



1、大模型背景
自从22年底OpenAI发布chartGPT以后,由于其惊人的自然语言理解和生成能力,一下子就引起全社会大范围的关注,国内许多AI大佬纷纷踏上这班车,推出各自的AI产品,整个2023年是AI迸发的一年,这一系列AI产品在2023年里反复冲刷着人们的认知。AI产品带动了大语言模型成为了时下热点,短时间内,各自AI聊天助手出现在了大家的视野里。
目前市面上,GPT4.0turbo、智谱清言GLM4、阿里Qwen-Max、百度文心一言4.0,最近马斯克旗下的大模型公司xAI开源的grok(3140亿参数),都是大语言模型,包括前段时间火爆全网的Sora大模型,其设计灵感也是来自于大语言模型。
2、大语言模型
2.1 概述
大语言模型(LLM,Large Language Model)是用于处理自然语言的模型,给模型一些文本输入,它可以返回相应的输出,例如文本分类、文本总结、机器翻译等。它可以理解和生成自然语言文本。在语言理解方面,大模型能够理解自然语言中的实体、关系和逻辑,并从中提取出关键信息。其次,在语言生成方面,大模型能够根据预先设定的上下文和语境,生成自然流畅的语言表达。此外,大模型还能够进行自然语言推理,从文本中推断出未知信息。
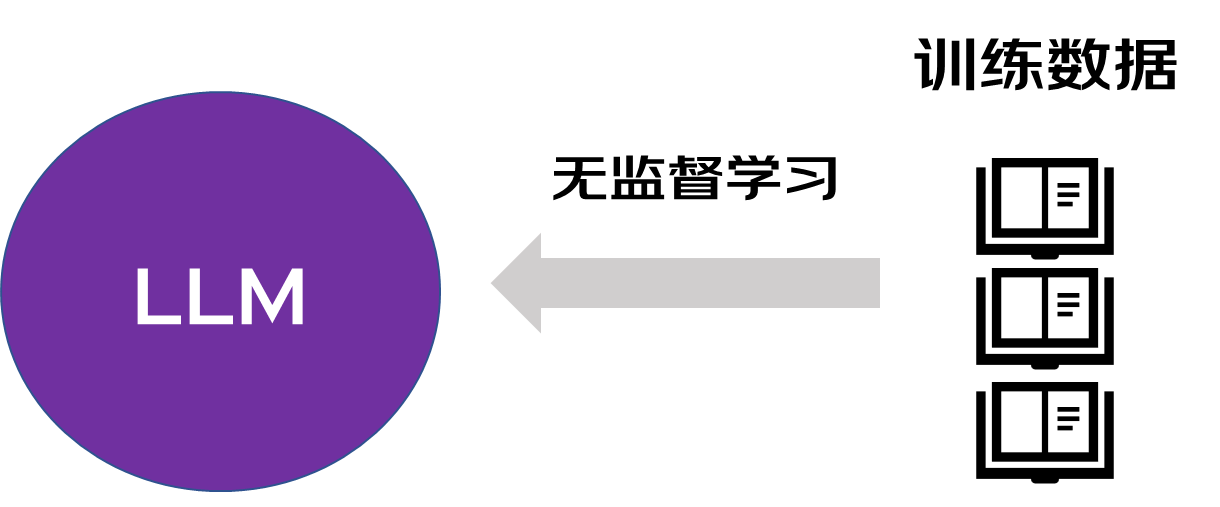
大语言模型需要通过大量文本数据进行无监督学习,以GPT3为例,它的训练数据包含多个互联网文本语料库,包括各种文章,论坛,论文等,一共有700多GB。
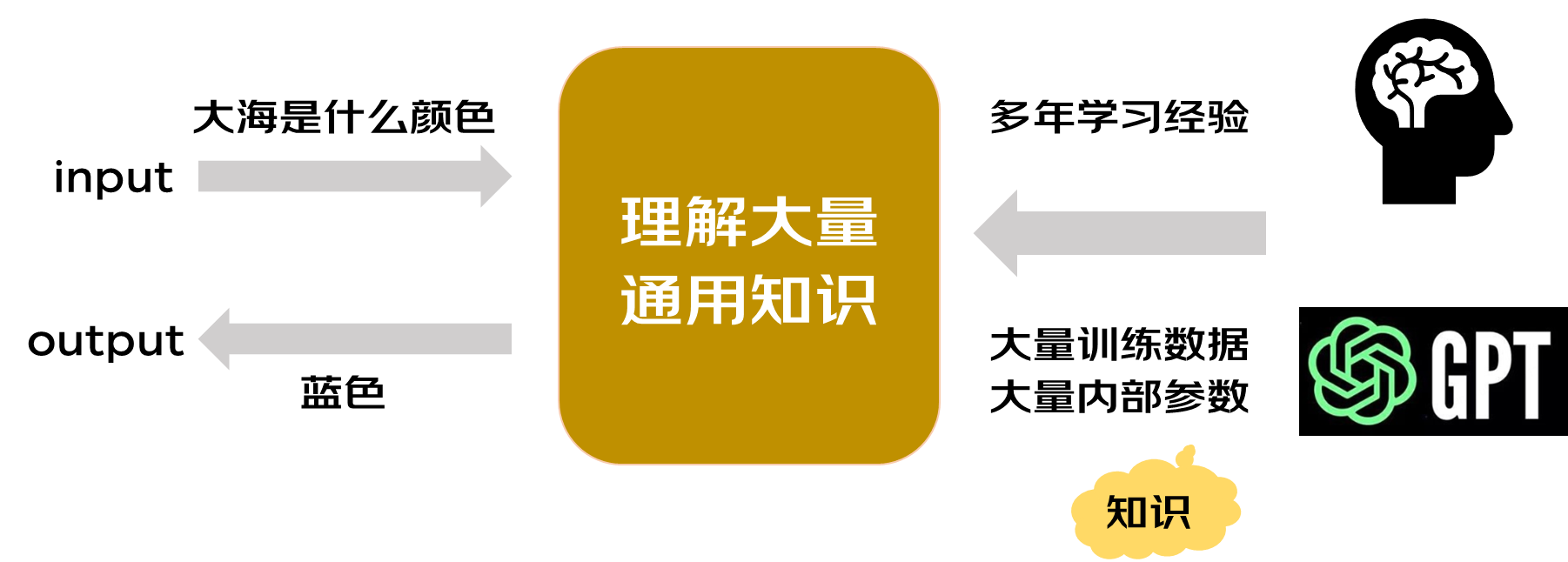
其实模型就类似人脑,你给他投喂的数据越多,它的知识库就越丰富。从我们出生以来,我们的父母,老师等人给我们传递的知识就等同于给大模型投递大量的训练数据,去训练模型内部大量的参数,参数可以理解为通过数据学习到的知识,它决定了模型根据输入得到的行为结果是否准确。往往用更多的数据和算力训练更多的参数可以得到更好的效果。当模型拥有了海量的训练文本,模型能够更好的发现文本信息中的规律,从而了解文本中上下文的关系,从而更好的理解文本的含义,形成更准确的预测。
2.2 实现原理

作为一种生成模型,LLM是通过文本输入来预测概率最高的下一个Token来实现文本生成的,就是说他不是一次性输出一句话,而是为以Token基本单元进行预测输出的。
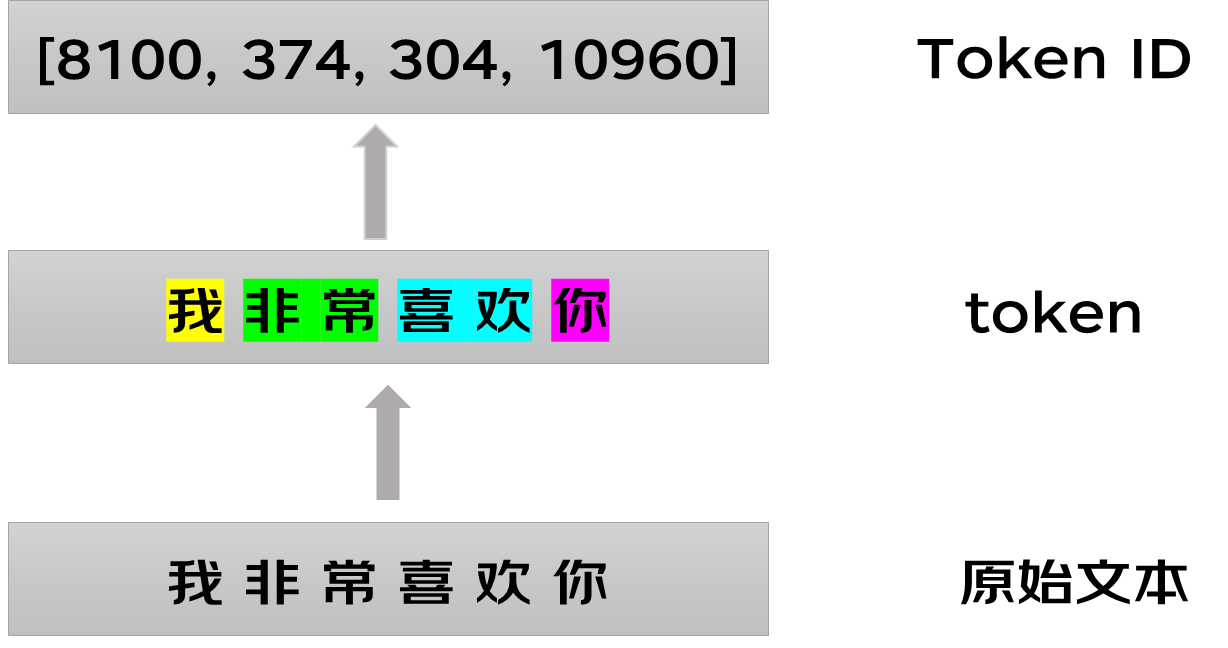
Token:在机器学习领域、NLP领域、文生图等领域,机器读懂词汇和语句是通过 Token (词元)来进行的。Token是语言类模型中表示文本的不可拆分的最小语义单位
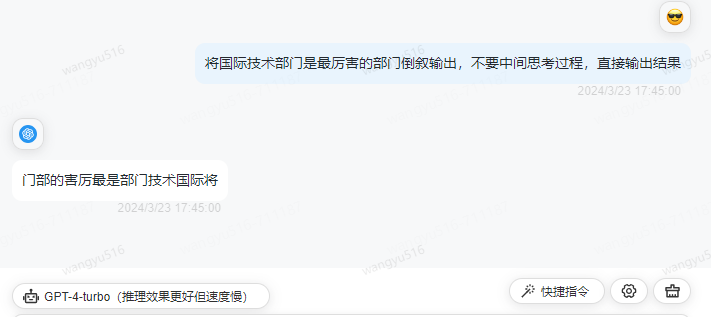
这个例子可以看出,LLM是基于词元为基本单位进行预测输出的。根据语境来看,词元可能是一个字,也可能是一个词。那么模型是如何得到各个词元出现的概率的呢?LLM的实现原理基本上离不开Transformer架构实现的。文本领域的大模型都是基于它实现的。
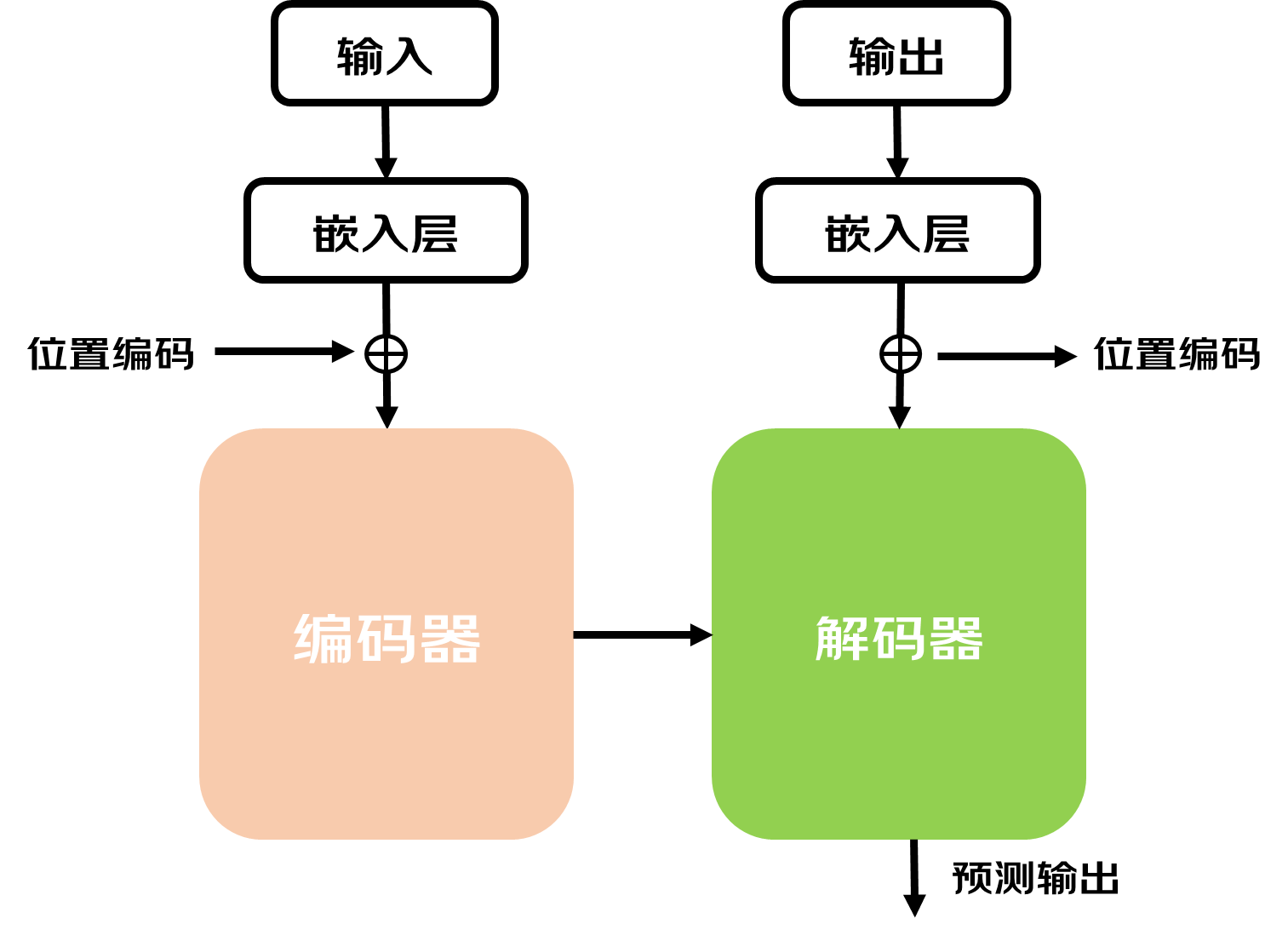
Transformer由两个核心部分组成:编码器和解码器。假设我们现在要做一个翻译的任务。在进入编码器之前,首先我们需要知道输入文本序列中的所有Token信息,因为计算机内部是无法存储字符的,每个Token会用一个整数表示,叫做tokenID。
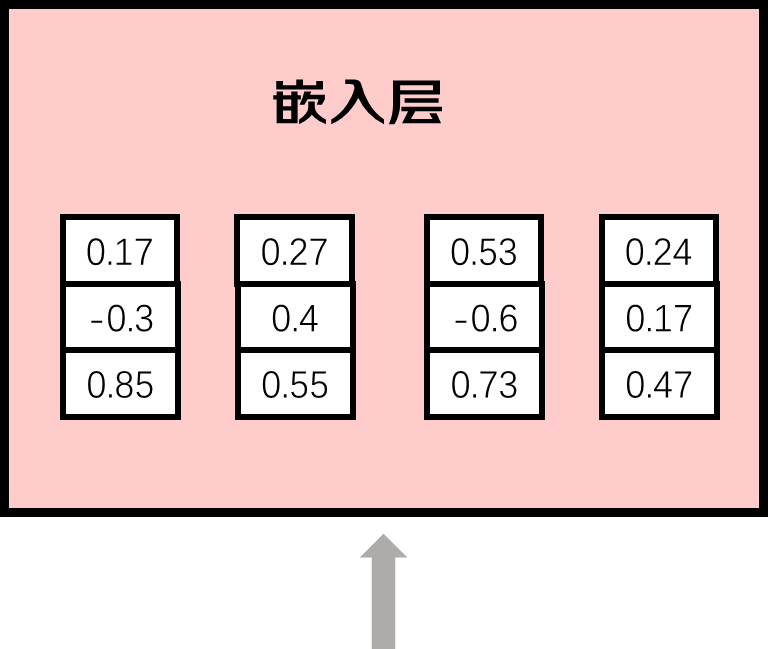
有了数字表示的输入文本后,再把它传入嵌入层,将其用向量表示,向量的长度可以非常长,为什么要用一串数字表示各个token呢,一串数字能表达的含义肯定是大于一个数字,因为一串数字可以在不同维度去表示语法以及语义信息。
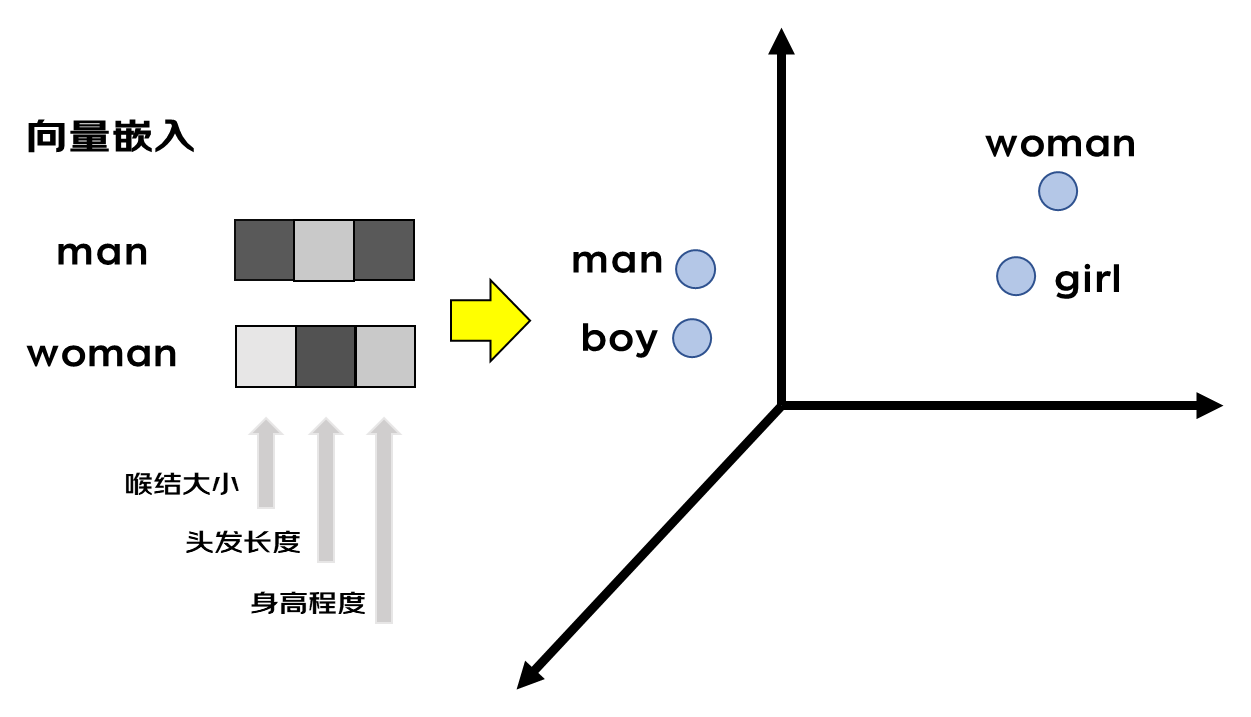
例如男人和女人两个单词man和woman,都描述人类,但是性别是相反的,如果仅仅用一个数字表示,它们之间的距离改大还是小呢。但是如果有多个数字,我们就可以从多个维度去表示它们,比如可以将其表示为喉结大小、头发长度、身高程度三个维度,man的喉结和身高程占比大,从而数字大,对应的头发长度小,对应的数字小,数字确定以后,不同的词在这个三维的向量空间里面都会有属于他们的位置。意思相近的词在这个多维度的向量空间里面距离也会更近,这就有助于模型通过数学计算向量空间中不同词汇之间的距离,从而捕捉不同词在语义和语法等方面的相似性。因此词向量不仅可以帮助模型理解词的语义,也可以捕捉词与词之间的复杂关系。GPT3的向量长度是12288,可以想象模型里面包含了多少信息。嵌入层相当于一个查找表,可以从训练得到的知识库中找到不同词元对应的向量。

通过嵌入层拿到词向量以后,下一步是对向量进行Positional Encoding(位置编码)。位置编码就是表示各个词在文本里顺序的向量,相同的词顺序不同可能意思也不同,所以词的位置信息也是模型理解文本上下文的关键因素。将位置向量与词向量结合给到模型,从而可以使得模型既可以理解词的意思,又可以理解不同词之间的顺序关系(不同顺序有不同含义)。
接下来将得到的向量送进编码器,编码器的作用是基于前面两个信息又增加了整个本文中词与词之间的相关性信息。捕捉词与词之间的相关性是通过一种叫自注意力机制的方法实现的。
Self Attention(自注意力机制)是Transformer的核心之一,Transformer在处理文本中每一个词的时候,会关注整个文本序列中的所有其他词,给予每个词不一样的权重,(可以理解成与不同词的相关程度),权重是模型在大量文本训练中逐渐学习到的成果,因为大量的数据训练,模型有能力知道当前这个词与该文本中其他词的相关程度,从而专注于输入里真正重要的部分。自注意力机制是模型理解文本上下文语义的关键。

解码器接收编码器的输出,即每个词的语义信息,位置信息以及不同词的相关性,解码器基于这个输入一步一步地生成输出序列。在生成每一步的输出时,解码器会考虑到两件事情:一是它已经生成了什么(即之前的输出),二是编码器告诉它的输入序列的信息。通过这种方式,解码器能够确保生成的输出不仅与输入信息相匹配,而且前后文逻辑连贯,语句通顺。这个过程会一直持续,直到整个句子翻译完成。
3、应用领域
目前市面上的大语言模型产品基本上都能覆盖以下能力:
1、文本翻译
GPT-4 等 LLM 的表现在某些方面比一些商业翻译软件具有更强的竞争力。因为LLM可以根据不同的上下文语境和文本内容进行自适应,从而可以更好地处理复杂的语言表达。缺点是针对使用率不高的语言翻译准度可能较弱,这与其训练的数据集大小挂钩。
2、文本总结、生成
LLM可以通过提取输入文本中的关键信息信息进行有效总结;LLM还可以根据给定的主题或关键词生成相关的文章
3、智能客服
LLM还可以应用于智能客服系统,通过理解用户的问题并给出相应的回答,针对一些重复性的简单业务时,提高客户满意度和效率。各大电商平台均已落地。
4、问答系统
问答系统是大语言模型在人机交互领域的一个关键应用。通过对各种知识库大量问题和答案进行训练,大语言模型可以理解用户的需求并给出准确的答案。教育、医疗行业应用较广泛。如学而思学习机、猿辅导海豚AI学等教育产品;互联网医疗公司医联的MedGPT,其问诊能力相当强大,据说拥有近3000种疾病的首诊能力,覆盖绝大多数诊断场景。
5、代码生成与自动化编程
LLM还可以用于代码生成和自动化编程。通过对大量代码进行训练,大语言模型可以理解编程语言的语法和逻辑规则,从而实现代码的自动生成。对提高开发效率有很大的帮助。例如Copilot、Bito、JoyCoder等。
4、使用心得
1、AI插件提高开发效率
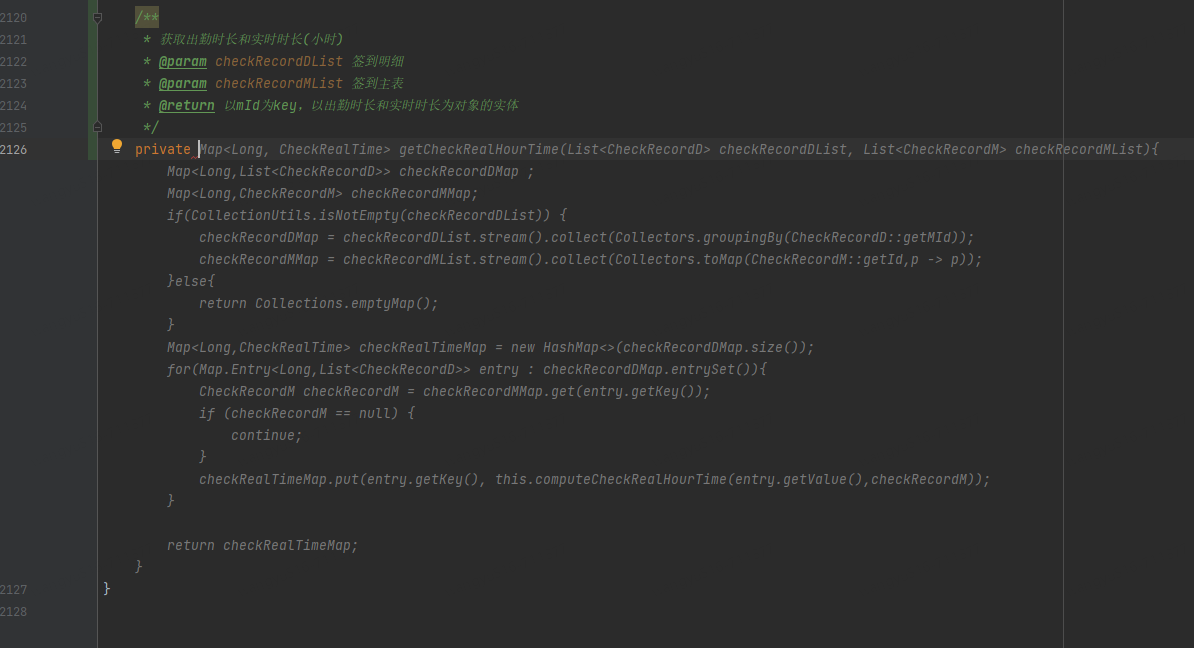
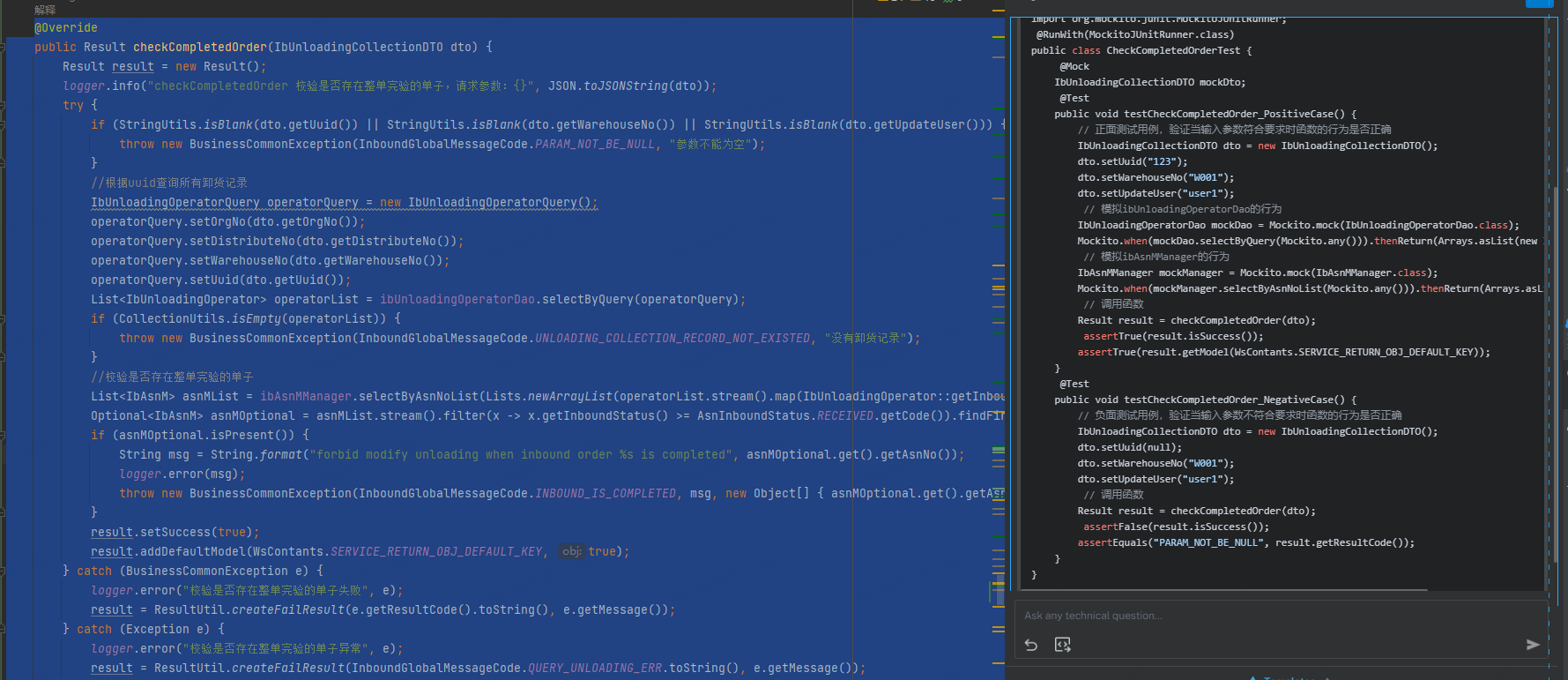
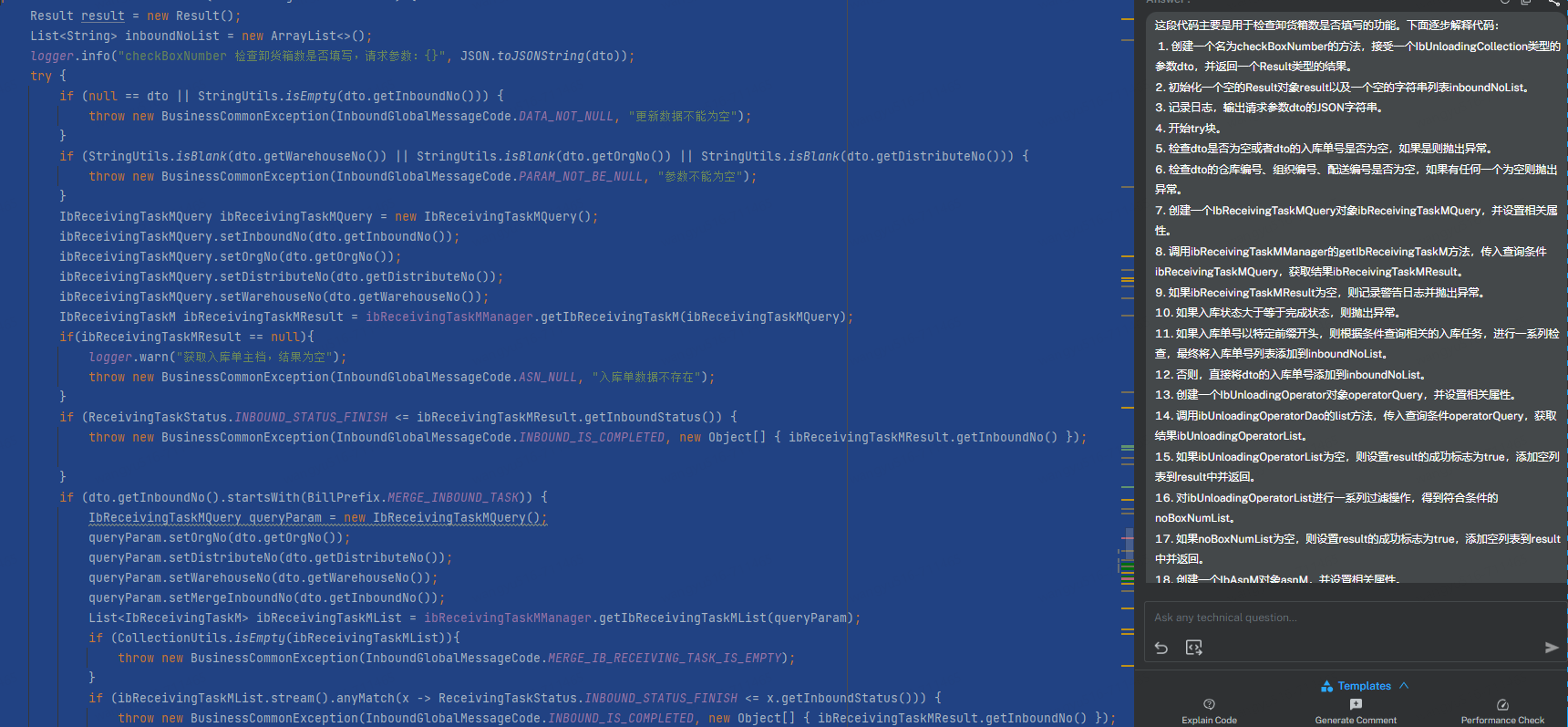
通过在注释中准确描述想要实现的效果,AI插件通过很强的上下文学习能力自动补全代码,大大提高了开发效率。
2、清晰、明确的表达意思
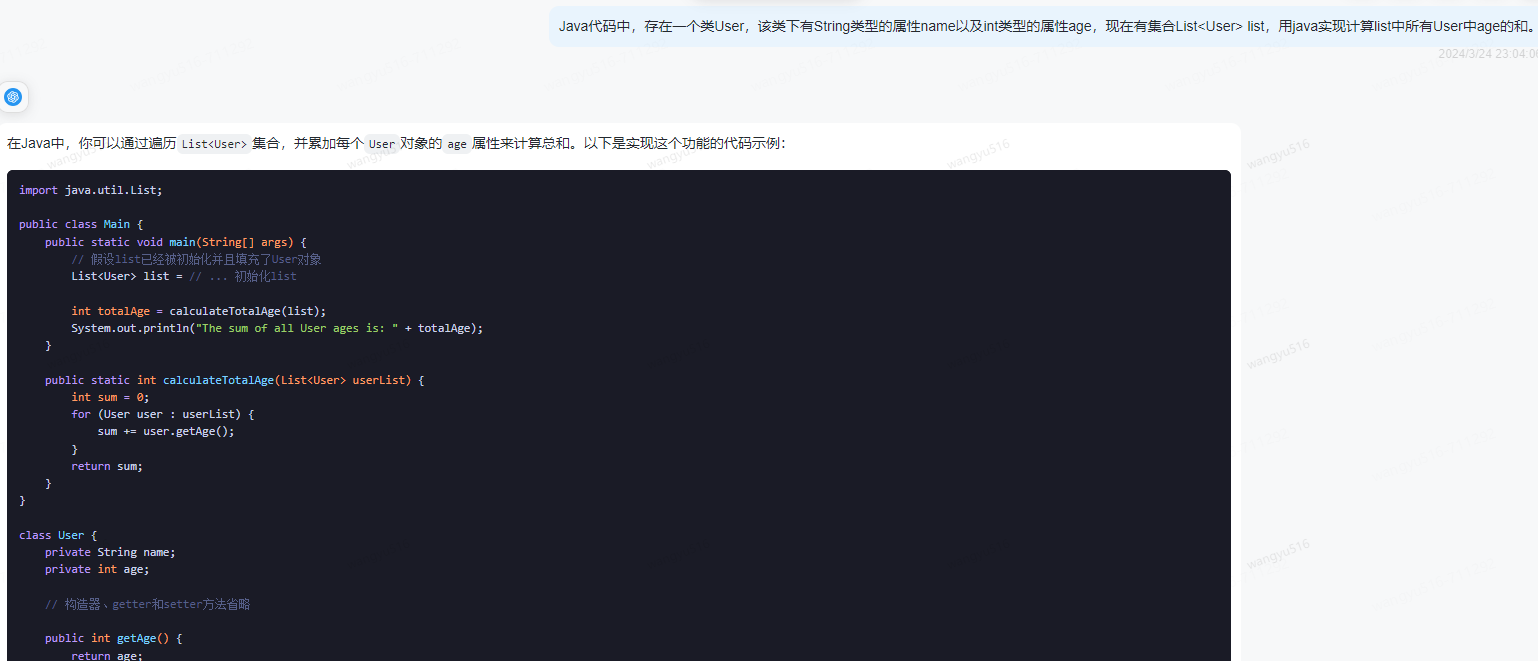
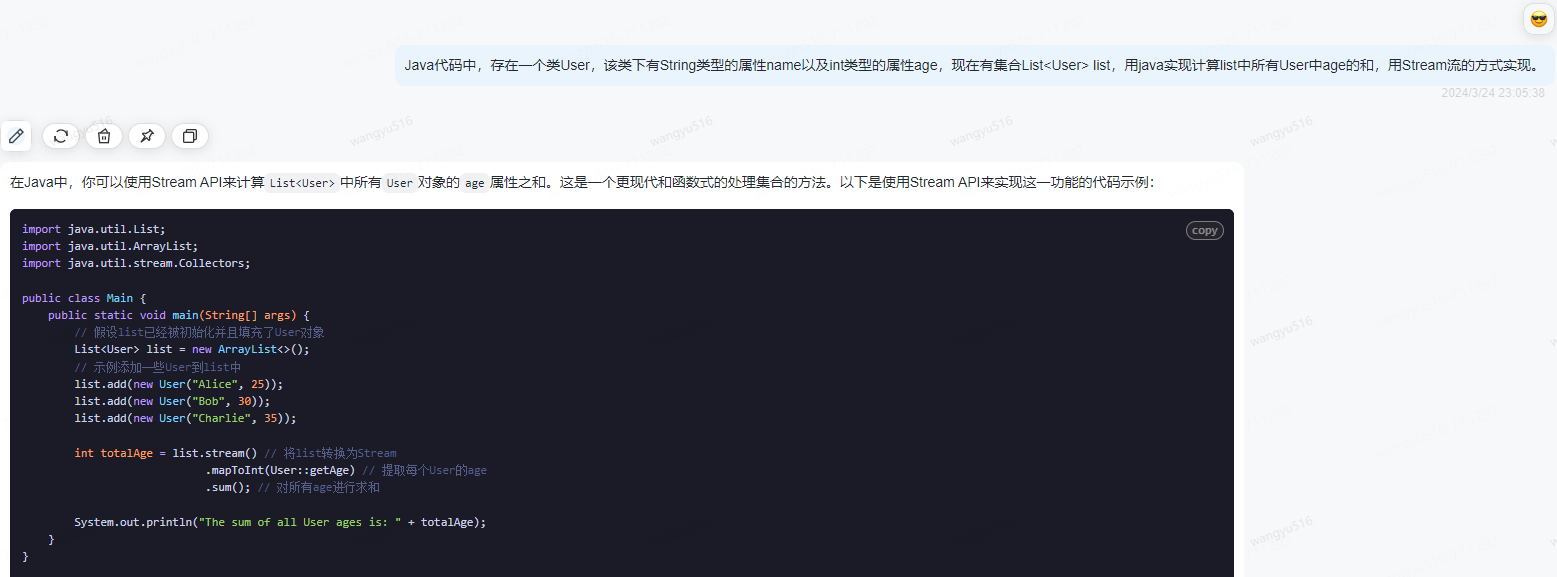
同样的实现效果,有不同的实现方式,可以指定更简单的方式让AI实现。
3、角色扮演
示例1:
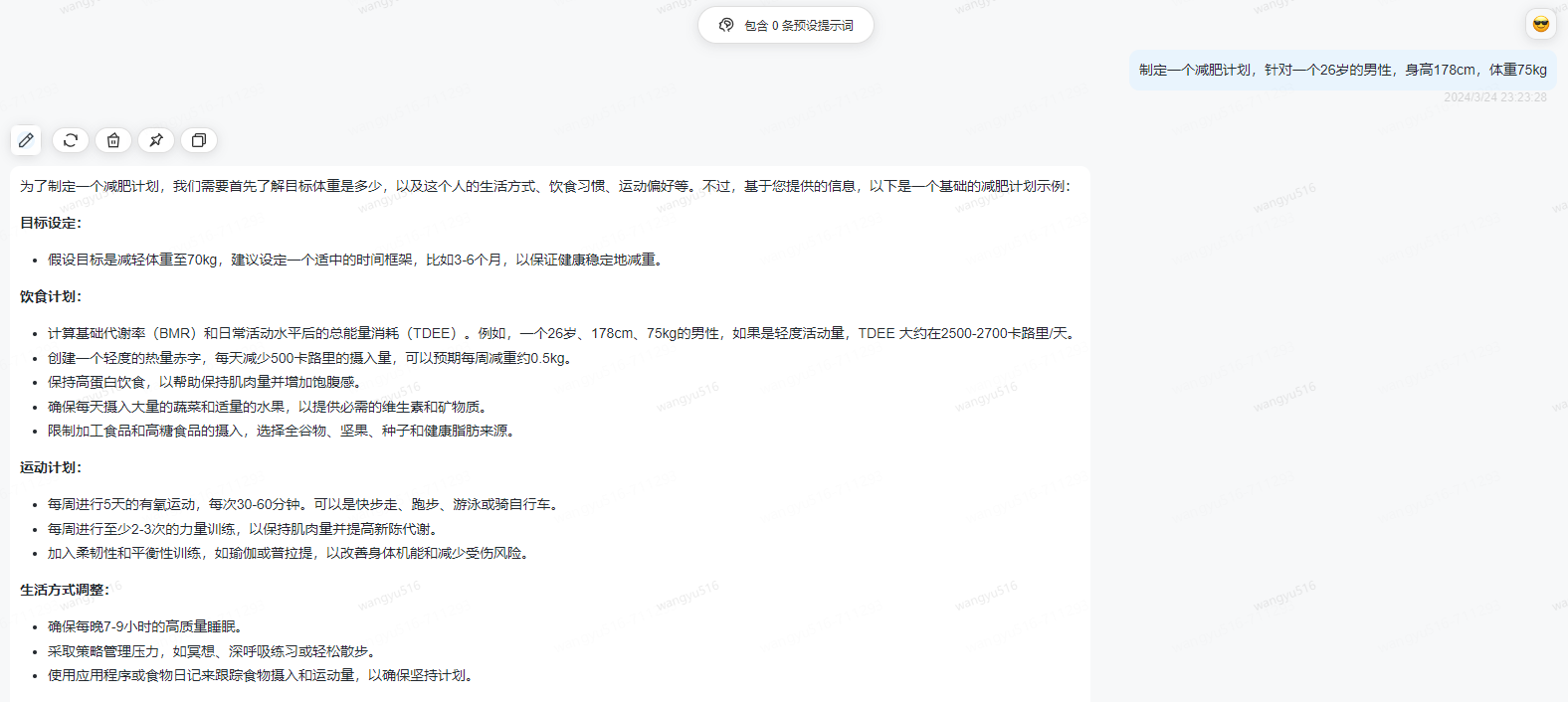
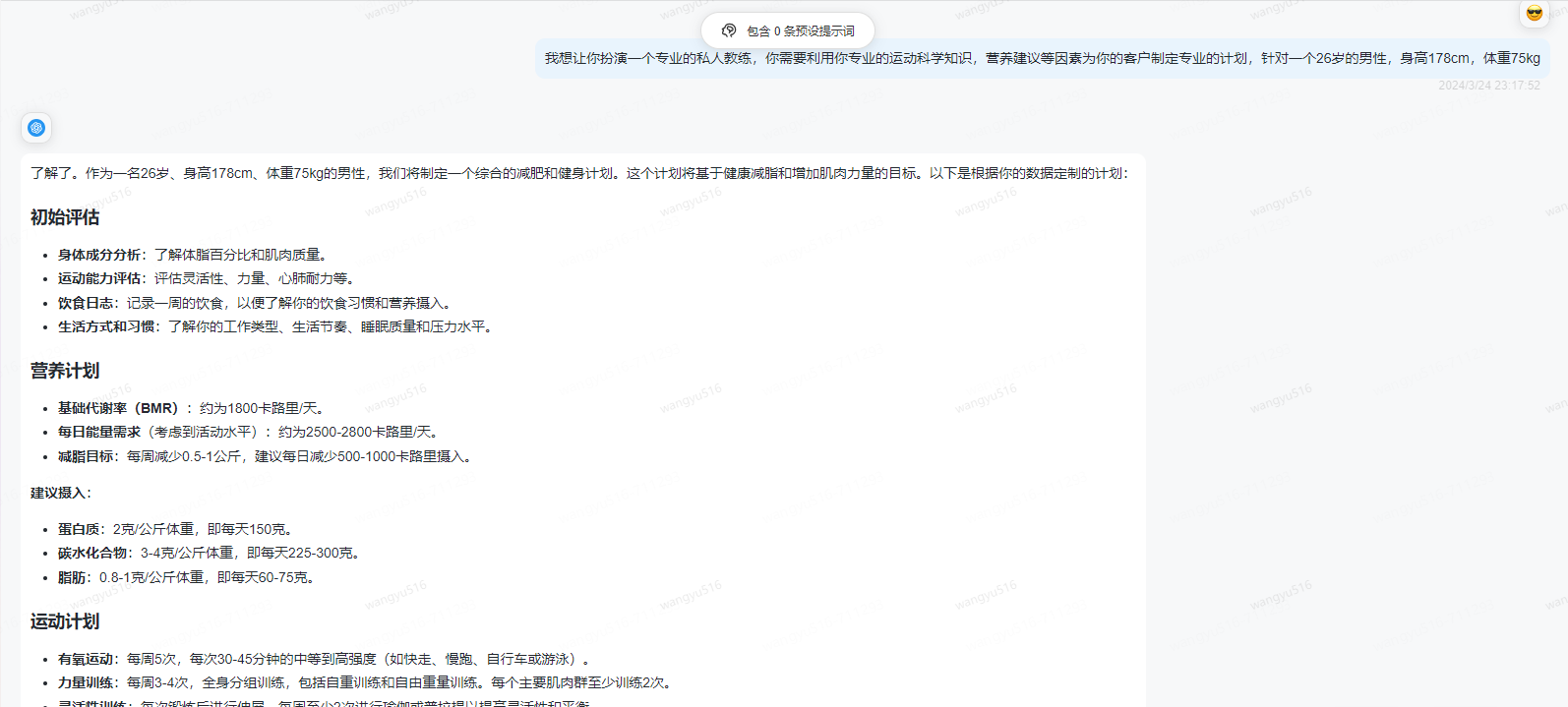
示例2:
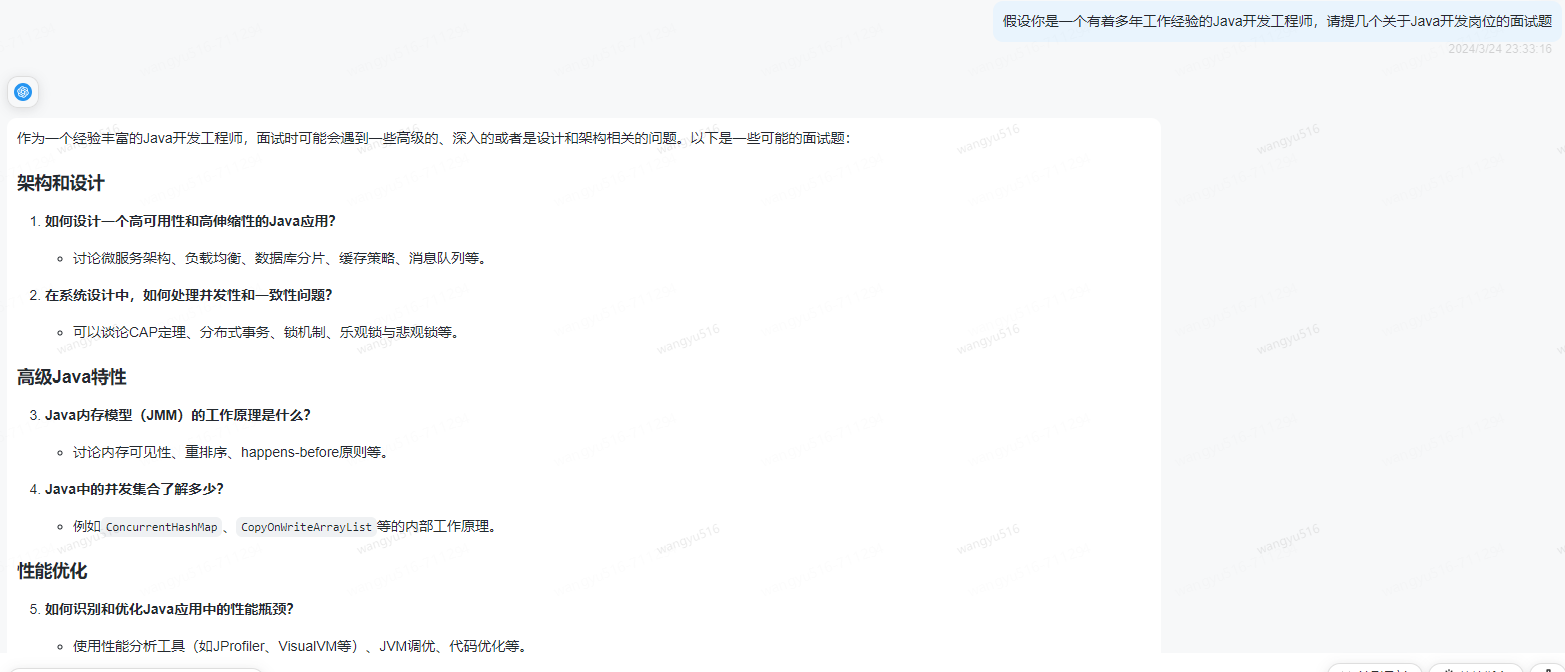
给AI设定成行业内专家的角色,它能提供更专业的回答。
5、常见概念
LLM(大语言模型):大语言模型
GPT(Generative Pre-trained Transformer):一种基于预训练Transformer架构的语言模型,用于生成文本。
Prompt(提示词):用户给大模型的输入
Prompt Engineering(提示词工程):通过一定技巧设计Prompt,引导AI回答你想得到的答案
Token:表示文本中的最小语义单元
Pre-training:在大量未标注数据上训练模型。
Embedding(嵌入):将Token转化成向量的技术
Fine-tuning(微调):在预训练模型的基础上,对某特定任务进行额外训练,以达到通过少量数据依旧可以在该任务上有不错的表现。
Transfer Learning(迁移学习):将已经在一个任务上学到的知识应用到另一个相关任务的过程。
Zero-Shot Learning: 模型在没有任何特定任务数据的情况下完成任务的能力。
Few-Shot Learning: 模型在只有很少数量的样本数据的情况下完成任务的能力。
AIGC(Artificial Intelligence Generated Content):指的是由AI生成的内容
6、与传统深度学习模型的区别
1、应用范围
LLM主要用于处理自然语言,如文本生成,翻译,总结等
传统深度学习模型较为多样化,图像识别、语音识别、时间序列识别等领域
2、训练方式
LLM通过预训练+微调的方式训练模型
传统的深度学习模型在实际应用中,通过有监督学习的方式训练模型更加常见
3、训练数据
LLM需要大量的文本数据进行预训练
传统的深度学习模型针对特定类型的数据(做了标记的图像、语音片段等)进行训练
4、参数规模
LLM参数规模极大,需要大量的计算资源来训练
传统的深度学习模型参数相对较少
7、电商/物流领域的外部尝试与应用
1、智能客服:电商以及物流平台的智能客服可以处理常见问题,如订单状态查询、商品介绍、售后服务、产品推荐等。
2、搜索优化:电商平台使用大语言模型来理解用户的搜索意图,提供更符合用户预期的搜索结果和产品推荐。
3、物流地址解析:将文本形式的地址信息转换成固定结构的数据。
4、用户情感分析:分析用户评论以及社交媒体上的讨论,以获取公众对不同产品的情感倾向。从而了解用户的需求以及喜好,改善服务质量,提升用户体验。
5、翻译服务:跨境电商通过实时翻译服务,兼容全球用户,提供更好的用户体验。
8、未来展望
charGPT展现了强大的文本处理能力,但它主要处理单一模态数据。在AI发展的过程中,慢慢出现了以Sora为首的这类多模态大模型,他们不再仅仅支持文本输入输出,而是支持各种形式的数据。当模型的语言能力足够强大以后,其带来的泛化能力也是非常强大的,它可以直接学习图像视频数据,通过对自然语言的理解,来给成熟的视频生成技术模块下指令,从而生成AI“理解”的视频。
泛化(Generalisation)可以理解为一种迁移学习的能力,大致可以理解为把从过去的经验中学习到的表示、知识和策略应用到新的领域,是大模型最被需要的能力。泛化意味着模型应该能够在没有直接训练的数据上表现得同样出色。
Sora大模型是由大语言模型和文图生成器拼接而成,它可以根据输入一些描述视频画面的提示词生成一段时长60秒的视频,并且视频质量还不错。最近爆火的KIMI大模型支持输入pdf、excel等常用办公文件,根据用户需要进行相关总结输出,最大输入文本上限达到200w。还有阿里的Qwen大模型,它是一种支持中英文等多种语言的视觉语言(Vision Language,VL)模型,Qwen-VL除了具备基本的文字识别、描述、问答及对话能力之外,还新增了视觉定位、图像中文字理解等能力。
1、文档解析
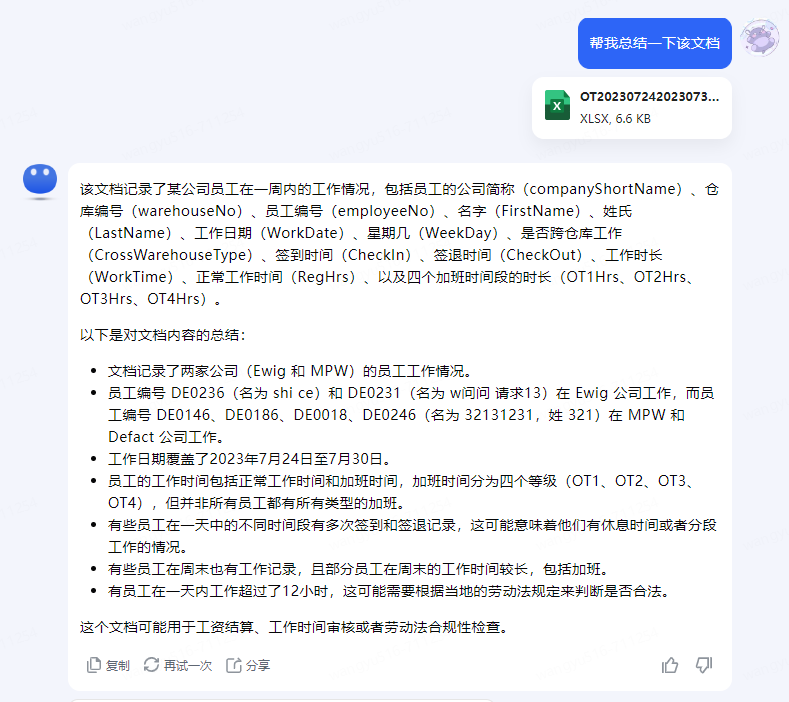
2、图片+文字解析
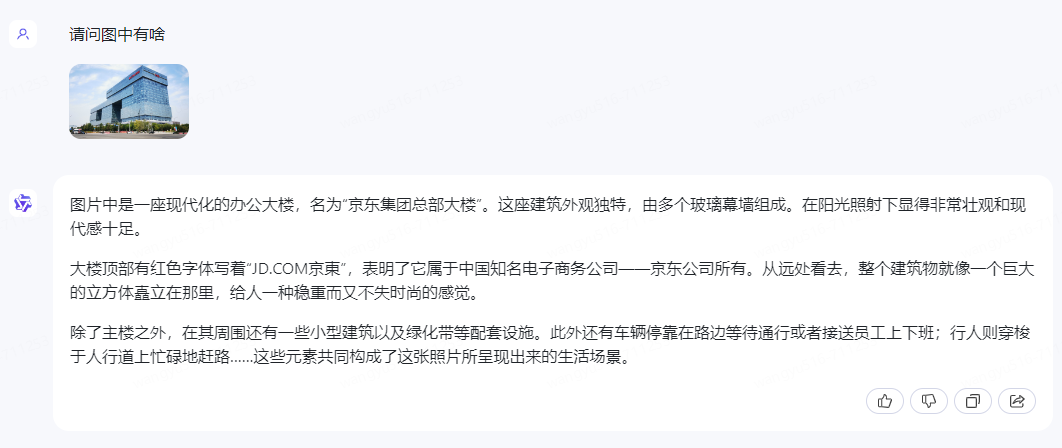
3、图片生生成
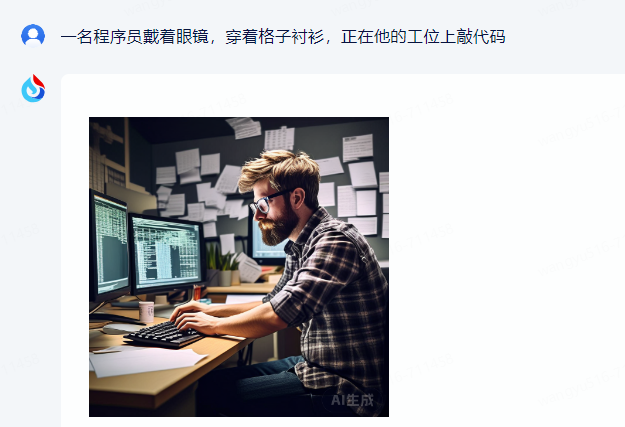
4、文字生成视频
多模态大模型的出现则让我们看到了多模态模型在模拟物理世界时的巨大潜能。并且,现在越来越多大语言模型产品也在朝着多模态的方向发展。如果2023年是属于大语言模型的一年,那么2024年,将会有越来越多的大语言模型升级,通过与不同模型的有效结合,实现多模态转换。多模态模型将进一步拓展其在语音识别、图像识别、自然语言处理等领域的应用,为人们提供更加智能化的服务和体验。
多模态在大模型的语境中指的是模型能够理解并处理多种不同类型的数据和信息,例如文本、图像、声音、视频等。这种类型的模型可以捕捉和理解来自不同模态的信息,并能够在这些模态之间建立联系。例如Sora,Kimi这些大模型(文本——图像;文本——视频)






