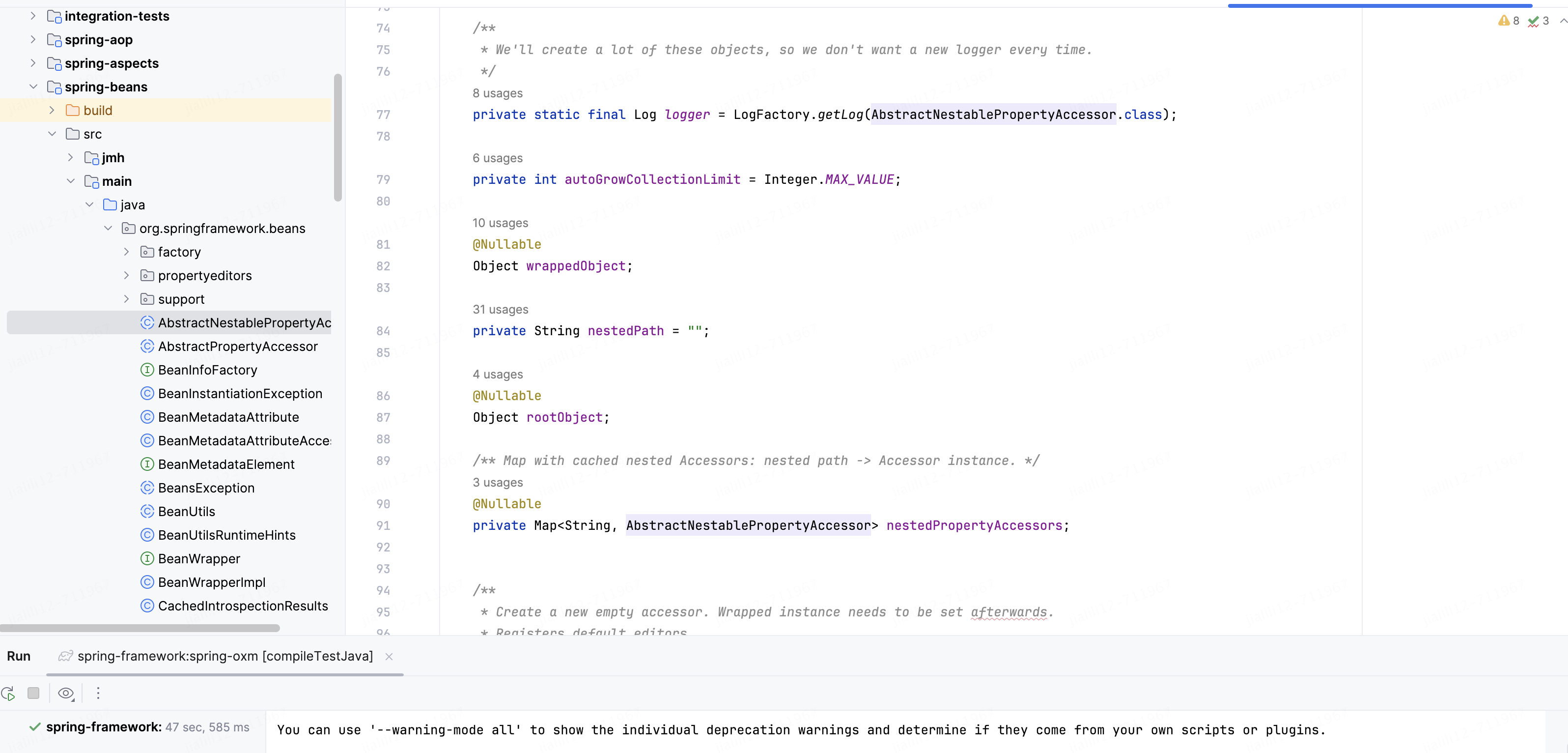
编译spring-oxm(jdk8报错,后来改成jdk21可以了,网上有说11也可以,可以自行实验,本人没有验证过,刚好在本地有21版本,直接拿来用了),由于开发使用1.8所以我就没有改系统默认jdk版本,先导入idea,在idea里面操作了,最终编译成功,截图如下
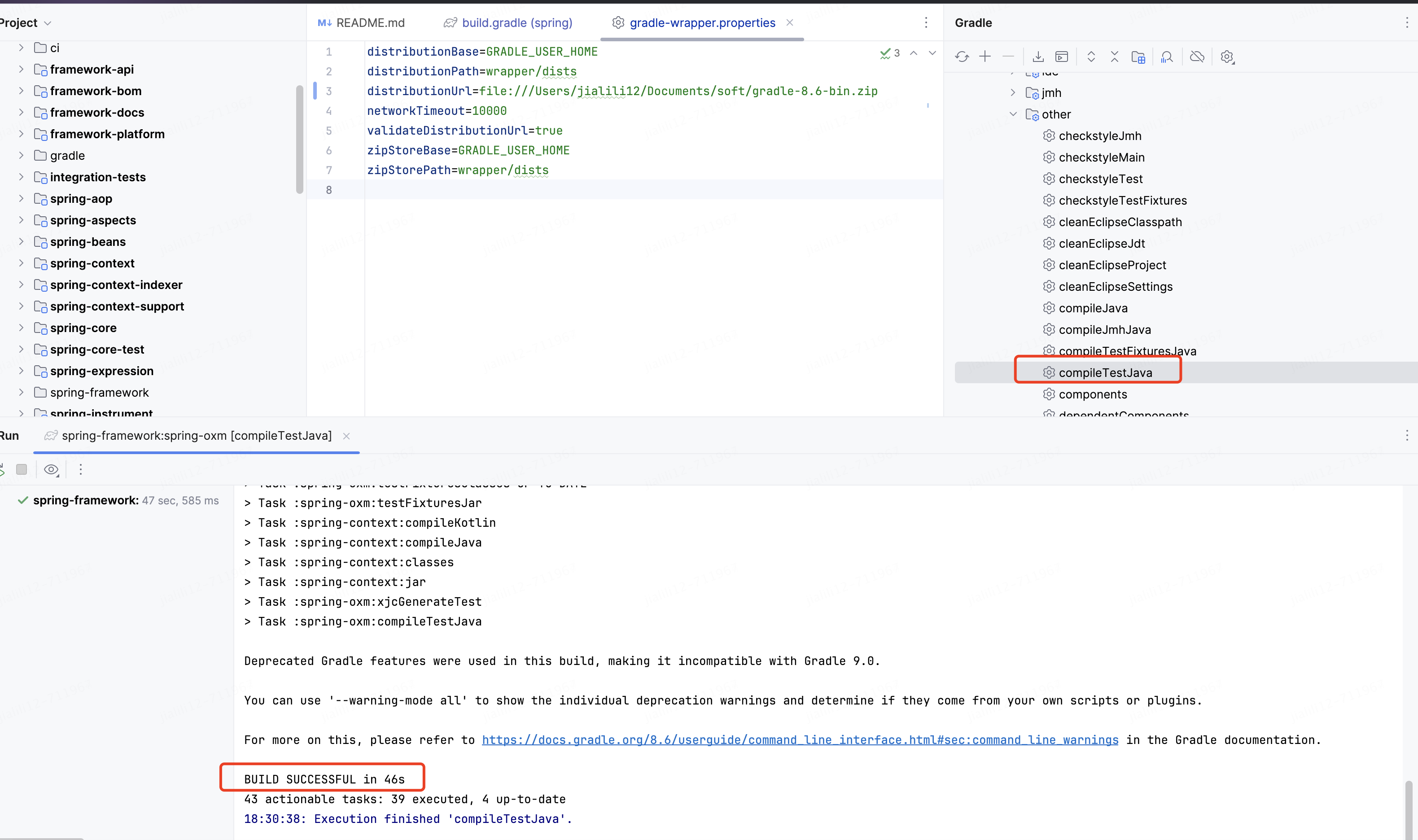
可以看到spring源码现在不报错了

可以看到就像是我们自己的项目一样,可以看到提交记录和提交人等相关信息,也可以直接修改
spring源码已下载到本地了,我最想了解的是bean的加载过程,然后点到代码里可以看到测试用例非常全面,试运行了一下,确实可以运行截图如下
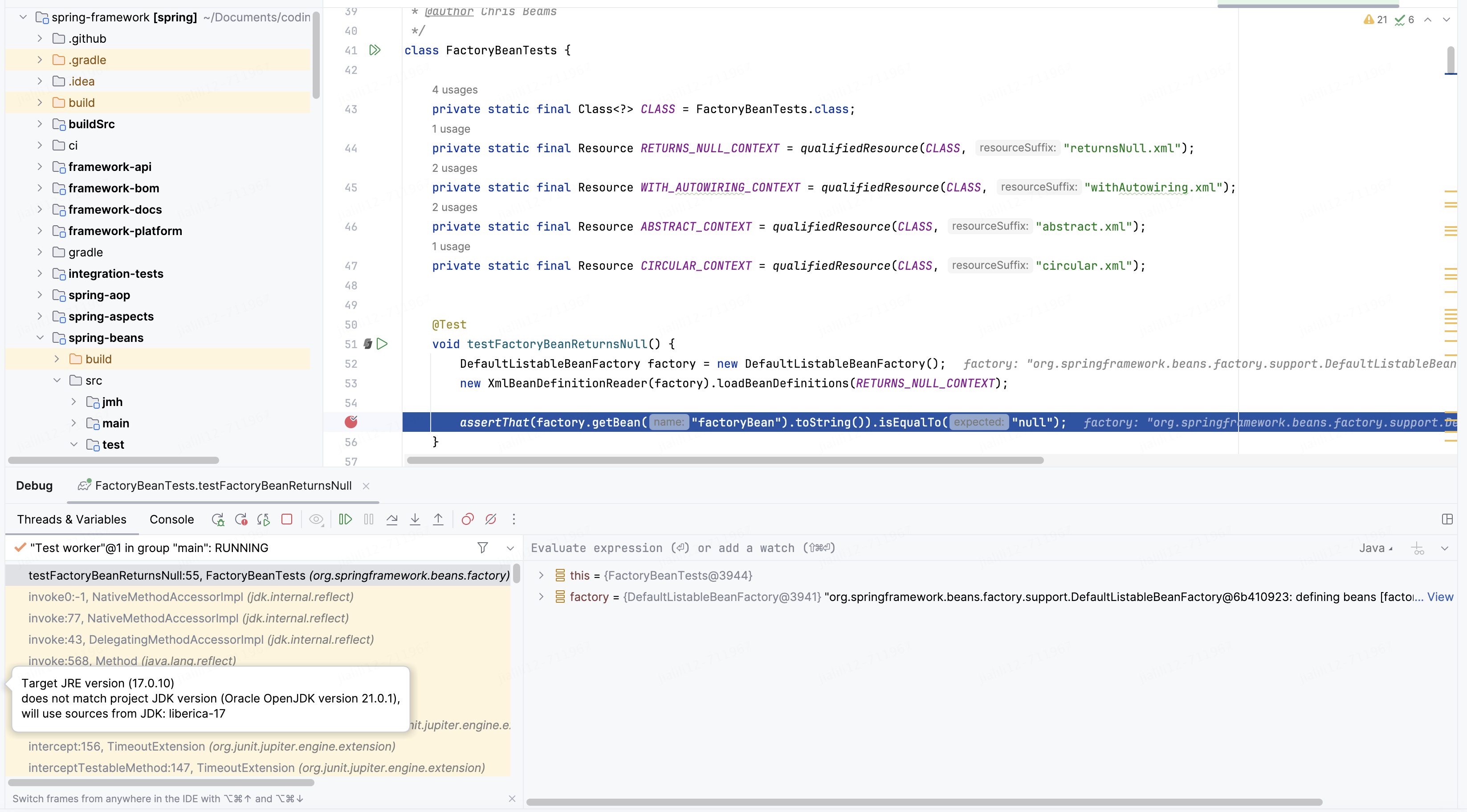
接下来正式进入源码阅读时间
下面要看的测试用例为:
org.springframework.beans.factory.FactoryBeanTests#testFactoryBeanReturnsNull,代码如下
@Test
void testFactoryBeanReturnsNull() {
DefaultListableBeanFactory factory = new DefaultListableBeanFactory();
new XmlBeanDefinitionReader(factory).loadBeanDefinitions(RETURNS_NULL_CONTEXT);
assertThat(factory.getBean("factoryBean").toString()).isEqualTo("null");
}
先假设如果是自己的系统要做一个类似的获取bean的功能的话我会怎么设计:
1.解析xml,生成bean
2.将生成的bean存到一个地方
3.为了获取方便,大概率我会写一个map,通过bean的id可以获取数据
以下是spring的类图
spring源码阅读之bean加载过程(一)
如果想要阅读源码,首先要选择版本,然后将源代码下载到本地,导入idea中,话不多说,直接看步骤吧
这里我选择5版本,
下载源码
默认是main分支,看想学习的分支,比如我切换到5版本,截图如下:
2.安装gradle
3.转换源码进idea
下载完成后可以看到有个文档叫import-into-idea.md,这里介绍了怎么将代码导进idea,不过对我这种英语不好的真的是费劲,可以参考https://github.com/coderbruis/JavaSourceCodeLearning/blob/master/note/Spring/%E6%B7%B1%E5%85%A5Spring%E6%BA%90%E7%A0%81%E7%B3%BB%E5%88%97%EF%BC%88%E4%B8%80%EF%BC%89%E2%80%94%E2%80%94%E5%9C%A8IDEA%E4%B8%AD%E6%9E%84%E5%BB%BASpring%E6%BA%90%E7%A0%81.md
查看spring与gradle的版本对应,目录:spring-framework/gradle/wrapper/gradle-wrapper.properties

最好是要保持版本一致,否则可能下面的命令执行报错
默认每次都会下载gradle,现改成本地的文件即可
编译spring-oxm(jdk8报错,后来改成jdk21可以了,网上有说11也可以,可以自行实验,本人没有验证过,刚好在本地有21版本,直接拿来用了),由于开发使用1.8所以我就没有改系统默认jdk版本,先导入idea,在idea里面操作了,最终编译成功,截图如下

可以看到spring源码现在不报错了

可以看到就像是我们自己的项目一样,可以看到提交记录和提交人等相关信息,也可以直接修改
spring源码已下载到本地了,我最想了解的是bean的加载过程,然后点到代码里可以看到测试用例非常全面,试运行了一下,确实可以运行截图如下

接下来正式进入源码阅读时间
下面要看的测试用例为:
org.springframework.beans.factory.FactoryBeanTests#testFactoryBeanReturnsNull,代码如下
@Test
void testFactoryBeanReturnsNull() {
DefaultListableBeanFactory factory = new DefaultListableBeanFactory();
new XmlBeanDefinitionReader(factory).loadBeanDefinitions(RETURNS_NULL_CONTEXT);
assertThat(factory.getBean("factoryBean").toString()).isEqualTo("null");
}
先假设如果是自己的系统要做一个类似的获取bean的功能的话我会怎么设计:
1.解析xml,生成bean
2.将生成的bean存到一个地方
3.为了获取方便,大概率我会写一个map,通过bean的id可以获取数据
以下是spring的类图
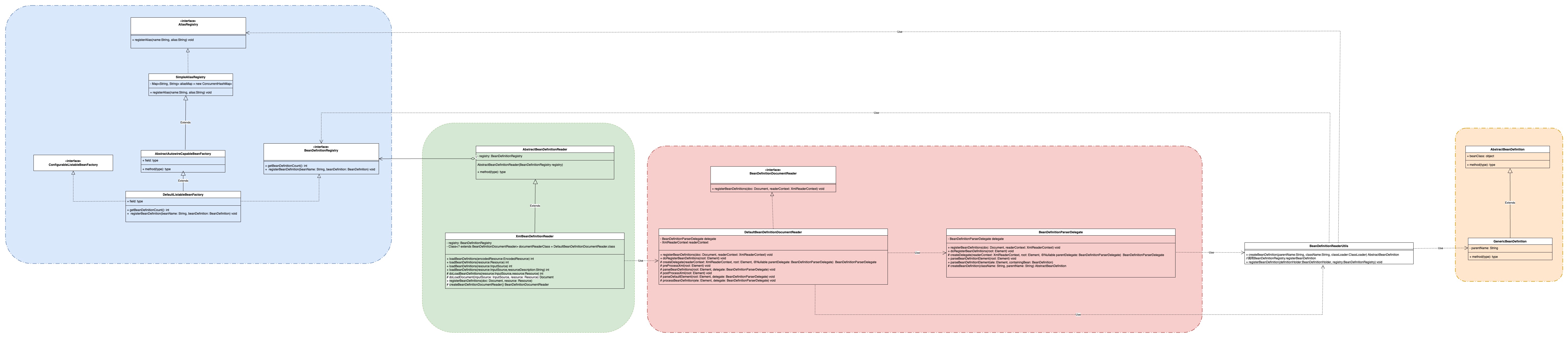
类图1
具体分析:
上图看起来足够复杂,仔细分析之后发现我们写的那几步都包含在里面而已
黄色:用来存储bean的实体,最上层的类为BeanDefinition,抽象类AbstractBeanDefinition,在本测试用例中使用的是工具类org.springframework.beans.factory.support.BeanDefinitionReaderUtils#createBeanDefinition生成的GenericBeanDefinition
public static AbstractBeanDefinition createBeanDefinition(@Nullable String parentName, @Nullable String className, @Nullable ClassLoader classLoader) throws ClassNotFoundException {
GenericBeanDefinition bd = new GenericBeanDefinition();
bd.setParentName(parentName);
if (className != null) {
if (classLoader != null) {
bd.setBeanClass(ClassUtils.forName(className, classLoader));
} else {
bd.setBeanClassName(className);
}
}
return bd;
}
粉色:主要功能就是从Document中解析出来各个bean及相应的attribute,properties等,解析完之后交给工具类生成BeanDefinition
主要代码如下:
public AbstractBeanDefinition parseBeanDefinitionElement(
Element ele, String beanName, @Nullable BeanDefinition containingBean) {
this.parseState.push(new BeanEntry(beanName));
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
try {
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
//设置bean的属性
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
parseMetaElements(ele, bd);
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
parseConstructorArgElements(ele, bd);
parsePropertyElements(ele, bd);
parseQualifierElements(ele, bd);
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
return bd;
}
catch (ClassNotFoundException ex) {
error("Bean class [" + className + "] not found", ele, ex);
}
catch (NoClassDefFoundError err) {
error("Class that bean class [" + className + "] depends on not found", ele, err);
}
catch (Throwable ex) {
error("Unexpected failure during bean definition parsing", ele, ex);
}
finally {
this.parseState.pop();
}
return null;
}
上面这段代码是类BeanDefinitionParserDelegate的,翻译过来就是BeanDefinition解析器代表,也就是说这个类主要负责从document解析为BeanDefinition,他有几个重载方法,可返回BeanDefinition,也可返回BeanDefinitionHolder,当然入参也可不同
DefaultBeanDefinitionDocumentReader获取到BeanDefinitionParserDelegate传过来的BeanDefinition后还可以进行装饰,装饰完再注册到registry中
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// Register the final decorated instance.
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// Send registration event.
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
工具类方法
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// Register aliases for bean name, if any.
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}
提到的registry就是在测试用例中new出来的DefaultListableBeanFactory,这个类实现了BeanDefinitionRegistry接口,也实现了AliasRegistry接口,注册的最重要的逻辑便是
//代码来自类org.springframework.beans.factory.support.DefaultListableBeanFactory#registerBeanDefinition
this.beanDefinitionMap.put(beanName, beanDefinition);
//代码来自类org.springframework.core.SimpleAliasRegistry
this.aliasMap.put(alias, name);
这样,后续使用时就可以通过DefaultListableBeanFactory提供的方法来获取bean的相关信息了
绿色:我觉得这部分的主要工作就是将factory给的resource数据转换成document,然后再交给粉色去解析,主要起到一个转换作用,XmlBeanDefinitionReader也有好几个重载方法,最终调的方法如下
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
Document doc = doLoadDocument(inputSource, resource);
int count = registerBeanDefinitions(doc, resource);
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + count + " bean definitions from " + resource);
}
return count;
}
}
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
int countBefore = getRegistry().getBeanDefinitionCount();
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}
蓝色:这部分的主要功能我个人感觉就是bean的入口和出口,factory获取resource资源,交给绿色部分,经过前面几个颜色的处理最后将BeanDefinition注册回factory,这样就可以通过factory进行相关操作了
模块与模块之前都是通过接口进行交互,这样即使入口不使用xml,也可以复用后面的逻辑,这样保证了每个类的单一职责,虽然看着复杂,但是确比较合理
图中有一些type method这种的是占用地方用的,因为我只看了这一点代码,并不了解全部,所以后面再看到相关的信息时会进行补充
接下来就是classPathXmlApplicationContext的测试用例,spring提供的代码如下
@Test
void singleConfigLocation() {
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext(FQ_SIMPLE_CONTEXT);
assertThat(ctx.containsBean("someMessageSource")).isTrue();
ctx.close();
}
xml文件如下:
<beans>
<bean id="someMessageSource" name="yourMessageSource"
class="org.springframework.context.support.StaticMessageSource"/>
<bean class="org.springframework.context.support.ClassPathXmlApplicationContext" lazy-init="true">
<constructor-arg value="someNonExistentFile.xml"/>
</bean>
</beans>
正常的思路是那个测试用例的数据可以完全复用,再加上一些解析路径的功能,再将map里的数据生成bean就差不多了(单说解析Bean这块)
我们先来看一下ClassPathXmlApplicationContext的类继承结构
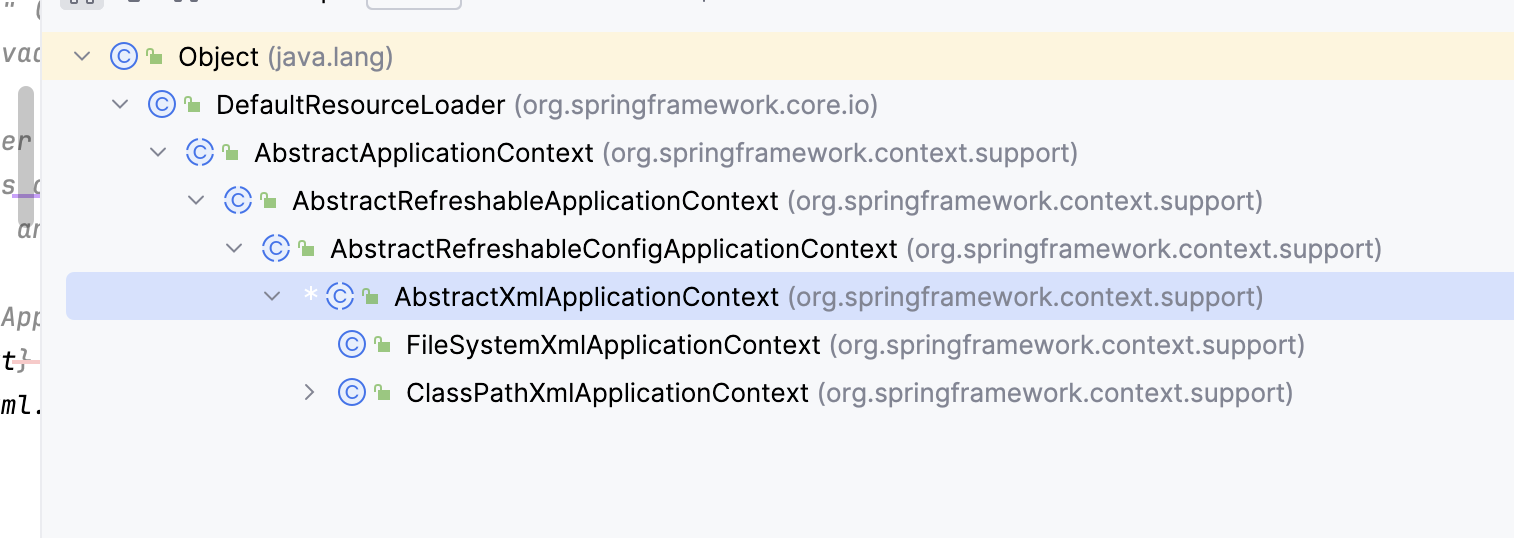
可以看到他的本质就是ResourceLoader,即用来解析数据用的,下面我们来看下他的初始化过程
public ClassPathXmlApplicationContext(
String[] configLocations, boolean refresh, @Nullable ApplicationContext parent)
throws BeansException {
super(parent);
//这行是解析所给的路径的,比如会解析${}对应到项目中目录位置
setConfigLocations(configLocations);
//这里传的refresh是true,会在这里共用上面测试用例部分
if (refresh) {
refresh();
}
}
通过上面的注解可以看到先是解析文件,然后调用refresh
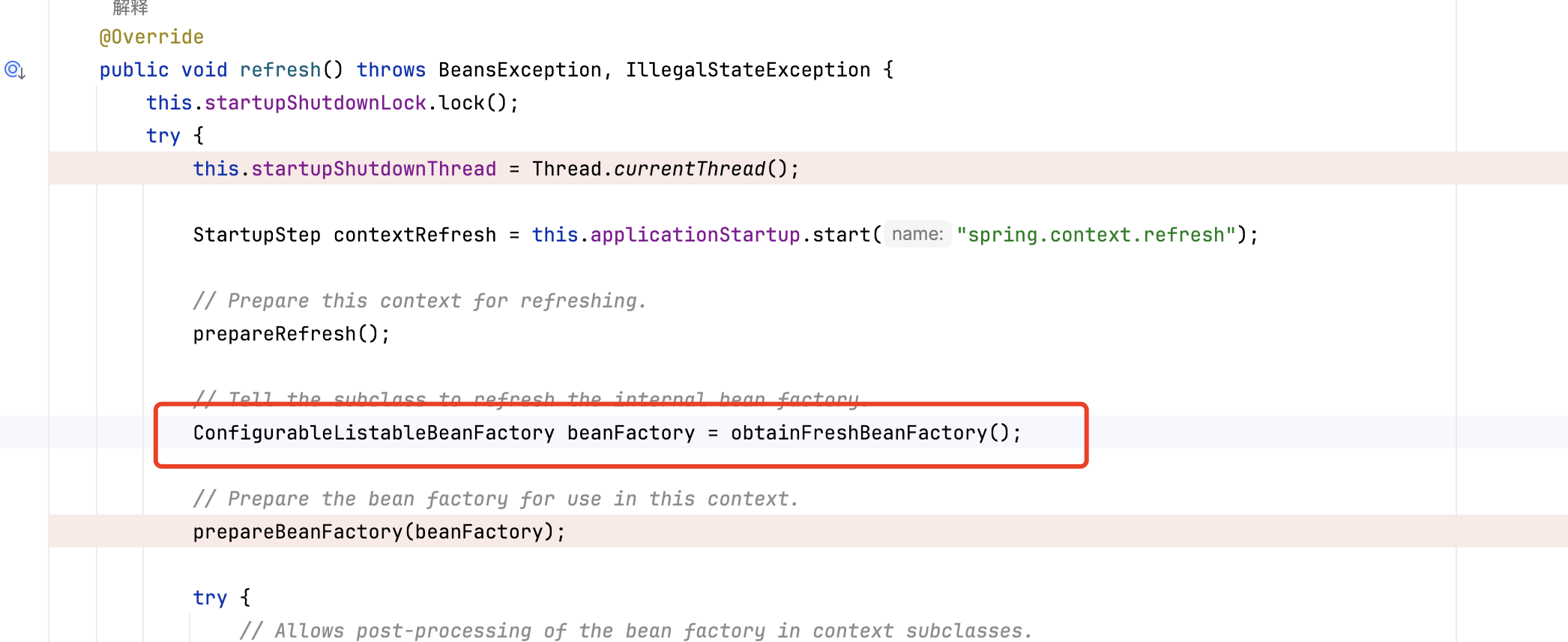
refresh方法里面有一行获取BeanFactory的,可以看到获取到的是ConfigurableListableBeanFactory,
而obtainFreshBeanFactory()方法里有下面一行,发现最终用的BeanFactory为DefaultListableBeanFactory,是不是有点眼熟了,没错,就是第一个测试用例中使用的,那后面的过程就是一致的了,下图中画出来的两句跟第一个测试用例的两句表达的是一个意思,obtainFreshBeanFactory()方法执行完之后在factory的beanDefinitionMap里已经存了xml里有的数据,即第一个类图里面的流程都run了一遍
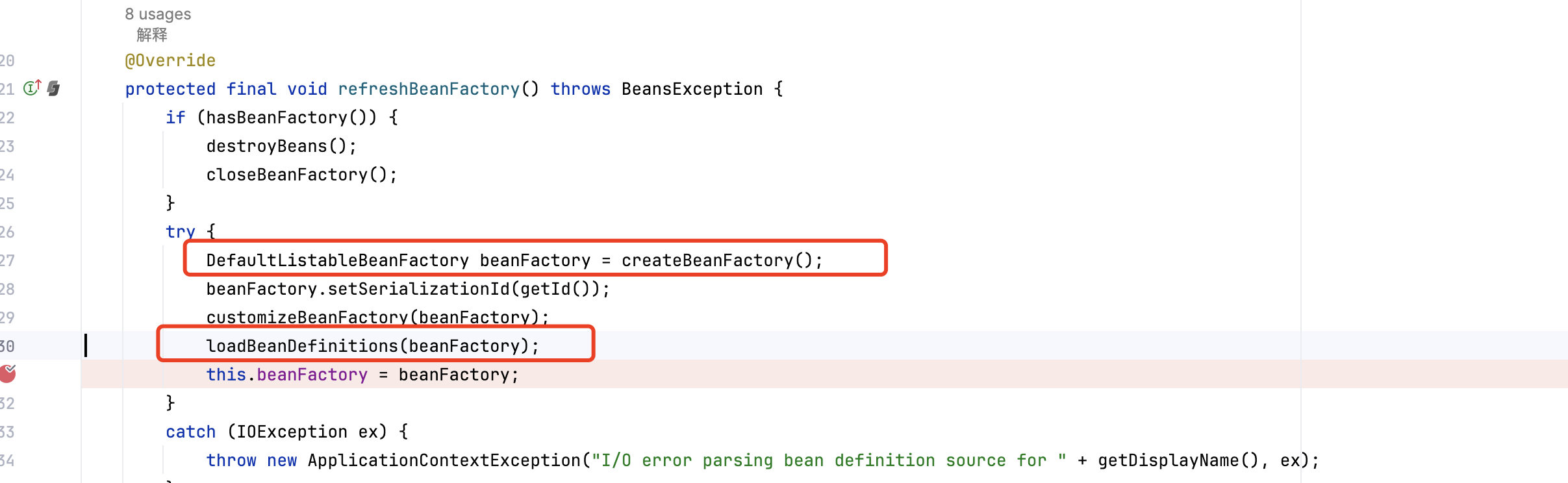
整个refresh是初始化的核心方法,我将最关键的代码粘出来,
org.springframework.context.support.AbstractApplicationContext#refresh
@Override
public void refresh() throws BeansException, IllegalStateException {
// 这中间会有一些别的操作,本次测试用例并未使用到,全都去掉了,占用篇幅太多
try {
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);//初始化操作
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);//生成bean方法
// Last step: publish corresponding event.
finishRefresh();
}
}
如上备注所示,最关键的方法为,代码如下:
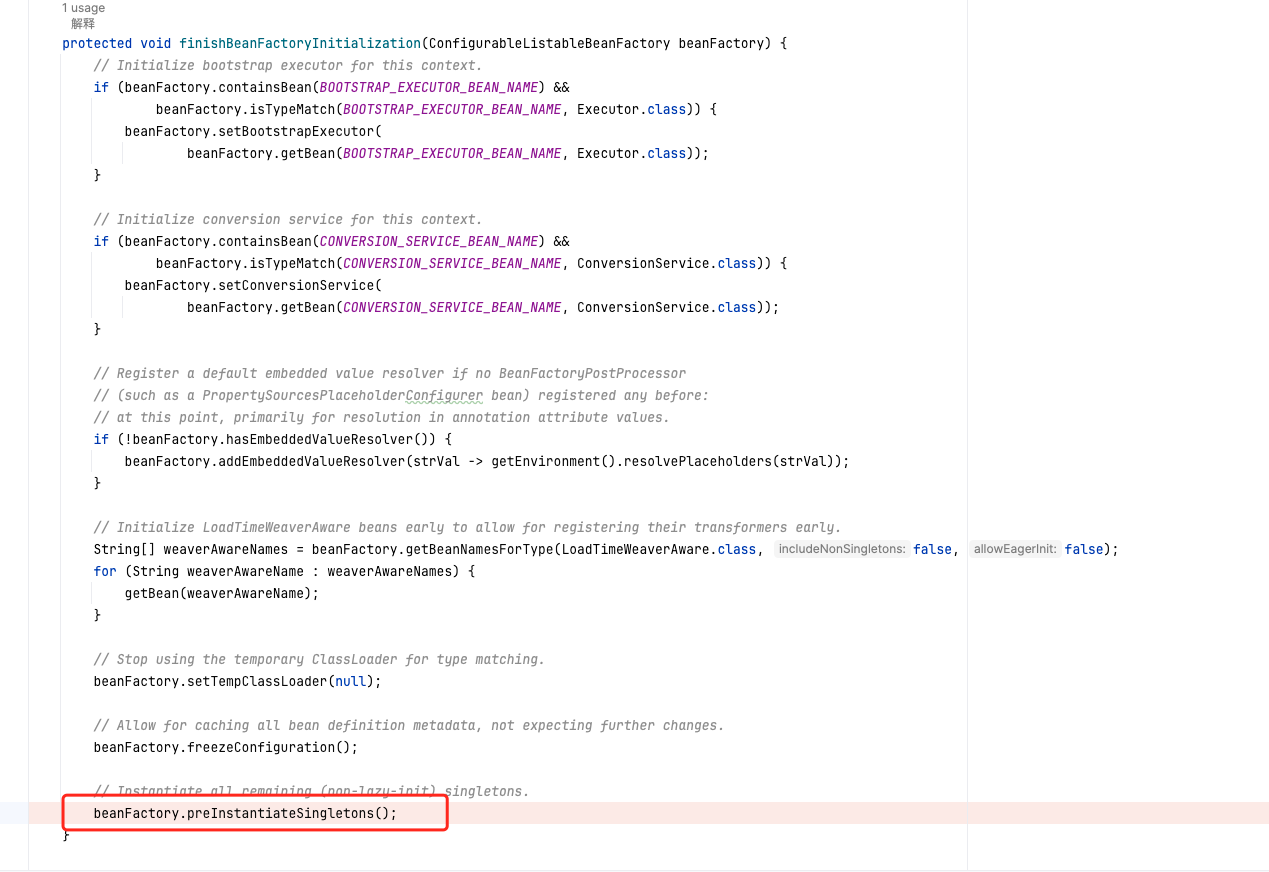
这个方法调的是beanFactory.preInstantiateSingletons方法
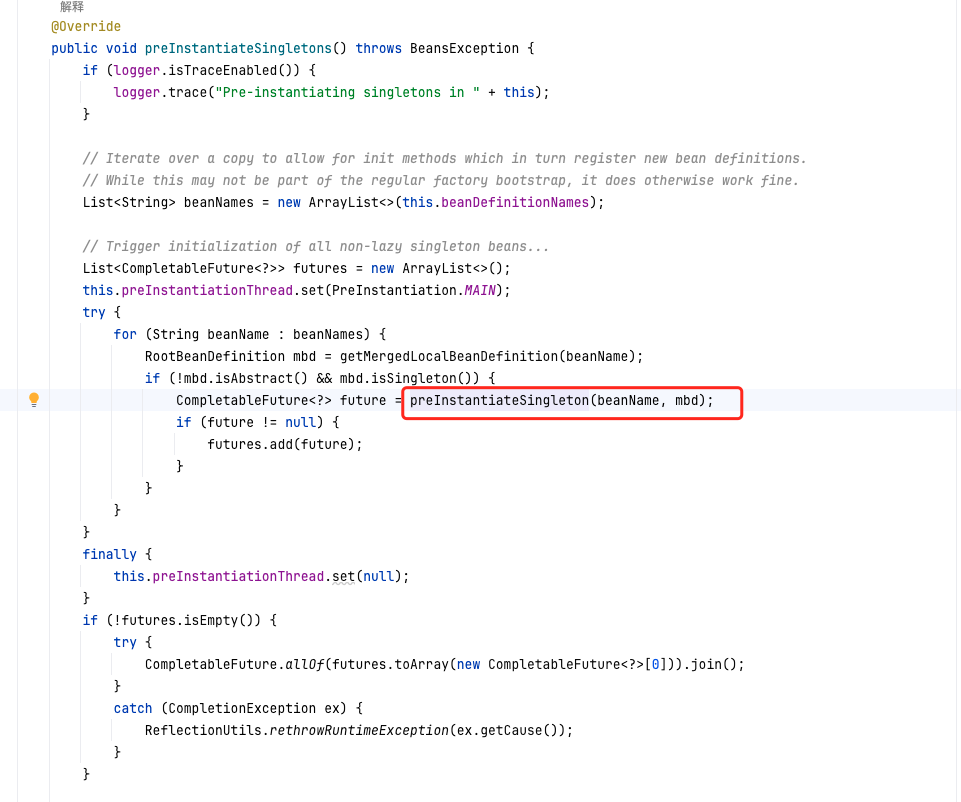
其中,preInstantiateSingletons方法上两行有一个方法,getMergeLocalBeanDefinition(beanName);这里是把类图1初始化生成的GenericBeanDefinition转化成RootBeanDefinition,后续操作都是用RootBeanDefinition,并将beanName和新生成了RootBeanDefinition放入mergedBeanDefinitions
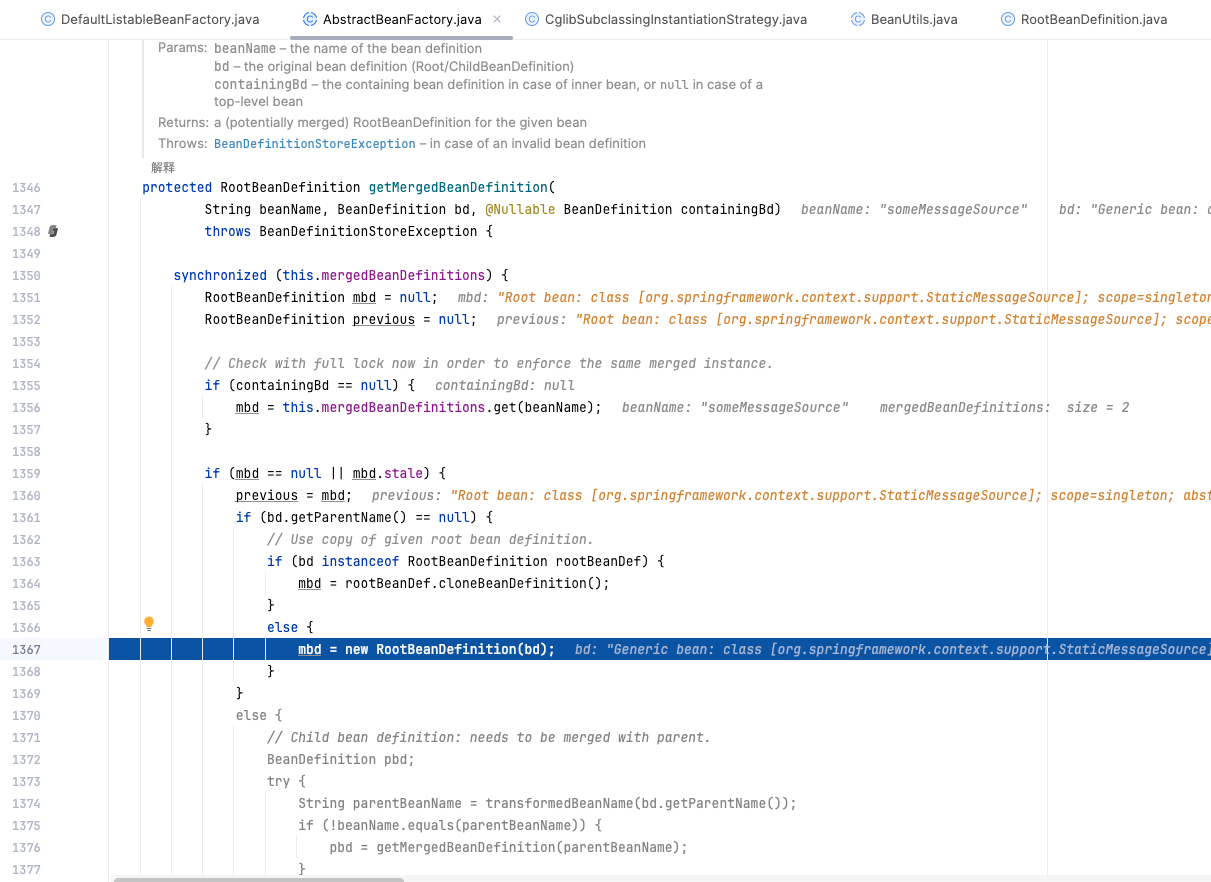

接下来是

方法如下:该方法在DefaultListableBeanFactory中

getBean方法是AbstractBeanFactory中,代码如下:

这个方法调用了自己类的doGetBean方法,在方法内部调用了createBean,createBean是个abstract方法,调用的是AbstractAutowireCapableBeanFactory#createBean(java.lang.String, org.springframework.beans.factory.support.RootBeanDefinition, java.lang.Object[])
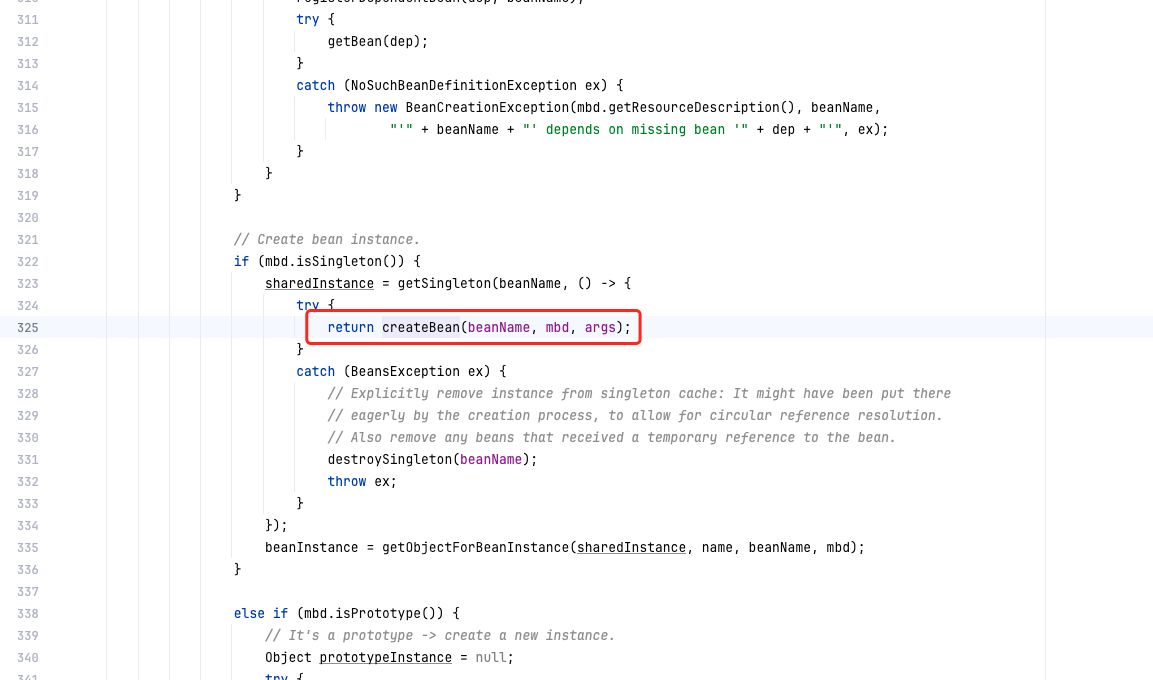
调用如下:
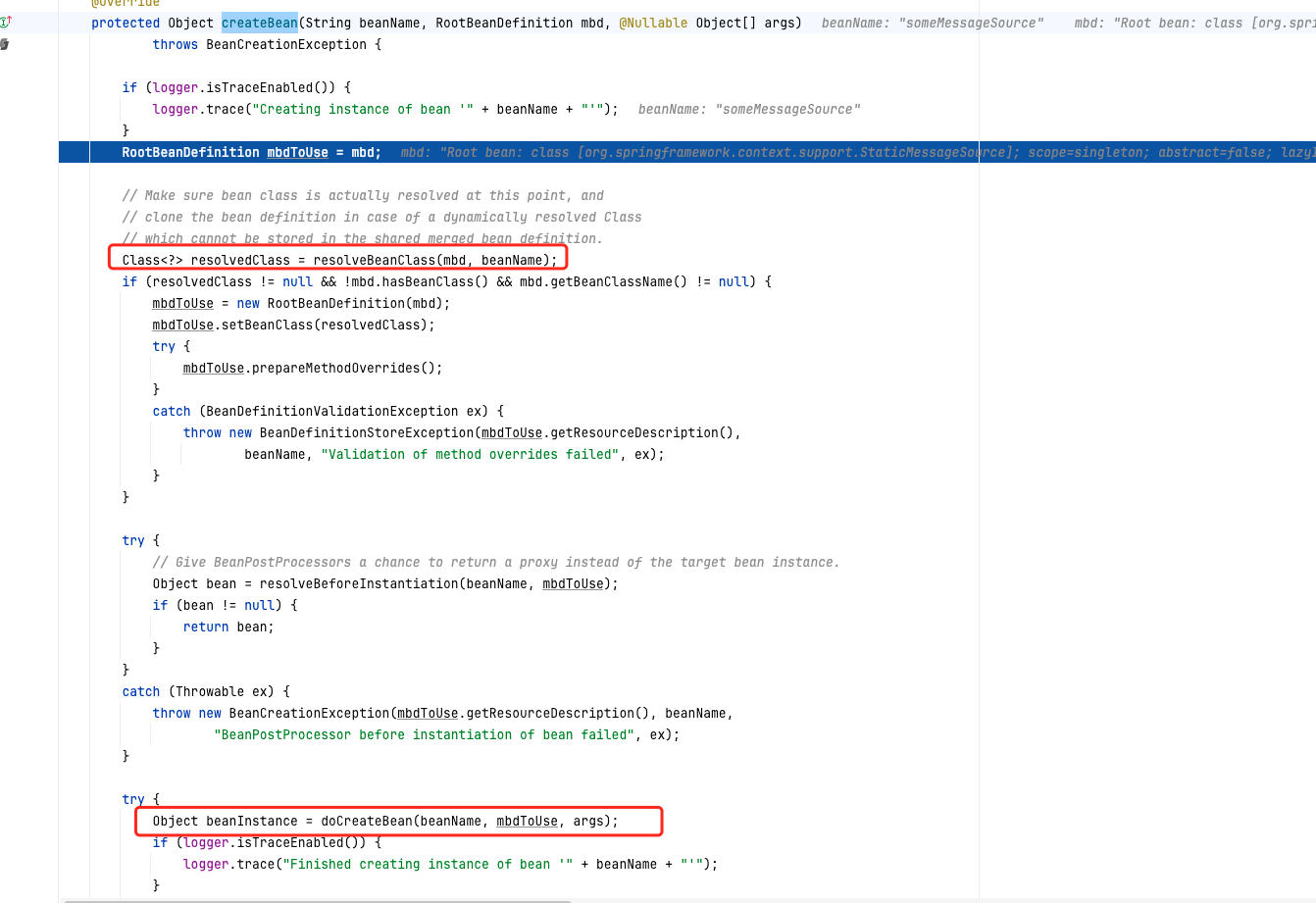

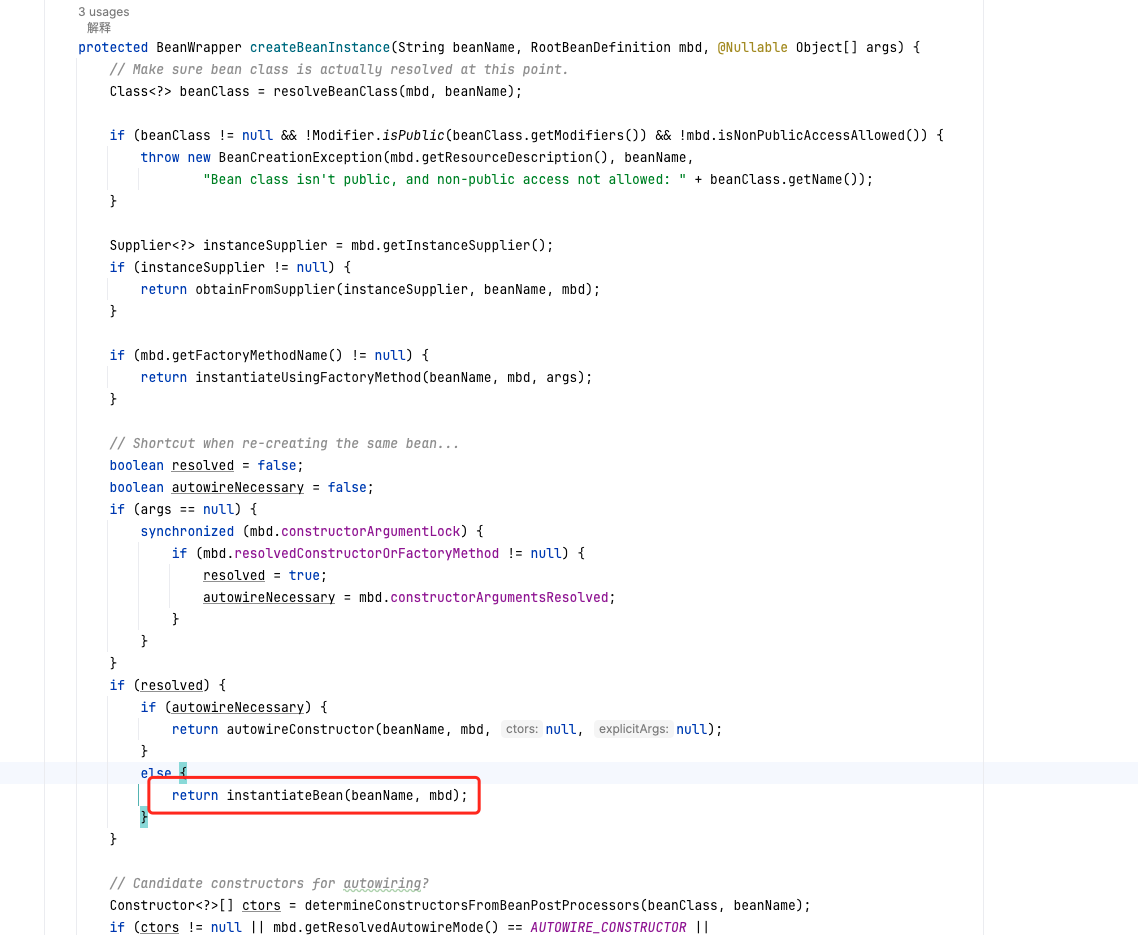
最终调到这里完成了bean的生成

生成完bean之后会设置一些RootBeanDefinition的状态,还有类型等
将beanName放入到registeredSingletons中
将beanName,获取到的bean放入singletonObjects

到此,创建bean的基本主流程就结束了
以下是spring的类图
类图2
通过类图2可以看到比类图1增加了紫色部分,玫粉色部分,蓝色部分也有所增加,以及最右边的橘色部分也增加了一个类
紫色部分:ClassPathXmlApplicationContext的组成,他主要负责解析xml路径识别,以及构造beanFactory,然后通过factory生成BeanDefinition,以及初始化bean
蓝色增长部分:初始化bean的部分,由DefaultListableBeanFactory#instantiateSingleton开始向AbstractBeanFactory类的方法转移,最终调用抽象方法createBean,向子类转移AbstractAutowireCapableBeanFactory#createBean(java.lang.String, org.springframework.beans.factory.support.RootBeanDefinition, java.lang.Object[])
并最终调用新增的玫粉色部分生成bean,并将生成的bean存入DefaultSingletonBeanRegistry中的属性中
玫粉色部分:即生成bean的终端,最终生成bean的地方
以上都是个人观点哈,如果有不正确的地方希望各位批评指正!
下期打算为各位介绍:
1.注解的类的生成过程
2.循环注入
3.抽象类能否加载






