您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
京东ES支持ZSTD压缩算法上线了:高性能,低成本
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
京东ES支持ZSTD压缩算法上线了:高性能,低成本
ya****
2024-01-08
IP归属:北京
980浏览
                  # 1 前言 在2022年10月份《[ElasticSearch降本增效常见的方法](http://sd.jd.com/article/6288?shareId=54564&isHideShareButton=1)》一文中曾提到过[zstd压缩算法](https://github.com/facebook/zstd)[1],一步一个脚印我们终于在京东ES上线支持了zstd;我觉得促使目标完成主要以下几点原因: 1. **Elastic官方原因**:zstd压缩算法没有在Elastic官方的开发计划中;Elastic的licenes变更,很多功能使用受限 2. **ES产品竞争力**:提升京东ES产品在业界的竞争力,两大云友商和其他大厂都在陆续支持,在对外比拼的时候,我们需要提升我们这方面的能力 3. **信创大背景**:我们需要对开源组件有更好的自主管控和建设能力 4. **京东零售ES与云ES产品融合**:有更好的机会去打磨我们的ES内核 5. **降本增效**:ztsd压缩算法,能够在降低存储成本的前提下,保证性能几乎不受损,写入性能还有所提升 # 2 测试结果 测试集群配置:4c8g; 3个数据节点; 测试索引设置:3主分片1副本 测试数据mapping: keyword字段14个,geo_point字段3个,integer字段2个,text字段1个,date字段:2个,ip类型字段1个,boolean字段1个 在考虑到读写性能和压缩比均衡的情况下,我们推荐使用jd_zstd(压缩等级3): * jd_zstd(压缩等级3)写入性能相对于best_compression**提升38.46%**,相对于lz**提升5.88%**; * jd_zstd(压缩等级3)存储相对于lz4**节省24%**,与best_compression基本持平,单位写的gb实际是要比best_compression的存储量小。 下表为es6.8.23版本,在cpu压测到100%时,不通压缩算法下**ES的bulk、termquery、rangequery、matchquery等TPS以及压缩比**测试结果: | <span style="white-space:nowrap;">压缩算法      </span> | <span style="white-space:nowrap;">bulk</span> | <span style="white-space:nowrap;">termquery</span>| <span style="white-space:nowrap;">rangequery</span> | <span style="white-space:nowrap;">matchquery</span> | 数据存储大小(580W条文档)segment forcemerge为1个 | 压缩率,基准为lz(ES默认为lz压缩算法) | | --------------------- | --- | --- | --- | --- | --- | --- | | lz4 | 34K | 7.7K | 790 | 450 | 13gb | - | | best_compression | 26K | 4.7K | 780 | 430 | 10gb | 76.9% | | jd_zstd(压缩等级3) | 36K | 5.4K | 790 | 450 | 10gb | 76.9% | | jd_zstd(压缩等级6) | 32K | 5.6K | 790 | 460 | 9.8gb | 75.38% | | jd_zstd(压缩等级9) | 25K | 5.5K | 790 | 450 | 9.8gb | 75.38% | **注意**⚠️:<span style="color: #f11374">测试数据仅供参考,实际情况与用户数据有关</span> # 3 适用场景 写多读少的场景,比如日志和监控场景。 # 4 使用方法 >`云上ES等待上线后,可以进行申请` 目前我们暂时只在内部泰山零售ES上线,支持7.X和6.8.23版本;后续会在云舰ES和公有云ES上线,由于licenes的限制,我们将只推出6.8.23版本。 **Q1: 如何申请?** **A1:** 内部用户:之前在泰山平台申请的杰斯ES,如果使用的是7.X和6.8.23,可以选择版本升级到最新版本。新建集群,直接提工单申请 **Q2 ztsd如何使用?** **A2:** 我们在ES中支持两种zstd压缩等级,用户可以根据自己的业务和数据特性选择合适的压缩等级; ES创建索引时指定index.codec:**jd_zstd**(压缩等级为3)或者**jd_zstd_6**(压缩等级为6)即可,其余没有其他任何特殊之处。 **注意**⚠️:index.codec的压缩算法不支持动态修改,必须创建索引时设定好。 ``` # 创建索引zstdtest 压缩等级为 3 PUT zstdtest { "settings": { "index": { "codec": "jd_zstd" } } } # 创建索引zstdtest_6 压缩等级为 3 PUT zstdtest_6 { "settings": { "index": { "codec": "jd_zstd_6" } } } ``` # 5 技术实现 首先我们介绍下ES与Lucene的关系;如下图所示,在集群层面:一个ES集群由多个节点组成。数据层面:1个索引是由多个分片组成的,一个分片可以看是一个Lucene实例;一个分片包含多个segement,一个segement即一组数据的最小单元,包含很多的数据文件。 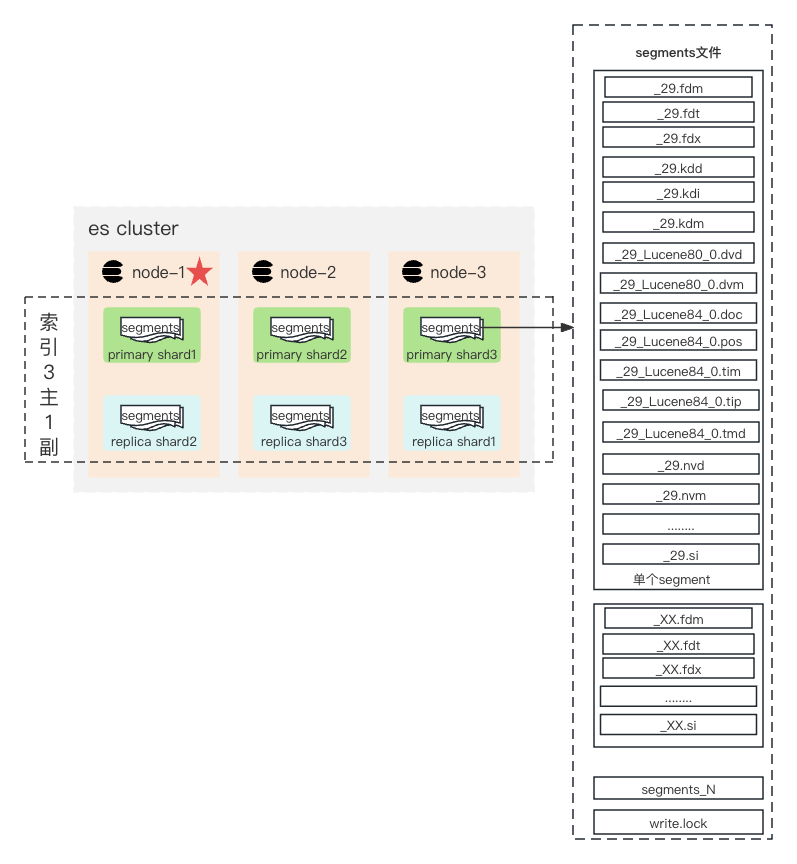 ## 5.1 Lucene文件 lucene[2]的数据文件主要由以下文件组成: | <span style="white-space:nowrap;">NAME        </span> | <span style="white-space:nowrap;">Extension   </span> | Brief Description | | --- | --- | --- | | Segments File | segments_N | 存储已经落盘数据的位移提交点 | | | Lock File | write.lock | 锁文件,防止多个 IndexWriters 写同一个文件 | | Segment Info | .si | 存储单个segment的metadata | | Compound File | .cfs, .cfe | 复合文件主要是为了减少文件描述符;在IndexWriterConfig可以配置是否生成复合索引文件;复合文件实质是索引文件的组合,意思是无论是否设置了使用复合文件,总是先生成非复合索引文件,随后在flush阶段,才将这些文件生成.cfs、.cfe文件,其中.liv、.si所以文件不会被组合到.cfs、.cfe中。 | | Fields | .fnm | 存储有关字段的信息 | | Field Index | .fdx | 指向字段数据的指针;存储了原文数据在原文存储文件中的位置信息,建立起了doc id和原文之间的联系,以支持快速访问和定位 | | Field Data | .fdt | 文档的存储字段 | | Term Dictionary | .tim | term词典,存储term信息 | | Term Index | .tip | Term词典的索引 | | Frequencies | .doc | 文档列表,其中包含每个term以及频率 | | Positions | .pos | 存储term在索引中出现位置的位置信息 | | Payloads | .pay | 存储附加的每个位置元数据信息,如字符偏移和用户payloads | | Norms | .nvd, .nvm | 编码文档和字段的长度以及权重提升因子 | | Per-Document Values | .dvd, .dvm | 编码额外的评分因子或其他每个文档的信息 | | Term Vector Index | .tvx | 矢量数据的索引文件;将偏移量存储到文档数据文件中 | | Term Vector Data | .tvd | term矢量数据 | | Live Documents | .liv | 有关哪些文档处于存活的信息;当发生标记删除时会产生该文件 | | Point values | .dii, .dim | 保留索引点,如果存在 | 上述的文件大致可以分为以下几类: - **行存相关文件**:主要包括原文存储文件.fdt和原文索引文件.fdx。用户写入的原始数据都被存储于.fdt,占比是最大的,Lucene在原文存储上支持LZ4和ZIP(best_compression)压缩。在写入数据时,ES把doc原始数据的整个json结构体当做一个string,存储为_source字段,因此原文存储文件.fdt中_source字段占比最大;部分场景为了节省磁盘存储,直接将该字段关闭,数据查询时仍可通过ES的docvalue_fields获取所有字段的值; ``` "_source": { "enabled": false } ``` **注意**⚠️:关闭_source后, update, update_by_query, reindex等功能无法正常使用,因此有update等需求的索引不能关闭_source. - **列存相关文件**:.dvd文件,常用于OLAP分析,ES使用列存来支持sorting, aggregations和scripts功能。不同文档Document中的同一列(Field)数据相邻存放,加速列聚合分析性查询。相邻每列类型相同,在存储的时候可以进行统一性的编码优化,提高压缩率,减少存储磁盘空间的占用。ES中字段使用doc_values字为true,即为开启列存储。 - **索引相关文件**:主要文件包括字典数据文件.tim和倒排索引.doc文件。ES依靠分词器产生倒排索引,从而具备强大的全文检索能力。索引配置分词器后,将从摄入文档数据中提取分词信息并存储于.tim文件。同一列的分词信息相邻存放,按块组织;.doc文件也被称为"倒排拉链表",记录每一个词项所关联的文档id列表,实现词项到文档的快速倒排查找。倒排索引也会进行压缩,其压缩算法主要有Frame Of Reference、Roaring Bitmap和fst等。 - **向量数据文件**:矢量索引tvx和矢量数据.tvd文件,支持以图搜图,和音频的查找等。通过对摄入实体进行矢量化,然后使用向量搜索算法进行检索。相关向量搜索算法有HNSW[3],近似向量搜索[knn](https://www.elastic.co/guide/en/elasticsearch/reference/current/knn-search.html#approximate-knn)[4];elastic公司在今年5月份左右推出用于人工智能的 Elasticsearch [相关性引擎ESRE](https://mp.weixin.qq.com/s/awxgy9pSgv0lVPTfvzfxBw)[5]。 zstd主要压缩为**行存储相关文件.fdm、.fdt 和.fdx**;如下代码块为压缩文件对比,可以看出在不同的压缩算法中,这几个文件的大小是不同的。 ``` # 为了节省篇幅部分文件省略 ## lz4压缩算法索引testlz4 0 号分片 total 2.4G -rw-r--r-- 1 admin admin 1.2K Nov 16 16:19 _32.fdm -rw-r--r-- 1 admin admin 1.3G Nov 16 16:19 _32.fdt -rw-r--r-- 1 admin admin 76K Nov 16 16:19 _32.fdx -rw-r--r-- 1 admin admin 85M Nov 16 16:21 _32.kdd -rw-r--r-- 1 admin admin 149M Nov 16 16:21 _32_Lucene80_0.dvd ......................................... -rw-r--r-- 1 admin admin 401 Nov 16 16:21 segments_b -rw-r--r-- 1 admin admin 0 Oct 16 16:05 write.lock ## best_compression压缩算法索引 testbestcompression 0 号分片 total 1.9G -rw-r--r-- 1 admin admin 287 Nov 16 17:01 _2b.fdm -rw-r--r-- 1 admin admin 781M Nov 16 17:01 _2b.fdt -rw-r--r-- 1 admin admin 17K Nov 16 17:01 _2b.fdx -rw-r--r-- 1 admin admin 85M Nov 16 17:03 _2b.kdd -rw-r--r-- 1 admin admin 148M Nov 16 17:03 _2b_Lucene80_0.dvd ......................................... -rw-r--r-- 1 admin admin 401 Nov 16 17:03 segments_a -rw-r--r-- 1 admin admin 0 Oct 16 16:27 write.lock ## zstd压缩等级为3 索引testzstd3 0 号分片 total 1.9G -rw-r--r-- 1 admin admin 286 Nov 16 17:26 _8e.fdm -rw-r--r-- 1 admin admin 758M Nov 16 17:26 _8e.fdt -rw-r--r-- 1 admin admin 15K Nov 16 17:26 _8e.fdx -rw-r--r-- 1 admin admin 84M Nov 16 17:29 _8e.kdd -rw-r--r-- 1 admin admin 148M Nov 16 17:29 _8e_Lucene80_0.dvd -rw-r--r-- 1 admin admin 3.5K Nov 16 17:29 ......................................... -rw-r--r-- 1 admin admin 402 Nov 16 17:29 segments_9 -rw-r--r-- 1 admin admin 0 Nov 15 16:50 write.lock ## zstd压缩等级为6 索引testzstd6 0 号分片 total 1.9G -rw-r--r-- 1 admin admin 286 Nov 16 16:56 _29.fdm -rw-r--r-- 1 admin admin 742M Nov 16 16:56 _29.fdt -rw-r--r-- 1 admin admin 9.8K Nov 16 16:56 _29.fdx -rw-r--r-- 1 admin admin 86M Nov 16 16:58 _29.kdd -rw-r--r-- 1 admin admin 148M Nov 16 16:58 _29_Lucene80_0.dvd ......................................... -rw-r--r-- 1 admin admin 412 Nov 16 16:58 segments_a -rw-r--r-- 1 admin admin 0 Oct 16 16:04 write.lock ## zstd压缩等级为9 索引testzstd9 0 号分片 total 1.9G -rw-r--r-- 1 admin admin 286 Nov 16 17:21 _gp.fdm -rw-r--r-- 1 admin admin 738M Nov 16 17:21 _gp.fdt -rw-r--r-- 1 admin admin 13K Nov 16 17:21 _gp.fdx -rw-r--r-- 1 admin admin 85M Nov 16 17:23 _gp.kdd -rw-r--r-- 1 admin admin 149M Nov 16 17:23 _gp_Lucene80_0.dvd ......................................... -rw-r--r-- 1 admin admin 402 Nov 16 17:23 segments_8 -rw-r--r-- 1 admin admin 0 Nov 15 16:50 write.lock ``` ## 5.2 ES侧实现 理论上来说index.codec支持的压缩算法最好下沉到lucene代码中,目前我们并没有维护lucene代码,因此我们直接ES侧面代码实现。 zstd[1]算法是基于C++实现,而ES是基于java编写,因此借助开源的力量,引入zstd-jni来实现zstd压缩能力. ``` # zstd_jni版本 1.5.5-1 api "com.github.luben:zstd-jni:${versions.zstd_jni}" ``` 在ES代码中编写自定义的index.codec;扩展CompressionMode压缩模式,自定义实现ZstdCompressor压缩和ZstdDecompressor解压缩方法,可以在这设定zstd的压缩等级以及控制读写数据块大小;最后通过java的spl机制实现加载我们自定义的压缩算法实现类 在server/src/main/resources/META-INF/services/org.apache.lucene.codecs.Codec文件中定义如下. ``` org.elasticsearch.index.codec.custom.ZstdCodec ``` **注意**⚠️:由于ES节点启动的时候,有security检查机制,因此我们需要在server/src/main/resources/org/elasticsearch/bootstrap/security.policy文件中添加代码权限授权策略 ``` grant codeBase "${codebase.zstd-jni}" { permission java.lang.RuntimePermission "loadLibrary.*"; permission java.lang.RuntimePermission "libzstd.*"; }; ``` # 6 参考文档 [1] https://github.com/facebook/zstd [2] https://lucene.apache.org/core/8_11_2/core/org/apache/lucene/codecs/lucene87/package-summary.html#package.description [3] Y. Malkov, D. Yashunin,Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs(2016), IEEE Transactions on Pattern Analysis and Machine Intelligence [4] https://www.elastic.co/guide/en/elasticsearch/reference/current/knn-search.html#approximate-knn [5] https://mp.weixin.qq.com/s/awxgy9pSgv0lVPTfvzfxBw [6] https://mp.weixin.qq.com/s/_dmJwEpl6CWtv_-MLdvR7g
上一篇:一文让你对mysql索引底层实现明明白白
下一篇:京东ES支持ZSTD压缩算法上线了:高性能,低成本
ya****
文章数
3
阅读量
2798
作者其他文章
01
京东ES支持ZSTD压缩算法上线了:高性能,低成本
1 前言在2022年10月份《ElasticSearch降本增效常见的方法》一文中曾提到过zstd压缩算法[1],一步一个脚印我们终于在京东ES上线支持了zstd;我觉得促使目标完成主要以下几点原因: 1. Elastic官方原因:zstd压缩算法没有在Elastic官方的开发计划中;Elastic的licenes变更,很多功能使用受限2. ES产品竞争力:提升
01
京东ES支持ZSTD压缩算法上线了:高性能,低成本
1 前言在2022年10月份《ElasticSearch降本增效常见的方法》一文中曾提到过zstd压缩算法[1],一步一个脚印我们终于在京东ES上线支持了zstd;我觉得促使目标完成主要以下几点原因: 1. Elastic官方原因:zstd压缩算法没有在Elastic官方的开发计划中;Elastic的licenes变更,很多功能使用受限2. ES产品竞争力:提升
01
ElasticSearch集群灾难:别放弃,也许能再抢救一下
1 前言Elasticsearch作为一个分布式搜索引擎,自身是高可用的;但也架不住一些特殊情况的发生,如:集群超过半数的master节点丢失,ES的节点无法形成一个集群,进而导致集群不可用;索引shard的文件损坏,分片无法被正常恢复,进而导致索引无法正常提供服务本地盘节点,多数据节点故障,旧节点无法再次加入集群,数据丢失针对上述的情况,今天来聊一聊相关的解决方案。2 基础知识2.1 集群经典架
ya****
文章数
3
阅读量
2798
作者其他文章
01
京东ES支持ZSTD压缩算法上线了:高性能,低成本
01
ElasticSearch集群灾难:别放弃,也许能再抢救一下
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 ya****
ya**** 2024-01-08
2024-01-08 980浏览
980浏览






