



一、什么是 MTTR ?
当系统出现系统故障时,我们需要通过一些指标来衡量故障的严重程度和影响范围。其中MTTR(Mean Time To Repair 名为平均修复时间)是一个非常重要的指标,它可以帮助我们了解修复系统所需的平均时间。花费太长时间来修复系统是不可取的,尤其对于京东这样的企业来说更是如此。如果MTTR过长,可能会导致用户结算卡单、影响公司收入损失等严重后果。因此,为了确保系统的稳定性和可靠性,我们需要尽可能地缩短MTTR。
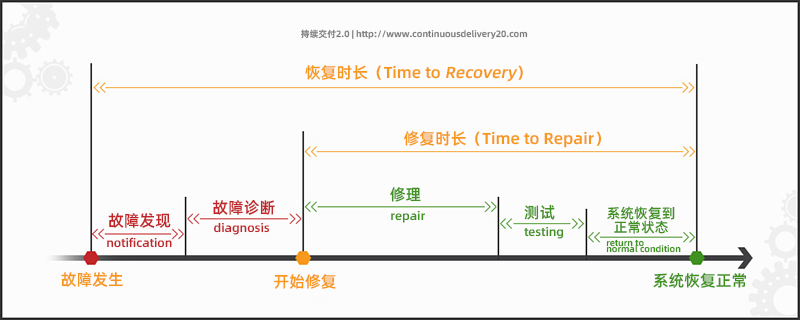
要计算MTTR,就是将总维护时间除以给定时间段内维护操作的总数,MTTR计算公式:

二、如何缩短MTTR
了解MTTR对于任何组织来说都是一个非常重要的工具,因为它可以帮助我们更好地响应和修复生产中的问题。在大多数情况下,组织都希望通过内部维护团队来降低MTTR,这需要必要的资源、工具以及软件支持。
那么,您可以采取哪些步骤来缩短组织的MTTR呢?最好的起点是了解MTTR的每个阶段并采取措施减少每个阶段的时间。具体来说,我们可以考虑以下几个方面:
1、问题发现时间:监控报警识别故障
对于发生故障后技术人员识别问题的时间段,我们可以通过建立报警系统来缩短MTTR识别时间。通过实时监测系统的运行情况,及时发现并触发报警机制,可以帮助我们在最短的时间内定位问题,并采取相应的措施进行修复。
我们可以通过设置合理的阈值和规则,过滤掉那些不必要的告警信息,从而避免告警噪音对开发运维团队的干扰,让他们更加专注于真正的问题。
1.1、UMP监控
- 通过UMP实现3个黄金监控指标(可用率、调用量、TP99)。
在配置报警机制时,我们可以综合考虑可用率、TP99以及调用量等因素来进行评估。通过这些指标的综合评估,可以帮助我们更全面地了解系统运行情况,从而及时发现潜在的问题并采取相应的措施。
建议在进行报警配置时,可先采取较为严格的策略,即先紧后松,逐步调整到最佳状态。这样可以确保在最开始阶段就能够及时发现问题,避免出现重大故障。但随着系统的逐渐稳定,我们也可以根据实际情况适当放宽报警阈值,以提高系统的可用性和效率。
需要注意的是,在进行报警配置时,我们需要结合具体的业务场景和系统特点来进行调整和优化。不同的系统可能存在不同的风险点和瓶颈,因此我们需要根据实际情况来制定相应的报警策略,以保证系统的稳定性和可靠性。
critical告警方式:咚咚、邮件、即时消息(京ME)、语音
可用率:(分钟级)可用率 < 99.9% 连续 3 次超过阈值则报警,且在 3 分钟内报一次警。
性能:(分钟级)TP99 >= 200.0ms 连续 3 次超过阈值则报警,且在 3 分钟内只报一次警。
调用次数:当方法调用次数在 1 分钟的总和,连续 3 次大于 5000000 则报警,且在 3分钟内只报一次警
warning告警方式:咚咚、邮件、即时消息
可用率:(分钟级)可用率 < 99.95% 连续 3 次超过阈值则报警,且在 30 分钟内报一次警。
性能:(分钟级)TP99 >= 100.ms 连续 3 次超过阈值则报警,且在 30 分钟内只报一次警。
调用次数:当方法调用次数在 1 分钟的总和,连续 3 次大于 2000000 则报警,且在 3 分钟内只报一次警- 如果UMP是定时任务,最重要的一点就是确定好监控时段。只有正确地配置了监控时段,才能确保UMP在预计时间段内正常执行,这样一旦UMP未能在预计时间段内执行,就会自动触发报警机制,及时发现并解决问题。
1.2、报警要 快、准、少
在处理报警信息时,我们的关键不在于数量的多少,而在于信息的准确性和完整性。我们的小组每天都会接收到几百个报警信息,你是否有足够的精力和时间去查看每一个呢?你能确保每一个都得到了关注吗?
因此,我们需要对业务影响进行评估,并根据情况设定适当的报警频率。特别是对于那些被视为"关键语音"的报警信息,我们更应该第一时间发现并进行处理。只有这样,我们才能保证在面对紧急情况时,能够迅速、准确地作出反应,最大程度地减少可能的影响。
1.3、细节决定成败
- 如果报警信息的响应时间较长,我们需要检查一下团队的值班响应机制是否正常。我们需要确保告警信息是否能够有效地传达给正确的人,以便及时解决问题。
- 关于报警信息的日清日结,我们应该建立相应的处理机制,确保每条报警信息都能得到妥善处理。如果无法做到日清日结,我们需要深入分析原因,并采取相应的措施加以改进。
- 在处理报警信息时,我们需要深入分析其根本原因。只有找到问题的根源,才能从根本上解决问题。
- 如果报警频繁但一直未被处理,我们需要认真思考这个报警是否有必要的存在。有时候,一些报警可能是由于误报或者无关紧要的问题引起的,这时候我们需要对这些报警进行筛选和排除。
- 如果出现问题后发现对应的UMP或其他环节的报警信息未添加,我们需要仔细检查是否还有其他核心环节也漏添加了。如果有漏添加的情况,我们可以采用工具扫描来发现。
- 对于之前出现的报警信息,我们不能凭经验认为是某原因导致的。历史经验并不一定准确可靠,只有通过调查和分析相关日志才能得出真正的结论。
- 在配置报警信息时,我们需要认真考虑其合理性。建议先采取紧后松的方式逐步调整到最佳状态。这样可以避免一开始就出现过多或过少的报警信息,从而提高工作效率和准确性。
2、缓解系统问题时间:故障响应机制、快速止血
为什么我们需要缓解系统问题时间,而不是仅仅定位问题呢?这是因为在处理系统问题时,仅仅定位问题只是解决问题的一部分。更重要的是,我们需要尽快缓解系统问题,以避免其对业务的影响进一步扩大。
为了提高问题处理效率,我们需要从以下三个方面入手:
- 完善指挥体系和角色分工:一个完善的指挥体系和明确的角色分工可以有效地提高故障处理的效率。在处理问题时,各个角色需要明确自己的职责和任务,并协同配合,共同解决问题。
- 完备的技术层面故障隔离手段:在技术层面上,我们需要采取一些故障隔离手段,比如通过DUCC开关等方式来避免过度回滚代码。这样可以更加快速止血(DUCC开关秒级,如机器多回滚需要5-10分钟)
- 经过足够的演练的故障处理机制保障:最后,我们需要建立一个经过足够演练的故障处理机制保障,包括UAT环境测试、捣乱演练、应急预案SOP等。这样可以在真正出现问题时,快速响应并有效解决问题。
总之,为了提高问题处理效率,我们需要采取一系列措施来缓解系统问题时间,而不仅仅是定位问题。只有这样,才能真正保障系统的稳定性和可靠性。
2.1、执行故障应急响应机制
无论一个组织规模有多大,其最重要的特征之一就是应对紧急事件的能力。在面对紧急情况时,需要有一套完善的应急预案和实战训练机制,以确保能够快速、有效地应对各种突发状况。为了实现这一目标,我们需要从以下几个方面入手:
- 建立完备的训练和演习流程:建立和维护一套完备的训练和演习流程是非常重要的。这需要一批对业务熟悉、专注投入的人来负责制定和执行相关计划。同时,还需要根据实际情况定期进行演习和模拟测试,以确保应急预案的有效性和可操作性。
- 先把问题上报组内、发挥团队的力量:在处理紧急事件时,应该先把问题上报组内,并充分发挥团队的力量。通过集思广益的方式,可以更加快速地找到问题的根源,并采取相应的措施进行解决。
- 合理判定问题严重程度:在判断问题的严重程度时,需要具备良好的工程师判断力,并保持一定的冷静。
总之,为了提高组织的应对紧急事件的能力,我们需要建立完备的训练和演习流程,充分发挥团队的力量,并合理判定问题的严重程度。只有这样,才能真正保障组织的稳定性和可靠性。
关键角色分工
- 故障指挥官。这个角色是整个指挥体系的核心,他最重要的职责是组织和协调,而不是执行,比如负责人、小组长、架构师。
- 沟通引导。负责对内和对外的信息收集及通报,但是要求沟通表达能力要比较好,比如产品经理。
- 执行者。参与到故障处理中的各类人员,真正的故障定位和业务恢复都是他们来完成的,比如小组核心研发、运维同事等。
流程机制
- 故障发现后,On-Call同事或者小组长,有权召集相应的业务开发或其它必要资源,快速组织会议。
- 如果问题疑难,影响范围很大,这时可以要求更高级别的介入,比如部门负责人等。
反馈机制
反馈当前处理进展以及下一步Action,如果中途有需要马上执行什么操作,也要事先通报,并且要求通报的内容包括对业务和系统的影响是什么,最后由故障指挥官决策后再执行,避免忙中出错。没有进展也是进展,也要及时反馈。对于技术以外的人员反馈,如客服等等。一定不是用技术术语,而是以尽量业务化的语言描述,并且要给到对方大致的预期,比如我们正在做什么,大致多长时间会恢复,如果不能恢复,大约多长时间内会给一个反馈等等。
2.2、快速止血应急预案
基本原则: 在故障处理过程中采取的所有手段和行动,一切以恢复业务为最高优先级,恢复现场止血方案高于寻找故障原因。
- 面对问题时,你的第一反应可能是立即开始故障排查过程,试图尽快找到问题根源,这是错误的!不要这样做。正确的做法是:缓解系统问题是第一要务,尽最大可能让系统恢复服务。
- 快速止血而不是根源排查。首先只需要粗定位问题大概即可,然后通过一些应急预案措施(DUCC开关降级、限流、回滚等)来恢复现场。
- 线上问题首先思考,是不是上线、业务修改配置等变更导致,拉齐信息。
- 发布期间开始报错,且发布前一切正常?什么都不用管,先回滚再说,恢复正常后再慢慢排查。
- 应用已经稳定运行很长一段时间,突然开始出现进程退出现象?很可能是内存泄露,默默上重启大法。
- 如何确认是不是上线引入的问题呢?同比下上线前(比如昨天、上周)是否也存在一样问题。如果也存在说明跟上线没关系。看看昨天的日志,日志是最靠谱的。可用率会欺骗大家(因为你可能今天治理了可用率,之前可用率是100%,但不一定是真的100%)
- 业务、产品、研发多路并行
- 快速定位问题时乃应该及时保存问题现场,比如先把JSF服务摘除,但机器保留1台(别重启),保留JVM堆栈信息以便后续进行问题根源分析。
2.3、充分利用现有工具,智能分析定位问题
2.2.1、针对TP99高,定位难:
调用关系复杂,难以快速定位性能瓶颈。可通过工具事先梳理清楚服务间复杂的依赖关系,聚焦瓶颈服务的核心问题,而不是出现问题才去整理链路。
- 如泰山 故障转移等:智能告知这个告警与哪个因素最相关,功能试用中。
- 全域看板,集成UMP采集点,可快速定位是哪一个环节TP99高
- 长链路应用,配置泰山雷达图。
- Pfinder分布式调用链路,作为分析基础
2.2.2、针对调用量突然高
可通过JSF》流量防护》应用和接口》别名&方法名 定位上游哪个应用调用量情况,再采取对应措施,比如更上游沟通,限流策略等
2.2.3、线程分析、JVM、火焰图CPU采样等
泰山平台》故障诊断》在线诊断
2.2.4、业务问题
根据logbook查找,这个没什么好讲的。
通过标准化程序来指导训练技术人员,可以减少解决问题所需的时间。在相同的故障情况下,拥有适当的文档和应急预案SOP可以让您快速检查可能导致故障的所有因果因素。
三、总结
在线上问题修复后,编写COE(Center of Excellence)复盘报告是非常重要的一步。在这个报告中,我们可以回顾整个问题的处理过程,思考如果当时做了哪些可以更快缩短MTTR(Mean Time To Repair)的方法。
具体来说,我们可以从以下几个方面入手:
- 分析问题出现的原因:首先需要对问题进行深入的分析,找出问题的根本原因。只有找到问题的根源,才能够采取有针对性的措施来解决问题,从而缩短MTTR。
- 总结经验教训:在分析问题的过程中,我们需要总结经验教训,并提出改进建议。这些建议可以包括优化流程、提高效率、加强培训等方面的内容,但不需要列一堆Action,根据2/8法则抓重点即可。
- 举一反三,杜绝下次发生类似问题:我们需要将本次问题的处理经验和教训应用到其他类似的问题中,避免类似问题的再次发生。
总之,通过深入分析问题、找出根本原因、总结经验教训以及举一反三,我们可以有效地缩短MTTR,保障系统的稳定性和可靠性。
参考:
SRE Google运维解密
持续交付2.0






