您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
一种融合指代消解序列标注方法在中文人名识别上的应用(上)
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
一种融合指代消解序列标注方法在中文人名识别上的应用(上)
jd****
2024-04-02
IP归属:北京
663浏览
## 技术领域 自然语言处理领域。 ## 应用场景: 适用于自然语言处理领域,通过命名实体识别(Named Entity Recognition,NER),准确识别实体。依托自然语言处理领域,基于人民日报数据及构造的舆情公告数据,提出一种融合指代消解的序列标注方法来改进人名识别。 ## 解决的问题: 实体包括人名、地名和组织名等,与其他实体相比,人名与职务、职务变更及人称代词有关。人名作为众多实体类别之一,常出现在信息资料库、图书馆借阅登记表、期刊文章等场景中。但在人名的实体识别时,人名语料的残缺及人称指代不明等问题,会严重影响识别的准确度,成为处理中的难点、痛点。 基于人民日报数据及构造的舆情公告数据,提出一种融合指代消解的序列标注方法来改进人名识别。通过人民日报数据及构造的舆情公告数据,能有效缓解人名识别中人名语料不完善的问题;通过数据增强优化数据集,并对人称代词进行人称消解,解决人称代词指代不明、有效数据占比低等问题,提高人名提取的准确率。 ## 系统方法说明 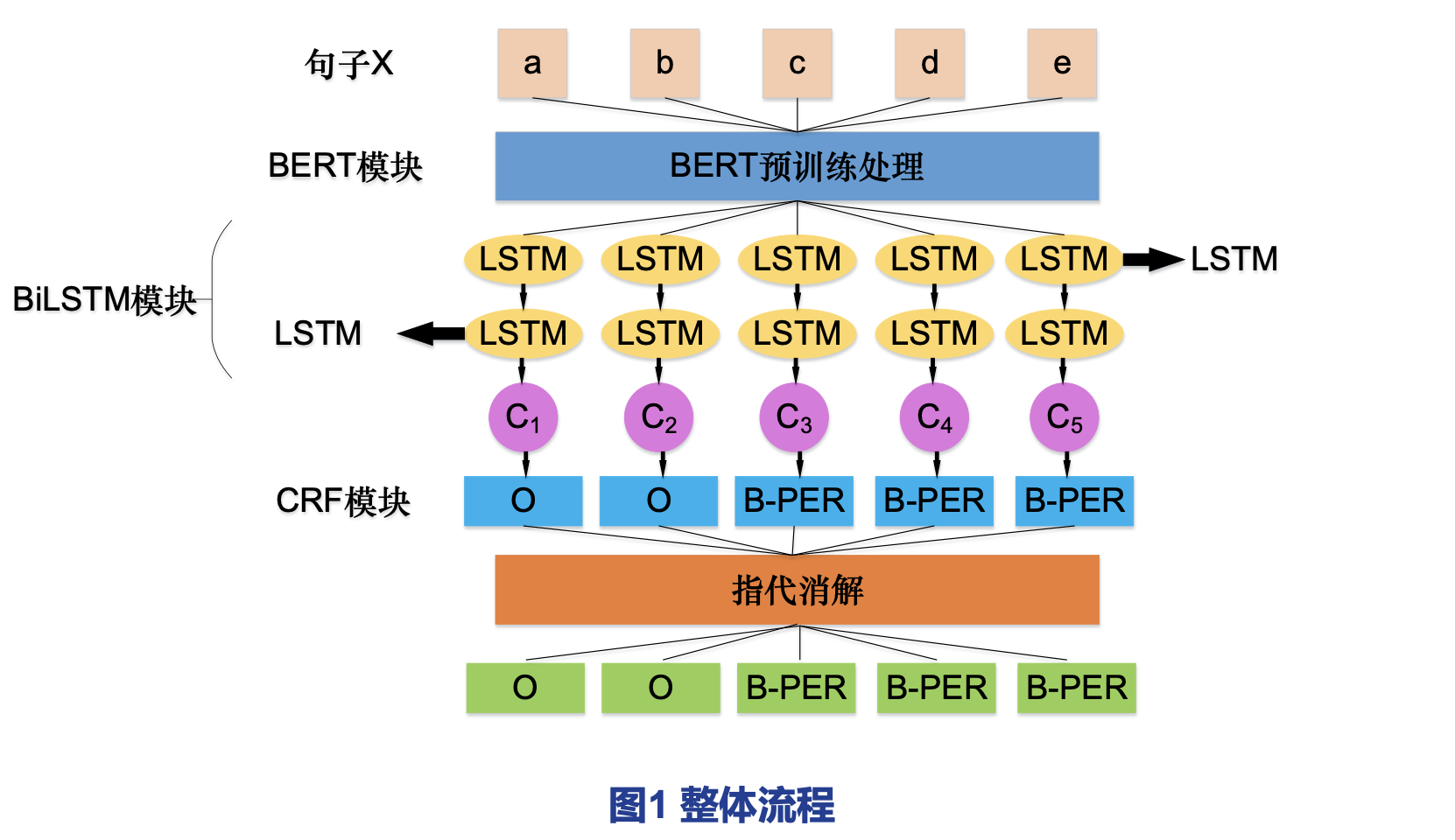 ### 一、对数据进行数据增强: * 利用爬虫技术爬取到舆情公告文本数据。 * 利用分词工具从海量文本中进行文本抽取,抽取出符合要求的单句文本。 * 针对职务变更词和职务,设置自定义词典,达到数据增强的效果。 #### 数据预处理阶段,根据职务变更等有效信息进行数据增强 先利用爬虫技术爬取到舆情公告文本数据,之后利用分词工具从海量文本中进行文本抽取,抽取出符合要求的单句文本;再针对职务变更词和职务,设置自定义词典,达到数据增强的效果。 首先,对文本数据进行清洗、分类,既可以减少噪声干扰,又能保证后续数据增强的正确性。接着,对职务变更词和职务进行细粒度区分,为后续测验铺垫。不进行数据预处理,即直接在原文本上也可以进行中文人名识别,但这样性能差。首先,对文本数据进行清洗、分类,既可以减少噪声干扰,又能保证后续数据增强的正确性。接着,对职务变更词和职务进行细粒度区分,为后续测验铺垫。 在分词阶段,使用Jieba分词。虽然有的非全名字段,如“周先生”仍可成功识别,但是少许职务会被当作人名出现。为了解决该问题,通过设置禁用词表和自定义词典,改进粗略目标文本数据,进而得到最终的精确目标文本数据。在获得精确文本数据后,按照职务变更词、职务进行提取,达到数据增强的作用。 ### 二、使用了BERT模型和指代消解算法: * 加入BERT语言预处理模型,获取到高质量动态词向量。 * 融入指代消解算法,根据指代词找出符合要求的子串/短语。 ### 【1】加入BERT语言预处理模型,获取到高质量动态词向量 在使用BERT模型之前,有两大模型训练方式,一个是Word2Vec模型,它训练出来的词向量属于静态词向量,无法表示一词多义;另一个方法是使用GPT单向语言模型训练的,无法获取字的上下文信息,所以将单向的LSTM模块改为双向的BiLSTM模块,对单项GPT模型进行改进,变成双向语言模型。仅仅利用双向长短时记忆网络与条件随机场结合的方式,可以建模并标出序列的关系,但是无法动态表征。 BERT模块主要进行“表示”作用,抽取丰富的文本特征,得到batch_size*max_seq_len*emb_size的输出向量。为了更好的学习上下文特征,加入BERT语言预处理模型,以Transformer结构为核心,进行一词多义并获取词的上下文信息,获取到高质量动态词向量。 图1整体流程可知,通过分词器已经将句子x分割为a~e五个字,将其作为输入传给模型中BERT模块做训练处理,得到的输出向量作为模型中的BiLSTM模块的输入,进行特征提取,得到输出向量,将这五个向量作为输入,进入模型中的CRF层进行解码,计算最优的标注序列,至此已经能够有效地提高人名识别的准确率了。 ### 【2】融入指代消解算法,根据指代词找出符合要求的子串/短语 该部分将在《一种融合指代消解序列标注方法在中文人名识别上的应用(下)》重点阐述。 ### 【3】融入的指代消解算法,比加入外部语料和字符级特征更通用有效 该部分将在《一种融合指代消解序列标注方法在中文人名识别上的应用(下)》重点阐述。 **<span style="color: #b8b8b8"> 该算法未来将拓展至机构名、地名以及其他所有以名称为标识的实体,能更好的服务于京东小程序客户体验中的寄收件地址的文本识别中,提高相关识别的准确率。</span>**
上一篇:基于Redis实现基本抢红包算法
下一篇:Hive引擎底层初探
jd****
文章数
8
阅读量
13402
作者其他文章
01
Vibe Coding AI 编程实践
Vibe Coding最近几年,以 LLM 为主要技术路线的又一轮 AI 浪潮席卷了整个行业,并迅速外溢到与信息技术产业无关的普通民众的日常生活中。快到惊人——甚至可以说是有些吓人的发展迭代,正在迅速叩开传统企业和 C 端用户的大门;给个人和企业用户带来便捷、效率与趣味的同时,也在一些行业和岗位完成技术替代。作为计算机行业的一个细分领域的从业者、一个前端工程师,虽然我们与真正参与 LLM 研发的算
01
记录一次「OSS上传文件的前置处理机制」实例剖析
引言在云计算环境中,对象存储服务(OSS)是一种提供存储和访问任意类型数据(如网站内容、企业备份数据、游戏、IoT 设备数据等)的服务,支持从任何地点、任何时间访问数据。在很多应用场景中,用户需要上传文件到 OSS,这可能包括图片、视频、文档等多种格式的文件。为了提高效率、保障安全和优化用户体验,实现文件上传的前置处理机制变得尤为重要。前置处理机制文件压缩是一个重要的前置处理步骤。它不仅可以减少文
01
一种融合指代消解序列标注方法在中文人名识别上的应用(下)
一种融合指代消解序列标注方法在中文人名识别上的应用(上)(续)二、使用了BERT模型和指代消解算法:加入BERT语言预处理模型,获取到高质量动态词向量。融入指代消解算法,根据指代词找出符合要求的子串/短语。【2】融入指代消解算法,根据指代词找出符合要求的子串/短语 指代消解算法如图2所示,简单来说,就是考虑文档中子串/短语以及学习子串/短语的可能指代。通过分词器将句子y分割为a~e五个字,将其作
01
暗水印——变换域DCT水印算法(一种通用性强,能有抵御攻击的手段)
引言 随着计算机和网络技术的飞速发展,信息的安全保护问题日益突出。数字图像、音频和视频等多媒体数字产品愈来愈需要一种有效的版权保护方法——水印技术,通常用于保护知识产权、防止未经授权的访问、作弊等。 广义上可以把水印技术划分为四大类:图像水印、视频水印、音频水印和文本水印。这些水印技术都有其独特的特点和应用场景,需要根据具体的数字媒体保护需求进行选择使用。技术与实践意义 本文
jd****
文章数
8
阅读量
13402
作者其他文章
01
Vibe Coding AI 编程实践
01
记录一次「OSS上传文件的前置处理机制」实例剖析
01
一种融合指代消解序列标注方法在中文人名识别上的应用(下)
01
暗水印——变换域DCT水印算法(一种通用性强,能有抵御攻击的手段)
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 jd****
jd**** 2024-04-02
2024-04-02 663浏览
663浏览






