您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
学算法要读《算法导论》吗?
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
学算法要读《算法导论》吗?
wy****
2024-03-04
IP归属:北京
855浏览
这篇文章是我学习算法的心得,希望它能够给一些将要学习算法且准备要读大部头算法书籍的朋友一些参考,节省一些时间,也为了给经典的“黑皮书”祛魅,我觉得这些书籍在大部分互联网从业者心中已经不再是进步的阶梯,而是恐惧的阴影了,因为当一些学习路线中列出这些书目时,评论区多是调侃少是交流和讨论。在这之前我也这些书抱有读起来很困难的看法,但是在我参考过《算法导论》之后,我觉得它更像是一杯“鸡尾酒”:正文学习起来相对容易,能帮大家建立基础,后续的习题和实验,能帮助有需要的人进行深入学习,扩展的高级数据结构和数论等章节也能进行探索,就看大家怎么来利用了。 开始学习算法的契机是23年初参加[《Hello 算法》](https://www.hello-algo.com/)开源项目的内容贡献,发现自己算法基础知识匮乏,索性准备系统地学习一下算法相关的知识,在这前后一共读了4本书:《Hello 算法》、《数据结构与算法之美》、《算法(第四版)》和《算法导论》(参考了前16章),学习期间在朋友的建议下实践了艾宾浩斯学习法,觉得收货良多。所以,本文会分两部分,分别介绍算法的学习指南和学习方法,希望对大家能有启发: ### 算法学习指南 我采用的专题阅读学习,以《算法》为主要参考书目,逐章阅读,每学习完一个章节都会再去阅读其他书籍的对应章节作为内容补充,并结合章后的习题练习(我觉得没有练习的算法学习都是空架子,因为大多时候看会了很可能还是写不出来,但是官方给出的参考答案补全,可以参考[《算法(第四版)》参考答案](https://github.com/reneargento/algorithms-sedgewick-wayne)开源项目)。但是事实上并不是这些书中所有的内容都值得参考,所以可以参照下面的学习方法: 《算法》的第二章排序介绍了时间复杂度为O(n^2)和O(logn)的排序算法,它并没有直接介绍时间复杂度为O(n)的桶排序、计数排序和基数排序,而是将它们放在了第五章的字符串排序中,我认为这部分并不好,所以在完成这一章的学习后,需要参考《Hello 算法》的第十一章或者《算法导论》的第八章,我认为参考前者更合适一些。 《算法》的第三章在介绍红黑树时,它写的是左倾红黑树(与2-3查找树同构),该数据结构是这本书的作者先前发表的一篇[论文](https://sedgewick.io/wp-content/themes/sedgewick/papers/2008LLRB.pdf),它是经典红黑树的变体,实现相对容易。不过,在Java语言中TreeMap的实现采用的经典红黑树(与2-3-4查找树同构),我认为如果要扩展学习经典红黑树的话需要结合《算法导论》的第十三章和TreeMap的源码,除此之外,暂时没有发现参考学习经典红黑书更合适的材料。 除此之外,《算法》中没有对动态规划和贪心算法的介绍,这一部分在《算法导论》的第十五章和第十六章有讲解,不过动态规划和贪心算法类的Leetcode题目在我看来还是比较难的,需要结合大量的练习才行。 以上,对于 **基础的算法学习** 就比较全面了,下面我们来讨论一些问题作为补充: #### 《算法导论》需要读吗? 我认为《算法导论》真的是非常合适的算法学习参考书,由于之前我也带着“黑皮书”读起来比较困难的想法,所以只把它作为了补充阅读,没有以它的内容为准,如果现在让我重新选择,我会把它作为主要参考书而其他作为补充阅读。 《算法导论》它**不局限于语言**,其中的代码内容是伪代码实现,所以任何语言的学习者都是合适的。而且,它会**用单独的章节来介绍算法中常用的策略**,如分治法等,此外在数据结构中创建哨兵节点的技巧也在链表章节中也描述。我认为它的前十六章加上第二十二章用来学习基础的算法已经足够了。开篇我说这本书像鸡尾酒,因为 **它还扩展了高级数据结构和更加深入的算法知识**,如斐波那契堆、van Emde Boas 树、数论算法和NP相关的知识等,所以,它的知识更加全面,面向的读者范围更广。我认为作为普通的算法学习者,一定要把握好学习的度,因为算法本身相对更加耗费脑力和时间,钻牛角尖式的学习在工作和生活间协调起来是不容易的,而且在算法导论中确实有一些复杂的证明和推导存在,可以选择性的跳过,因为我们的学习并非研究和探索,这样降低了难度也提高了学习效率。 #### 《Hello 算法》是怎样的一本参考书? 《Hello算法》是一本基础的算法书,它的作者是也是Leetcode上剑指Offer系列题解的作者,这本书的知识基本上覆盖了刷LeetCode所需要的知识,它在内容深度上没有做扩展,像红黑树这些,也正如它的前言所述:**它是一本能够让你避免读大部头便具备基本刷题能力的书**,如果大家在短时间内想补足算法知识的话,参考这本书足够了,但是深入的学习是必要且无法被替代的。 #### 对于只想刷题的同学该怎么学习? 我觉得可以直接参考高频题目的题单 **分类** 先刷起来,然后根据题目,发现缺少的知识进行补足。这样相对更加高效,因为Leetcode具有技巧性和规律性,结合大量的题目练习是最好的方式,反而如果先啃完大部头再回过头刷题可能效率不够高,而且这样也不能得到预期的收益,因为这些书它并不是教你如何刷题的。 *** 以上内容对于找到适合自己的算法学习路线我认为已经足够了,接下来是我在算法学习中实践过的学习方法: ### 艾宾浩斯学习法 我认为学习某项技能,不仅局限于算法的学习,最终目的在于形成对它的长期记忆,并不是仅仅保留印象,而形成长期记忆的方法也非常简单:即频繁而有效的重复刺激,像我们的母语和一些生活习惯(刷牙、打扮和系鞋带等)之所以不会忘记是因为我们每天都在反复的刺激大脑如何运用,乃至最后都形成了肌肉记忆。总之,**学习结合规律的复习,并归纳总结,便可以克服遗忘,达到温故知新的结果**。 > 艾宾浩斯遗忘曲线,即人对于知识的遗忘速度遵循 "先快后慢" 的原则。学得的知识在一天后,如不抓紧复习,很快就只剩下原来的 25%,而随着时间的推移,遗忘的速度会减慢,遗忘的数量也随之减少。 > > 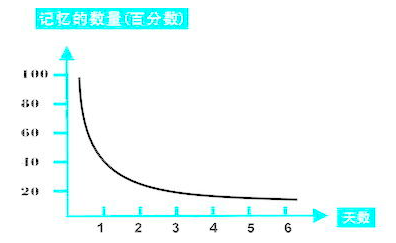 > > 如果想有效抵抗遗忘,最好的办法就是进行规律的复习(每 5 分钟、30分钟、12小时、1天、2天、4天、7天、15天、1个月、3个月、6个月)。 艾宾浩斯遗忘曲线是大家都熟悉的概念,但是我几乎没有发现我的同学采用类似的学习方法。如果不是在朋友的推荐下,我也不会去改变自己的学习方式,在我实践过之后,收获很大,所以也分享给大家,下面是部分我用来记录学习和复习的艾宾浩斯表格: 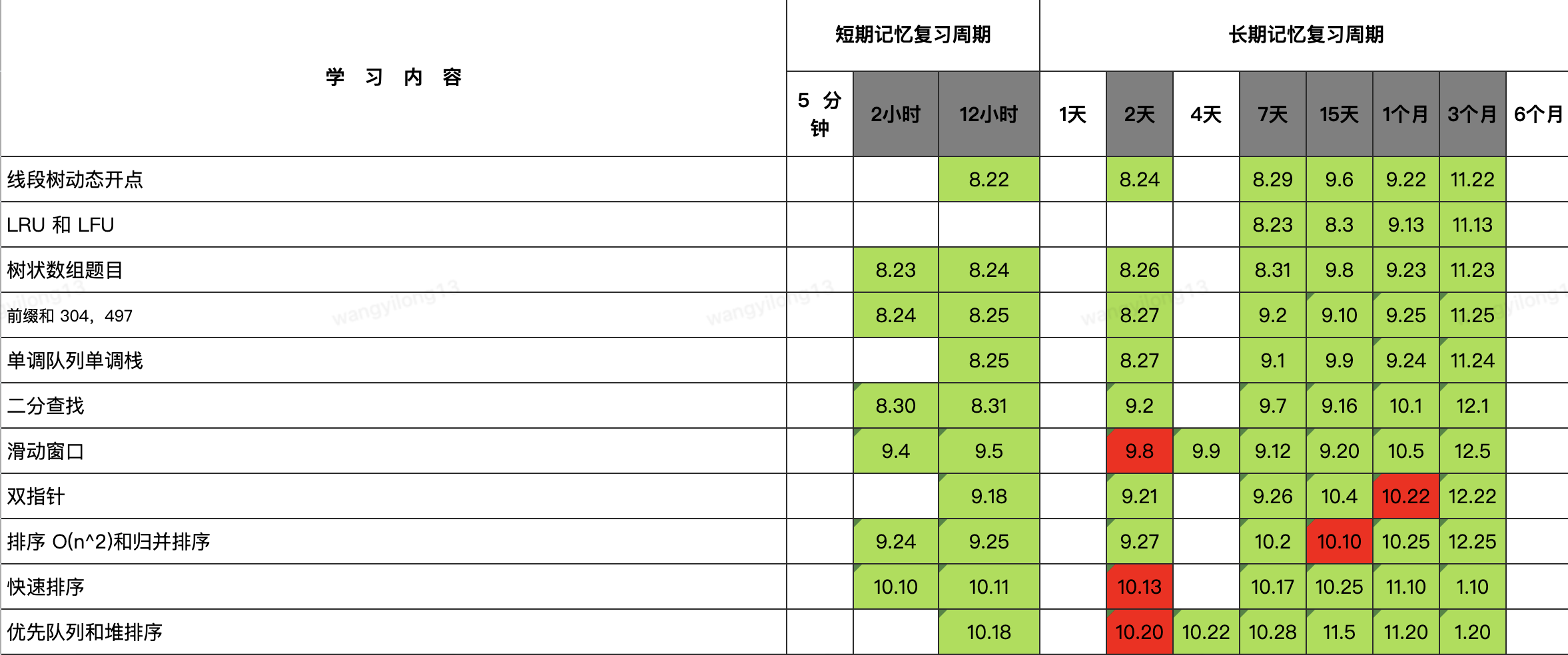 我并没有完全照搬它的复习时间,而是采用了2小时、12小时、2天、7天、15天、1个月和3个月这样的时间间隔,其中表格中记录的是学习日期,绿色表示按时完成复习,红色表示没有按时复习。 采用这个学习方法我认为需要始终坚持 **“循序渐进,按部就班”** 的学习理念,不能一时图快而在短时间内学习过多知识,否则它会带来长时间的复习压力,也不能采取断断续续学习几天就休息一阵子的方式,而是真正地让学习成为一种习惯,慢慢地积累达到知识稳步增长的目的,这更像是投资的复利。 这种学习方法完全打破了我之前“从来不复习,永远看新的”的学习方式,而且不复习经常会带来“这个东西我看过,但是我忘了”的困扰,导致最后学完什么都没有剩下的局面,并且从采用这个学习方法之后,以“手写线段树”为例,真得可以信手拈来,像“肌肉记忆”一样,所以规律的学习和复习是很有必要的。**需要注意的是**:这种学习方式需要耐心、毅力和自制力的辅助,并根据自身记忆情况进行合理的调整,达到合适的学习和复习模式,否则很容易在遇到长假休息时导致学习计划夭折。 ### Over 所有内容到这里就已经结束了,文末是一些优秀的参考文章和题单,希望能帮助大家在算法学习上少走一些弯路,最后祝大家学得开心\~ *** ### 巨人的肩膀 * [《Hello 算法》](https://www.hello-algo.com/) * 《算法(第四版)》 * 《算法导论》 * 《数据结构与算法之美》 * [GitHub - algorithms-sedgewick-wayne](https://github.com/reneargento/algorithms-sedgewick-wayne) * [GitHub - LogicStack-LeetCode](https://github.com/SharingSource/LogicStack-LeetCode) * [Github - LeetCode题单](https://github.com/FangYuan33/LeetCode) * [Leetcode - 论如何 4 个月高效刷满 500 题并形成长期记忆](https://leetcode.cn/circle/discuss/jq9Zke/)
上一篇:【报名!开年重磅好课】“走进京东——卓越研效架构师”研习营开课在即
下一篇:大文件上传实践分享
wy****
文章数
47
阅读量
38102
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
1. 为什么要分区?分区(partitions) 也被称为 分片(sharding),通常采用对数据进行分区的方式来增加系统的 可伸缩性,以此来面对非常大的数据集或非常高的吞吐量,避免出现热点。分区通常和复制结合使用,使得每个分区的副本存储在多个节点上,保证数据副本的 高可用。如下图所示,如果数据库被分区,每个分区都有一个主库。不同分区的主库可能在不同的节点上,每个节点可能是某些分区的主库,同时是
01
深入理解分布式共识算法 Raft
“不可靠的网络”、“不稳定的时钟”和“节点的故障”都是在分布式系统中常见的问题,在文章开始前,我们先来看一下:如果在分布式系统中网络不可靠会发生什么样的问题。有以下 3 个服务构成的分布式集群,并在 server_1 中发生写请求变更 A = 1,“正常情况下” server_1 将 A 值同步给 server_2 和 server_3,保证集群的数据一致性:但是如果在数据变更时发生网络问题(延迟
01
缓存之美:从根上理解 ConcurrentHashMap
本文将详细介绍 ConcurrentHashMap 构造方法、添加值方法和扩容操作等源码实现。ConcurrentHashMap 是线程安全的哈希表,此哈希表的设计主要目的是在最小化更新操作对哈希表的占用,以保持并发可读性,次要目的是保持空间消耗与 HashMap 相同或更好,并支持利用多线程在空表上高效地插入初始值。在 Java 8 及之后的版本,使用 CAS 操作、 synchronized
01
缓存之美:万文详解 Caffeine 实现原理(上)
由于神灯社区最大字数限制,本文章将分为两篇,第二篇文章为缓存之美:万文详解 Caffeine 实现原理(下)文章将采用“总-分-总”的结构对配置固定大小元素驱逐策略的 Caffeine 缓存进行介绍,首先会讲解它的实现原理,在大家对它有一个概念之后再深入具体源码的细节之中,理解它的设计理念,从中能学习到用于统计元素访问频率的 Count-Min Sketch 数据结构、理解内存屏障和如何避免缓存伪
wy****
文章数
47
阅读量
38102
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
01
深入理解分布式共识算法 Raft
01
缓存之美:从根上理解 ConcurrentHashMap
01
缓存之美:万文详解 Caffeine 实现原理(上)
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 wy****
wy**** 2024-03-04
2024-03-04 855浏览
855浏览






