



一 用例生成实践效果
在组内的日常工作安排中,持续优化测试技术、提高测试效率始终是重点任务。近期,我们在探索实践使用大模型生成测试用例,期望能够借助其强大的自然语言处理能力,自动化地生成更全面和高质量的测试用例。
当前,公司已经普及使用JoyCoder,我们可以拷贝相关需求及设计文档的信息给到JoyCoder,让其生成测试用例,但在使用过程中有以下痛点:
1)仍需要多步人工操作:如复制粘贴文档,编写提示词,拷贝结果,保存用例等
2)响应时间久,结果不稳定:当需求或设计文档内容较大时,提示词太长或超出token限制
因此,我探索了基于Langchain与公司现有平台使测试用例可以自动、快速、稳定生成的方法,效果如下:
| 用例生成效果对比 | 使用JoyCoder | 基于Langchain自研 |
|---|---|---|
| 生成时长 (针对项目--文档内容较多) | ·10~20分钟左右,需要多次人工操作 (先会有一个提示:根据您提供的需求文档,下面是一个Markdown格式的测试用例示例。由于文档内容比较多,我将提供一个概括性的测试用例模板,您可以根据实际需求进一步细化每个步骤。) ·内容太多时,报错:The maximum default token limit has been reached、UNKNOWN ERROR:Request timed out. This may be due to the server being overloaded,需要人工尝试输入多少内容合适 | ·5分钟左右自动生成 (通过摘要生成全部测试点后,再通过向量搜索的方式生成需要细化的用例) ·内容太多时,可根据token文本切割后再提供给大模型 |
| 生成时长 (针对普通小需求) | 差别不大,1~5分钟 | |
| 准确度 | 依赖提示词内容,差别不大,但自研时更方便给优化好的提示词固化下来 | |
(什么是LangChain? 它是一个开源框架,用于构建基于大型语言模型(LLM)的应用程序。LLM 是基于大量数据预先训练的大型深度学习模型,可以生成对用户查询的响应,例如回答问题或根据基于文本的提示创建图像。LangChain 提供各种工具和抽象,以提高模型生成的信息的定制性、准确性和相关性。例如,开发人员可以使用 LangChain 组件来构建新的提示链或自定义现有模板。LangChain 还包括一些组件,可让 LLM 无需重新训练即可访问新的数据集。)
二 细节介绍
1 基于Langchain的测试用例生成方案
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 方案1:将全部产品需求和研发设计文档给到大模型,自动生成用例 | 用例内容相对准确 | 不支持特大文档,容易超出token限制 | 普通规模的需求及设计 |
| 方案2:将全部产品需求和研发设计文档进行摘要后,将摘要信息给到大模型,自动生成用例 | 进行摘要后无需担心token问题 | 用例内容不准确,大部分都只能是概况性的点 | 特大规模的需求及设计 |
| 方案3:将全部产品需求和研发设计文档存入向量数据库,通过搜索相似内容,自动生成某一部分的测试用例 | 用例内容更聚焦 无需担心token问题 | 不是全面的用例 | 仅对需求及设计中的某一部分进行用例生成 |
因3种方案使用场景不同,优缺点也可互补,故当前我将3种方式都实现了,提供大家按需调用。
2 实现细节
2.1 整体流程
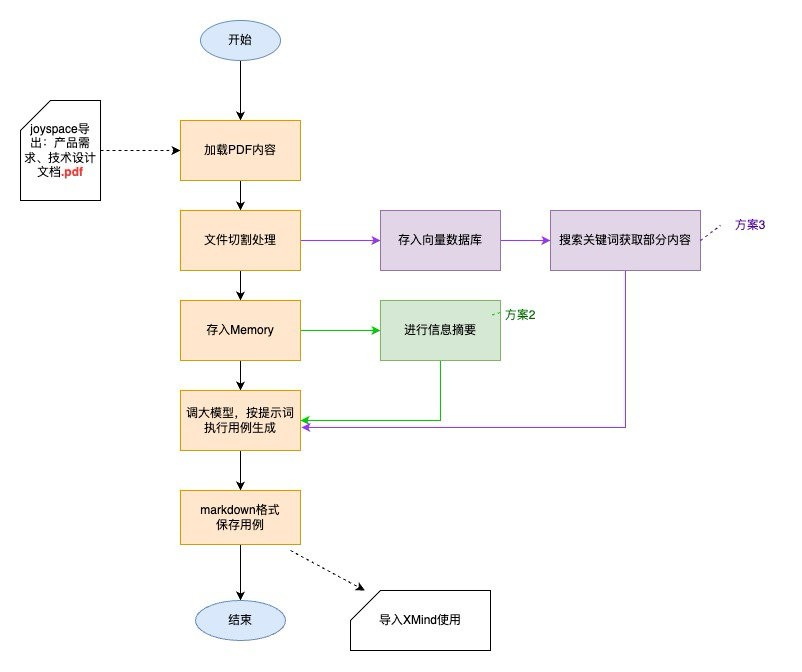
2.2 技术细节说明
- 文件切割处理:为了防止一次传入内容过多,容易导致大模型响应时间久或超出token限制,利用Langchain的文本切割器,将文件分为各个小文本的列表形式
- Memory的使用:大多数 LLM 模型都有一个会话接口,当我们使用接口调用大模型能力时,每一次的调用都是新的一次会话。如果我们想和大模型进行多轮的对话,而不必每次重复之前的上下文时,就需要一个Memory来记忆我们之前的对话内容。Memory就是这样的一个模块,来帮助开发者可以快速的构建自己的应用“记忆”。本次我使用Langchain的ConversationBufferMemory与ConversationSummaryBufferMemory来实现,将需求文档和设计文档内容直接存入Memory,可减少与大模型问答的次数(减少大模型网关调用次数),提高整体用例文件生成的速度。ConversationSummaryBufferMemory主要是用在提取“摘要”信息的部分,它可以将将需求文档和设计文档内容进行归纳性总结后,再传给大模型
- 向量数据库:利用公司已有的向量数据库测试环境Vearch,将文件存入。 在创建数据表时,需要了解向量数据库的检索模型及其对应的参数,目前支持六种类型,IVFPQ,HNSW,GPU,IVFFLAT,BINARYIVF,FLAT(详细区别和参数可点此链接),目前我选择了较为基础的IVFFLAT--基于量化的索引,后续如果数据量太大或者需要处理图数据时再优化。另外Langchain也有很方便的vearch存储和查询的方法可以使用
2.3 代码框架及部分代码展示
代码框架:

代码示例:
def case_gen(prd_file_path, tdd_file_path, input_prompt, case_name):
"""
用例生成的方法
参数:
prd_file_path - prd文档路径
tdd_file_path - 技术设计文档路径
case_name - 待生成的测试用例名称
"""
# 解析需求、设计相关文档, 输出的是document列表
prd_file = PDFParse(prd_file_path).load_pymupdf_split()
tdd_file = PDFParse(tdd_file_path).load_pymupdf_split()
empty_case = FilePath.read_file(FilePath.empty_case)
# 将需求、设计相关文档设置给memory作为llm的记忆信息
prompt = ChatPromptTemplate.from_messages(
[
SystemMessage(
content="You are a chatbot having a conversation with a human."
), # The persistent system prompt
MessagesPlaceholder(
variable_name="chat_history"
), # Where the memory will be stored.
HumanMessagePromptTemplate.from_template(
"{human_input}"
), # Where the human input will injected
]
)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
for prd in prd_file:
memory.save_context({"input": prd.page_content}, {"output": "这是一段需求文档,后续输出测试用例需要"})
for tdd in tdd_file:
memory.save_context({"input": tdd.page_content}, {"output": "这是一段技术设计文档,后续输出测试用例需要"})
# 调大模型生成测试用例
llm = LLMFactory.get_openai_factory().get_chat_llm()
human_input = "作为软件测试开发专家,请根据以上的产品需求及技术设计信息," + input_prompt + ",以markdown格式输出测试用例,用例模版是" + empty_case
chain = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory,
)
output_raw = chain.invoke({'human_input': human_input})
# 保存输出的用例内容,markdown格式
file_path = FilePath.out_file + case_name + ".md"
with open(file_path, 'w') as file:
file.write(output_raw.get('text')) def case_gen_by_vector(prd_file_path, tdd_file_path, input_prompt, table_name, case_name):
"""
!!!当文本超级大时,防止token不够,通过向量数据库,搜出某一部分的内容,生成局部的测试用例,细节更准确一些!!!
参数:
prd_file_path - prd文档路径
tdd_file_path - 技术设计文档路径
table_name - 向量数据库的表名,分业务存储,一般使用业务英文唯一标识的简称
case_name - 待生成的测试用例名称
"""
# 解析需求、设计相关文档, 输出的是document列表
prd_file = PDFParse(prd_file_path).load_pymupdf_split()
tdd_file = PDFParse(tdd_file_path).load_pymupdf_split()
empty_case = FilePath.read_file(FilePath.empty_case)
# 把文档存入向量数据库
docs = prd_file + tdd_file
embedding_model = LLMFactory.get_openai_factory().get_embedding()
router_url = ConfigParse(FilePath.config_file_path).get_vearch_router_server()
vearch_cluster = Vearch.from_documents(
docs,
embedding_model,
path_or_url=router_url,
db_name="y_test_qa",
table_name=table_name,
flag=1,
)
# 从向量数据库搜索相关内容
docs = vearch_cluster.similarity_search(query=input_prompt, k=1)
content = docs[0].page_content
# 使用向量查询的相关信息给大模型生成用例
prompt_template = "作为软件测试开发专家,请根据产品需求技术设计中{input_prompt}的相关信息:{content},以markdown格式输出测试用例,用例模版是:{empty_case}"
prompt = PromptTemplate(
input_variables=["input_prompt", "content", "empty_case"],
template=prompt_template
)
llm = LLMFactory.get_openai_factory().get_chat_llm()
chain = LLMChain(
llm=llm,
prompt=prompt,
verbose=True
)
output_raw = chain.invoke(
{'input_prompt': input_prompt, 'content': content, 'empty_case': empty_case})
# 保存输出的用例内容,markdown格式
file_path = FilePath.out_file + case_name + ".md"
with open(file_path, 'w') as file:
file.write(output_raw.get('text'))三 效果展示
3.1 实际运用到需求/项目的效果
用例生成后是否真的能帮助我们节省用例设计的时间,是大家重点关注的,因此我随机在一个小型需求中进行了实验,此需求的PRD文档总字数2363,设计文档总字数158(因大部分是流程图),结果如下:
| 用例设计环节,测试时间(人日)占用效果分析 | 可自动生成用例之前 | 可自动生成用例之后 |
|---|---|---|
| 分析需求&理解技术设计 | 0.5 | 0.25 |
| 与产研确认细节 | 0.25 | 0.25 |
| 设计及编写用例 | 1(39例) | 0.5(45例=25例自动生成+20例人工修正/补充) |
| 评审及用例差缺补漏 | 0.5 | 0.25 |
| 总计(效率提升50%) | 2.5人日 | 1.25人日 |
本次利用大模型自动生成用例的优缺点:
优势:
- 全面快速的进行了用例的逻辑点划分,协助测试分析理解需求及设计
- 降低编写测试用例的时间,人工只需要进行内容确认和细节调整
- 用例内容更加全面丰富,在用例评审时,待补充的点变少了,且可以有效防止漏测
- 如测试人员仅负责一部分功能的测试,也可通过向量数据库搜索的形式,聚焦部分功能的生成
劣势:
- 暂时没实现对流程图的理解,当文本描述较少时,生成内容有偏差
- 对于有丰富经验的测试人员,自动生成用例的思路可能与自己习惯的思路不一致,需要自己再调整或适应
四 待解决问题及后续计划
- 对于pdf中的流程图(图片形式),实现了文字提取识别(langchain pdf相关的方法支持了ocr识别),后续需要找到更适合解决图内容的解析、检索的方式。
- 生成用例只是测试提效的一小部分,后续需要尝试将大模型应用与日常测试过程,目前的想法有针对diff代码和服务器日志的分析来自动定位缺陷、基于模型驱动测试结合知识图谱实现的自动化测试等方向。






