您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
工程中实践的微服务设计模式
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
工程中实践的微服务设计模式
wy****
2024-04-08
IP归属:北京
440浏览
最近在读《微服务架构设计模式》,开始的时候我非常的好奇,因为在我印象中,设计模式是常说的那23种设计模式,而微服务的设计模式又是什么呢?这个问题也留给大家,在文末我会附上我对这个问题的理解。本次文章的内容主要是工作中对微服务设计模式的应用,希望能对大家有所启发。 ### 事务发件箱模式 > 事务发件箱模式:将消息保存在数据库 **“发件箱”表** 作为事务的一部分 policy 为处理投保的微服务,以投保事务为例: 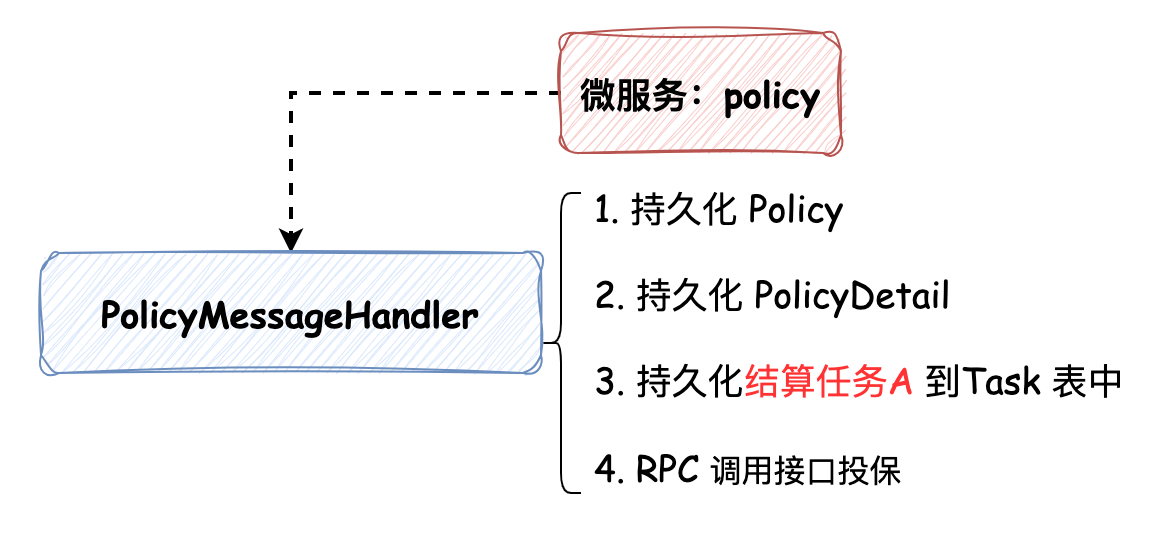 如上图所示,在投保过程中有4步操作(注意持久化结算任务(Task)A的操作),这个过程便是事务发件箱模式的体现,为什么说它是事务发件箱模式呢? 1. Task 表中持久化的消息任务最终会被发送到 MQ 中,所以它是发件箱 2. 持久化 Task 记录的操作被包含在事务中,所以称它为事务发件箱 Task 记录中保存的消息体是通过另一个服务 service-job **轮询扫描初始化状态的任务**,并将其发送到 MQ 的,发送成功后任务修改为完成状态,这种方式被称为事务性发件箱模式中的**轮询发布数据模式**。 这种设计模式有一个弊端:**随着数据量不断增大,经常轮询数据库可能造成昂贵的开销**。在我们的系统中采用了两种措施进行优化: * **分库分表**:以空间换时间,避免单表数据量过大造成的开销 * **将完成状态的任务进行“数据结转”的设计**:任务先保存在 Task 表中,被执行完成后被归档到 TaskRecord 表中 此外还有一种更加高效但是开发稍复杂的方式:**拖尾数据库日志模式**。 ### 拖尾数据库日志模式 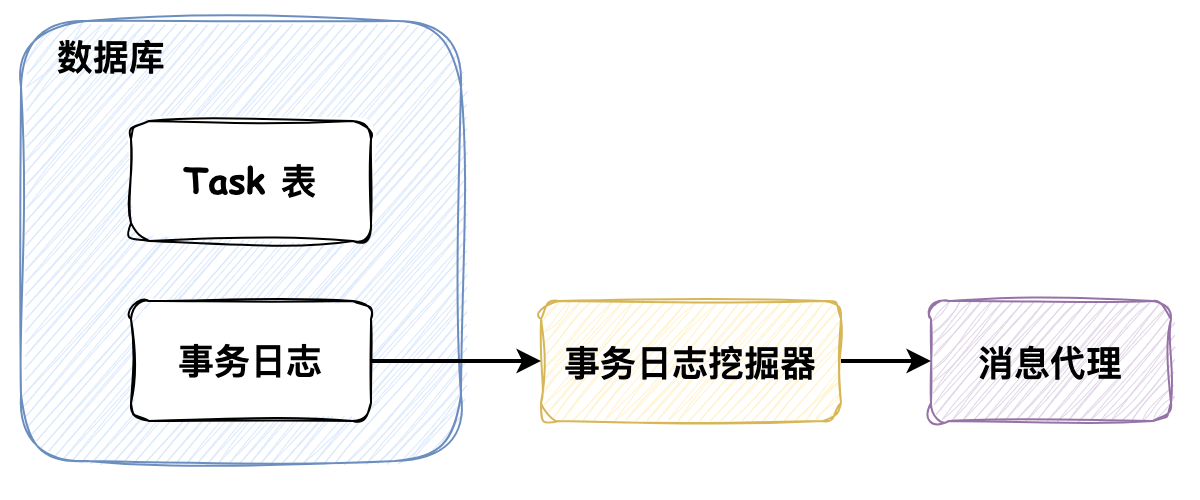 数据库的每次更新都对应着一条数据库事务日志,通过事务日志挖掘器读取事务日志,并将每条与消息有关的记录发送给消息代理(开源框架可参考:[Github: debezium](https://github.com/debezium/debezium),可以将MySQL的binlog读取到Kafka中),但是这种方法的弊端是需要在开发上做一些努力,因为需要监听数据库事务日志和调用数据库底层相关的API。 ### 相信“邮递员” 工程实践中,还有一种没有采用事务发件箱模式来保证数据一致性的方法:在事务中先持久化完成状态的任务,随后直接将消息发送给消息队列,如果消息发送失败,捕获异常并将任务修改成初始化状态,随后依赖 service-job 服务进行补偿:即将初始化状态的任务发送给 MQ。我们还是以投保的过程为例,如下代码所示: ```java // 1. 持久化保单数据 savePolicy(); // 2. 持久化保单明细数据 savePolicyDetail(); // 3. RPC 调用投保接口 rpcPolicy(); // 4. 持久化完成状态的任务,任务中记录了要发送给MQ的消息体 int num = insertTask(TaskStatus.COMPLETE); // 5. 如果插入成功了,借助线程池发送消息 if (num > 1) { threadPoolExecutor.execute(() -> { try { mq.send(task.info); } catch(Exception e) { // 发送失败,抛出异常,修改任务状态为初始化状态,依赖 service-job 服务进行补偿 updateTask(TaskStatus.INIT); } }); } ``` 这种设计模式默认认为MQ集群始终是高可用的,我将这种设计模式命名为**相信“邮递员”**。在生产实践中,因为有MQ运维团队在保障MQ集群的高可用,所以这种设计模式也是比较稳定的。 *** 在投退保流程中,涉及不同数据库的修改操作,如保单的持久化、保单状态的修改以及相关结算的推送,要保证这个过程中的数据一致性,那么便不能再依赖ACID本地事务,而是需要使用跨服务的 Saga 设计模式来维护数据一致性。下面我们来介绍两种,分别是**协同式Saga**和**编排式Saga**。 > Saga 通过使用异步消息来驱动一系列本地事务,来维护多个服务之间的数据一致性。 ### 协同式Saga 我们先带着 Saga 的概念来看一下投保的流程: 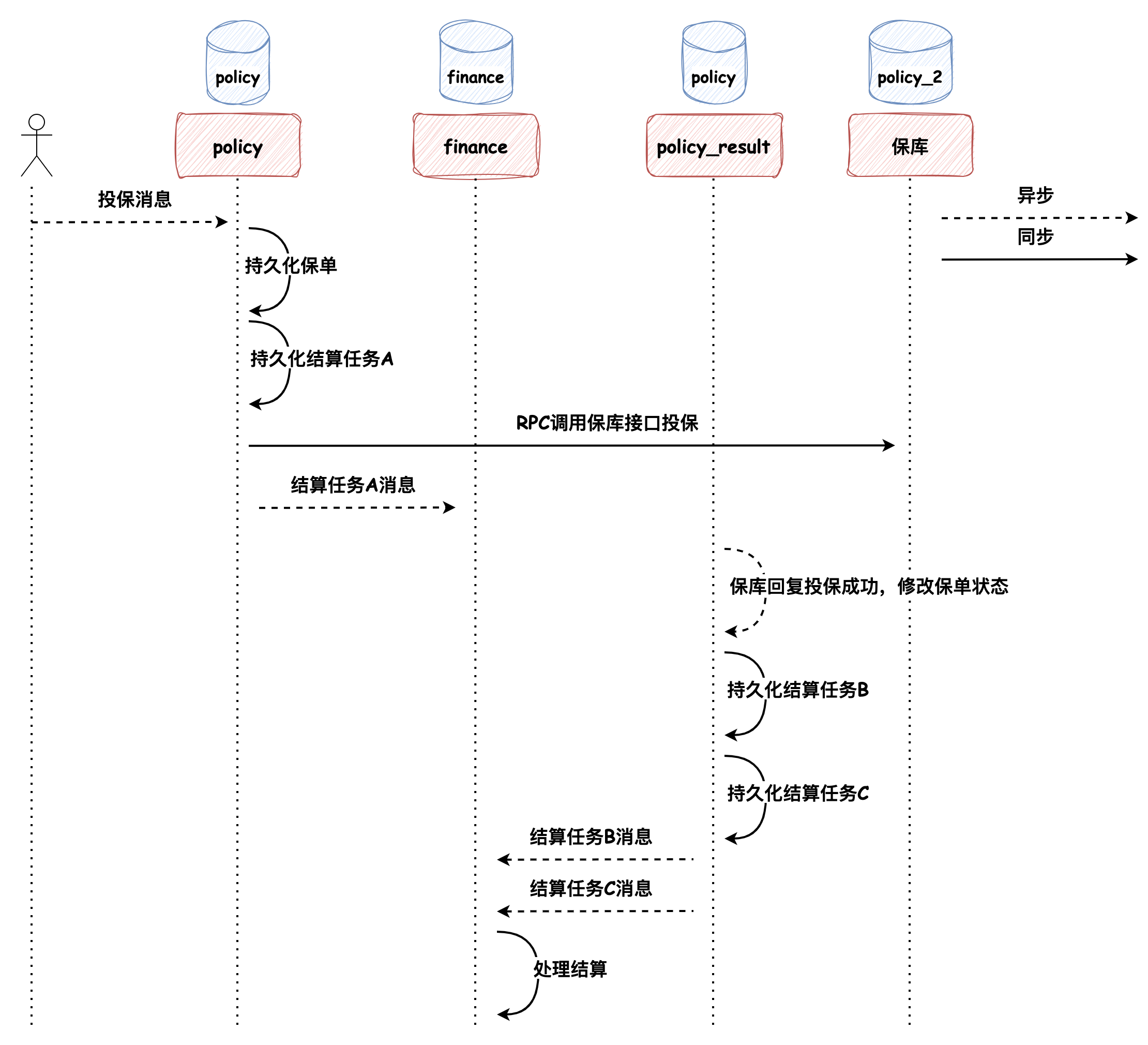 在这个过程中,Saga的决策和执行顺序分布在Saga的每一个参与方中,并且**通过消息交换的方式**进行沟通,一个Saga的参与方执行完触发另一个Saga执行,保证数据一致性,这种方式被称为**协同式Saga**。 这种设计模式的优劣如下: * **优势**:比较简单,服务间松耦合 * **弊端**:比较难理解,因为它没有一个地方定义了Saga的执行流程,Saga的处理逻辑分布在不同的服务中,需要根据代码触发的任务去整理整个流程 > **为什么没有采用XA来实现分布式事务**? > > XA采用**两阶段提交协议**实现分布式事务,在事务中的所有参与者都成功时提交,有失败时便回滚。要使用该模式一方面要求所有的事务参与者(数据库或消息代理)满足XA标准,另一方面,它本质上是**同步的进程间通讯**,同步的通讯机制有一个弊端:它会降低分布式系统的可用性(假如分布式系统中每个服务的可用性为99%,如果服务与服务之间是同步调用的方式:服务必须从另外一个服务获取响应后才能返回它的客户端调用,那么分布式系统的可用性为各个服务可用性的乘积,随着同步交互服务的增加,可用性会随之降低,**最大化可用性的方式应该最小化系统间的同步操作量**)。所以,一般互联网公司很少采用强一致性的设计,而是采用最终一致性设计(银行可能会使用到强一致性)。此外,XA实现分布式事务需要依赖事务的协调者(如Seata),实现起来相比于上述方式复杂。 ### 编排式Saga Saga 的另一种实现方式是编排式,编排式 Saga 需要事务的协调者(DTM),全局事务发起人将整个全局事务的编排信息,包括每个步骤的正向操作和反向补偿操作定义好之后,提交给事务协调者(DTM),协调者按步骤异步执行Saga逻辑。 如果投保流程使用编排式Saga的话,投保成功的过程如下: 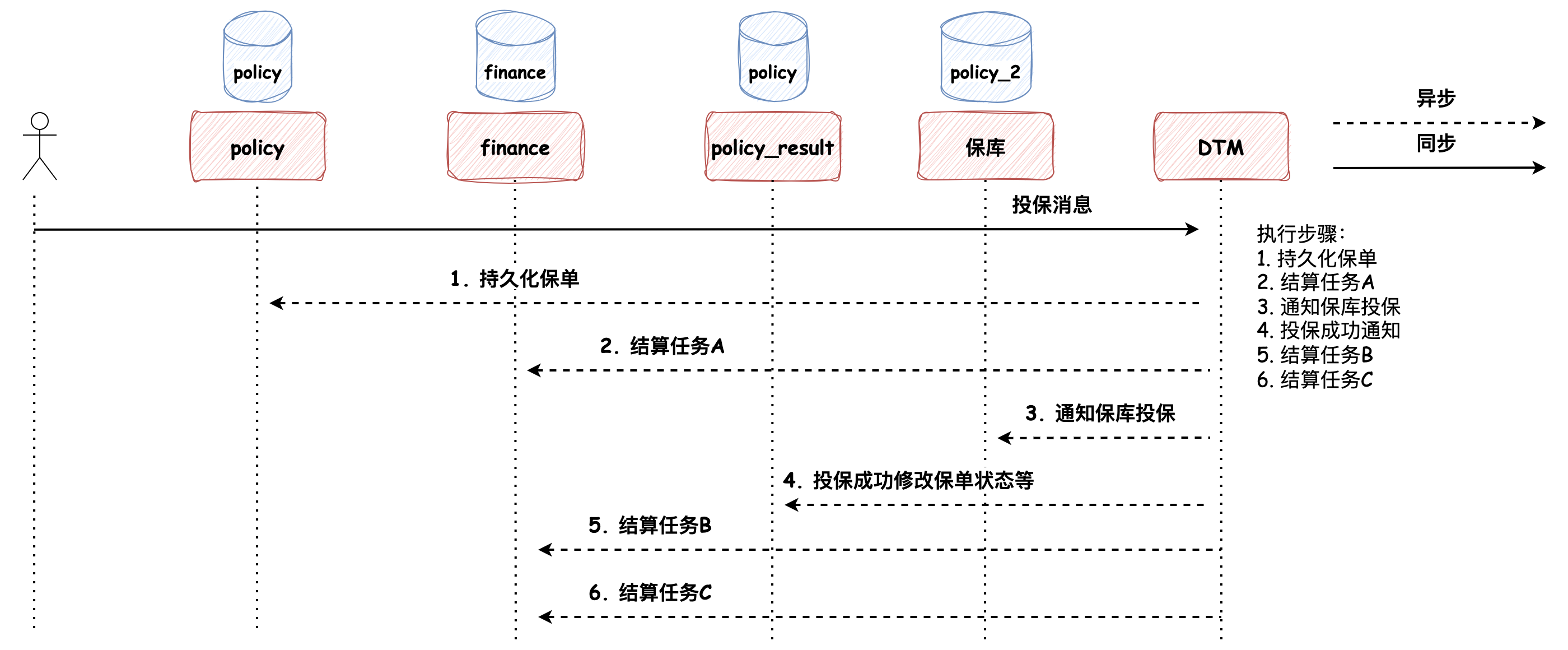 编排式Saga的事务定义执行步骤非常灵活,假如我们要在投保失败的情况下做取消结算的**补偿逻辑**的话,可以自行定义,图示如下: 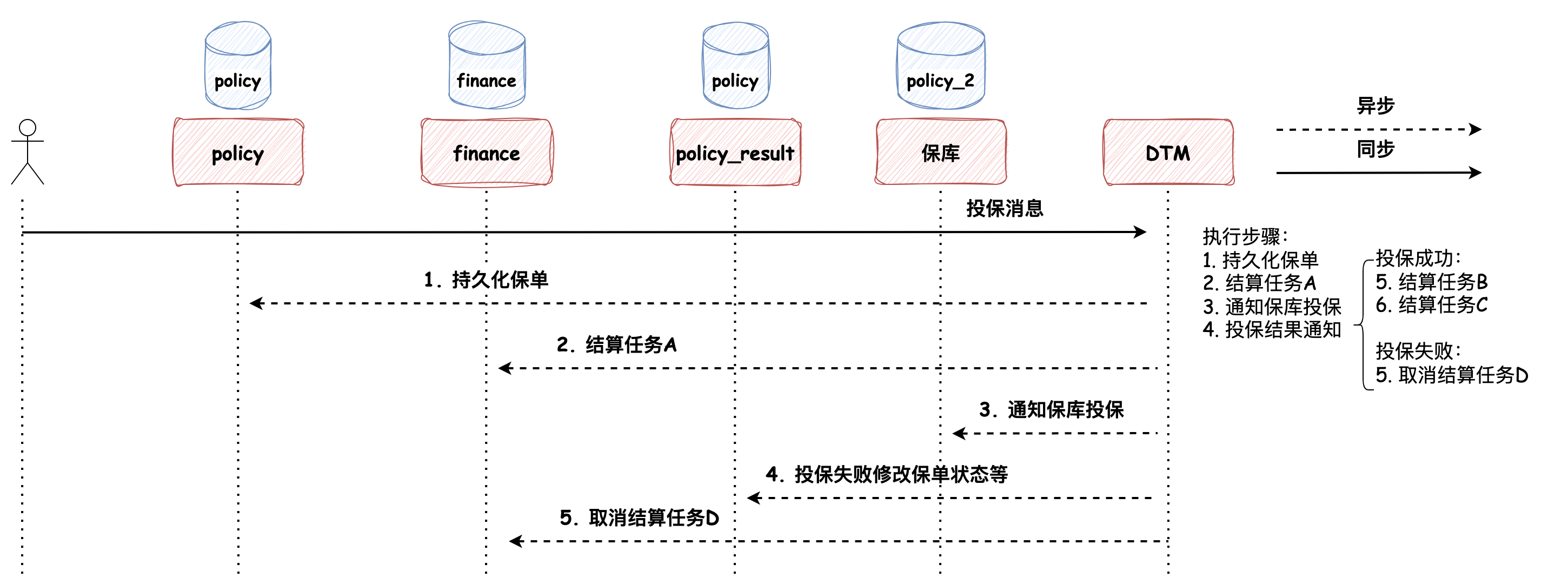 这种设计模式的优劣如下: **优势**:能够集中流程控制、易于扩展和服务间松耦合,如果服务之间的依赖关系复杂,且业务流程经常变动,使用编排式Saga是合适的 **弊端**:引入协调者增加了开发复杂性(扩展学习:[DTM开源项目文档](https://dtm.pub/)) *** 现在我们回到文章开篇的问题:**微服务架构设计模式与我们常说的设计模式的区别是什么?** > 我们常说的设计模式是面向对象的设计模式,它的解决方案元素是类,而微服务设计模式是站在更高维度即系统架构层面的设计模式,它面向的对象是系统中各个服务,解决方案也由相互协作的服务构成的。 *** ### 巨人的肩膀 * 《微服务架构设计模式》:第 1 - 4 章
上一篇:AI从入门到入门之手写数字识别模型java方式Dense全连接神经网络实现
下一篇:写给职场新人|从迷茫到屡获殊荣的技术人成长之路
wy****
文章数
47
阅读量
38105
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
1. 为什么要分区?分区(partitions) 也被称为 分片(sharding),通常采用对数据进行分区的方式来增加系统的 可伸缩性,以此来面对非常大的数据集或非常高的吞吐量,避免出现热点。分区通常和复制结合使用,使得每个分区的副本存储在多个节点上,保证数据副本的 高可用。如下图所示,如果数据库被分区,每个分区都有一个主库。不同分区的主库可能在不同的节点上,每个节点可能是某些分区的主库,同时是
01
深入理解分布式共识算法 Raft
“不可靠的网络”、“不稳定的时钟”和“节点的故障”都是在分布式系统中常见的问题,在文章开始前,我们先来看一下:如果在分布式系统中网络不可靠会发生什么样的问题。有以下 3 个服务构成的分布式集群,并在 server_1 中发生写请求变更 A = 1,“正常情况下” server_1 将 A 值同步给 server_2 和 server_3,保证集群的数据一致性:但是如果在数据变更时发生网络问题(延迟
01
缓存之美:从根上理解 ConcurrentHashMap
本文将详细介绍 ConcurrentHashMap 构造方法、添加值方法和扩容操作等源码实现。ConcurrentHashMap 是线程安全的哈希表,此哈希表的设计主要目的是在最小化更新操作对哈希表的占用,以保持并发可读性,次要目的是保持空间消耗与 HashMap 相同或更好,并支持利用多线程在空表上高效地插入初始值。在 Java 8 及之后的版本,使用 CAS 操作、 synchronized
01
缓存之美:万文详解 Caffeine 实现原理(上)
由于神灯社区最大字数限制,本文章将分为两篇,第二篇文章为缓存之美:万文详解 Caffeine 实现原理(下)文章将采用“总-分-总”的结构对配置固定大小元素驱逐策略的 Caffeine 缓存进行介绍,首先会讲解它的实现原理,在大家对它有一个概念之后再深入具体源码的细节之中,理解它的设计理念,从中能学习到用于统计元素访问频率的 Count-Min Sketch 数据结构、理解内存屏障和如何避免缓存伪
wy****
文章数
47
阅读量
38105
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
01
深入理解分布式共识算法 Raft
01
缓存之美:从根上理解 ConcurrentHashMap
01
缓存之美:万文详解 Caffeine 实现原理(上)
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 wy****
wy**** 2024-04-08
2024-04-08 440浏览
440浏览






