



一、痛点
你是否曾遇到过以下问题?
- API错误码形同虚设,无法提供有效帮助?
- API错误码文档晦涩难懂,别说其他团队,连团队内同事都看不明白?
- API错误码定义混乱,缺乏一致性?
- 链路上的错误码信息无法正确传递?
二、什么是错误码
根据亚马逊官方文档的定义,错误码是通过对错误进行抽象,帮助用户或开发者识别和理解异常性质的代号。错误码与具体错误不是一对一的关系,而是错误类型的一种抽象表示。尽管错误码在系统中只是一个小模块,但它是不可或缺的。
错误消息应该帮助用户轻松并快速地理解并解决API 错误,以下是一些设计原则:
1. 不要假设用户非常了解你的API。用户可能是客户端开发者、运维人员、IT人员或者APP的普通用户。
2. 不要假设用户了解服务实现的细节或熟悉错误上下文(例如日志分析)。
3. 如果可能,应构建错误消息,以便技术用户(但不一定是API的开发人员)可以对错误进行响应并更正。
4. 保持错误信息简短。如果需要,提供链接以便用户能够提出问题或获取更多信息。
错误码的设计应当直接解答核心问题:错误码的设计首要明确指出哪里出了问题(系统),其次细化到系统内部具体的模块或功能点。这种精细化的信息有助于快速定位和解决问题。
三、错误码设计原则
错误码的设计原则:快速追踪溯源、简单、描述清晰。
- 快速追踪溯源:一个好的错误码应该使开发者和运维人员能够迅速识别错误的根源(比如APP看到用户提示错误信息,见名思意即可快速定位是ABCDEF哪个系统的什么问题),避免在不同系统或文档之间来回查找。
- 简单清晰易记:有效的错误码设计需要考虑其可读性和可比性,错误码应该有一个清晰的结构和逻辑,方便在代码中进行比较和处理。
- 信息描述清晰:很多错误码message描述连团队内同事都看不懂,何况调用你API的开发人员呢,所以要把message描述的清晰明了。
这些设计原则有助于构建一个高效、可靠且易于使用的错误码。通过遵循这些原则,可以确保错误码在实际应用中发挥出最大的价值。
四、API-错误码设计
在服务器接口设计中,定义接口错误码是至关重要的一环。通常,服务端会设定一系列的错误码,以便于指导接口调用者或用户采取恰当的操作。这些错误码可能涉及诸如参数非法、配置出错、内部异常等多种情况,为用户提供明确的反馈。
1)Response响应
在Response响应方面,我们的 API 将返回一个结构化的 JSON 对象,该对象包含以下三个关键属性:
code(状态码): 这是一个标准化的数字代码,用于表明请求的处理结果。每个状态码都对应一个特定的情况,使得客户端可以快速识别请求的状态。message(状态码描述): 该字段提供了一个简短且清晰的描述,解释了状态码的含义。这将帮助客户端了解请求成功与否,如果出现问题,它将提供足够的信息以指导进一步的行动。data(响应数据): 这是实际的响应内容,包含了请求成功时所需的数据。这个数据对象的结构将根据具体的 API 调用而有所不同,但它总是以一种易于客户端解析和使用的格式提供。
| 字段 | 类型 | 描述 |
| code | String | 业务状态码 |
| message | String | 错误码描述,需要描述清晰明了 |
| data | Object | 封装对象 |
案例如下:
public class PromiseResponse<T> {
/**
* 错误编码
*/
private String code;
/**
* 提示信息
*/
private String message;
/**
* 业务数据
*/
private T data;
{
"code": 200,
"message": "成功",
"data": {
"transferTime": "Mon Jul 29 00:01:00 CST 2024",
"endOrderTime": "Mon Jul 29 18:00:00 CST 2024",
"outStoreTime": "Tue Jul 30 00:00:00 CST 2024",
"jitEndDate": "Tue Jul 30 00:00:00 CST 2024",
"storeDeliveryHandoverTime": "Tue Jul 30 01:00:00 CST 2024",
"deliveryTime": "Thu Aug 01 22:00:00 CST 2024",
"routeProductionResult": {
"ruleType": null,
"ruleName": null
},
"promiseControlResult": {
"controlResultCode": 2,
"suspendReasonCode": 0,
"suspendReason": null,
"abnormalLink": 0,
"abnormalLinkName": null,
"abnormalReason": null
}
}
}
2)错误重试
当发生可以重试的错误码时客户端应该以指数级增长的间隔来重试请求。除非文档中进行了说明。对于其他错误,重试操作可能并不可行,请先确保请求是幂等的并查看错误消息以获得指引。
3)错误传播
如果 API 服务依赖于其他服务,则不应盲目地将这些服务中的错误传播给客户端。翻译错误时,有如下建议:
- 错误码转换,比如下游返回错误码A,需要转换你对外的错误码B
- 错误码描述可追加下游错误码描述信息,让链路错误码描述清晰可见
- 最终对用户肯定是需要隐藏下游实现细节和机密信息,让用户体验良好的错误提示信息
4)❌不合理案例
❌不合理的API错误码,不合理地方如下:
1、错误码无规则:比较混乱。比如错误码一会1,一会-50,-1等,没有规则
2、错误码过细:错误码定义过细过多、过度随意,将会导致调用方对错误处理的逻辑复杂,无法很好的对错误码进行转义或收敛。。比如入参错误定义了N个错误码,其实定义一个入参错误码即可,错误码描述可以描述具体的错误码信息。
3、错误码描述不清晰:一堆英文,他人看不懂

5)✅行业案例
业界错误码的规范很多,但是这些规范各不相同,甚至很多点相悖(比如Google紧密依赖于HTTP状态码)
5.1)京东云错误码
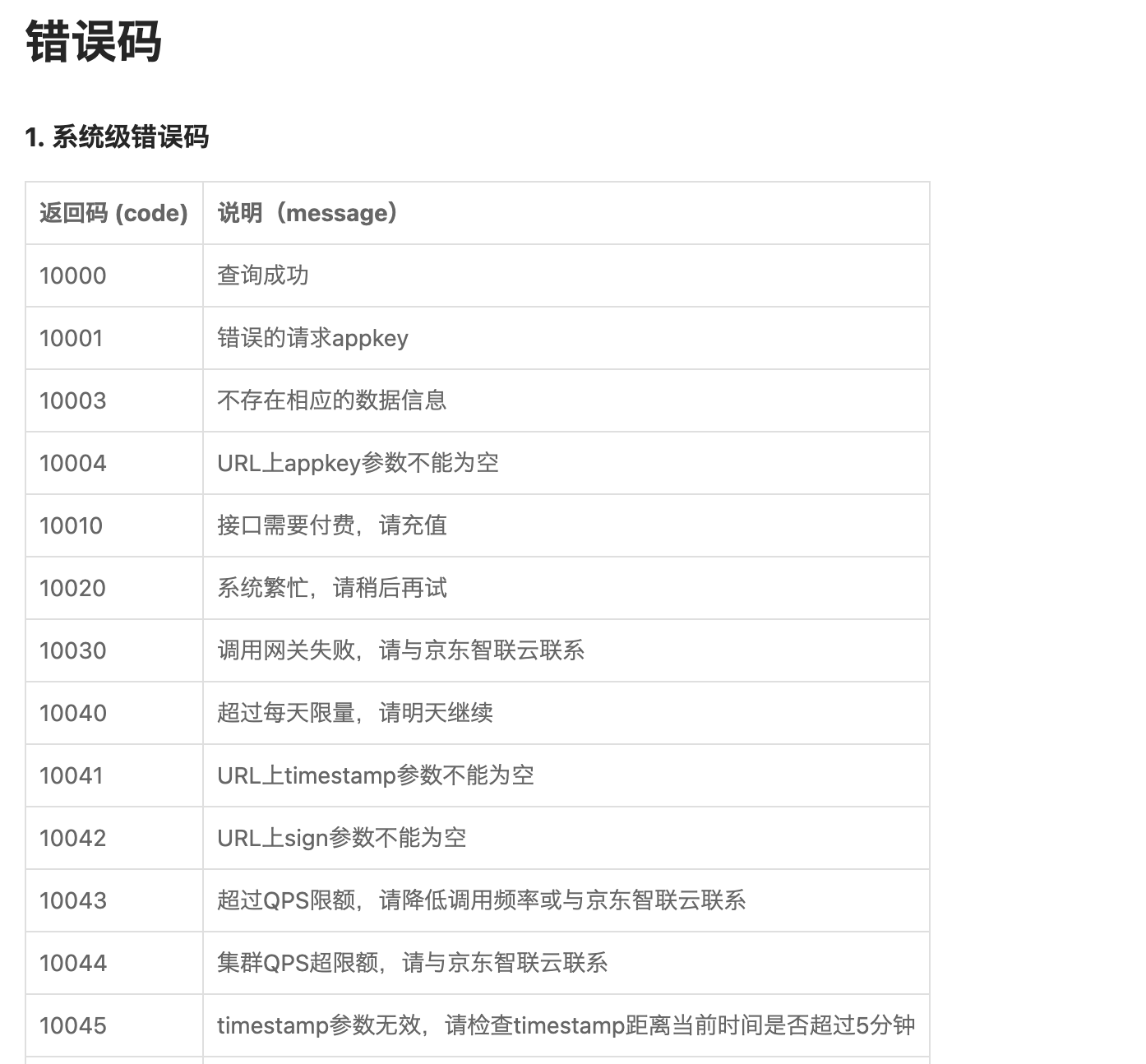
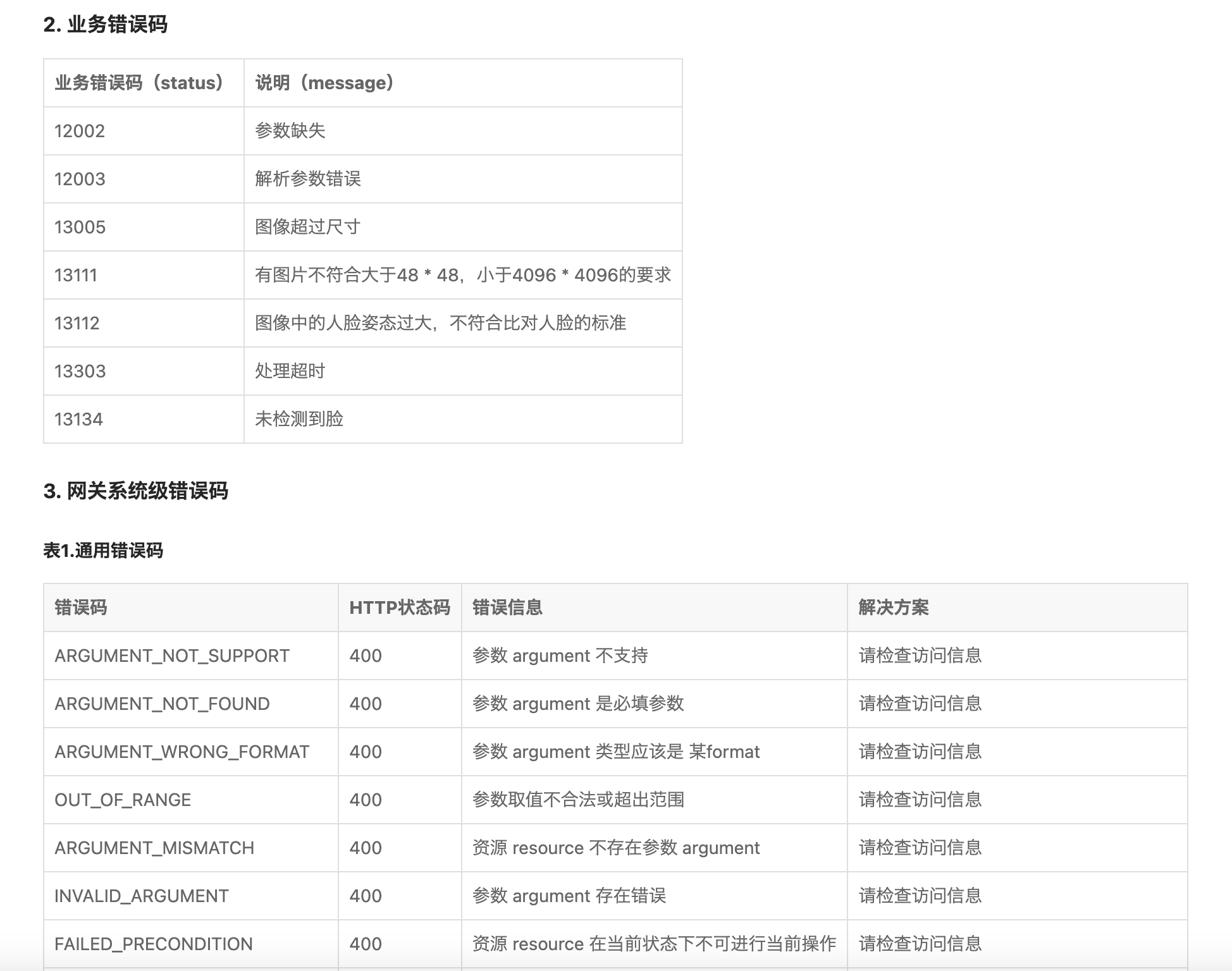
5.2)谷歌 API 错误码定义
谷歌API的错误码设计紧密依赖于HTTP状态码,采用全数字的错误码定义方式。然而,这种设计缺乏明确的错误分类体系,导致其快速识别和自解释能力相对较弱。
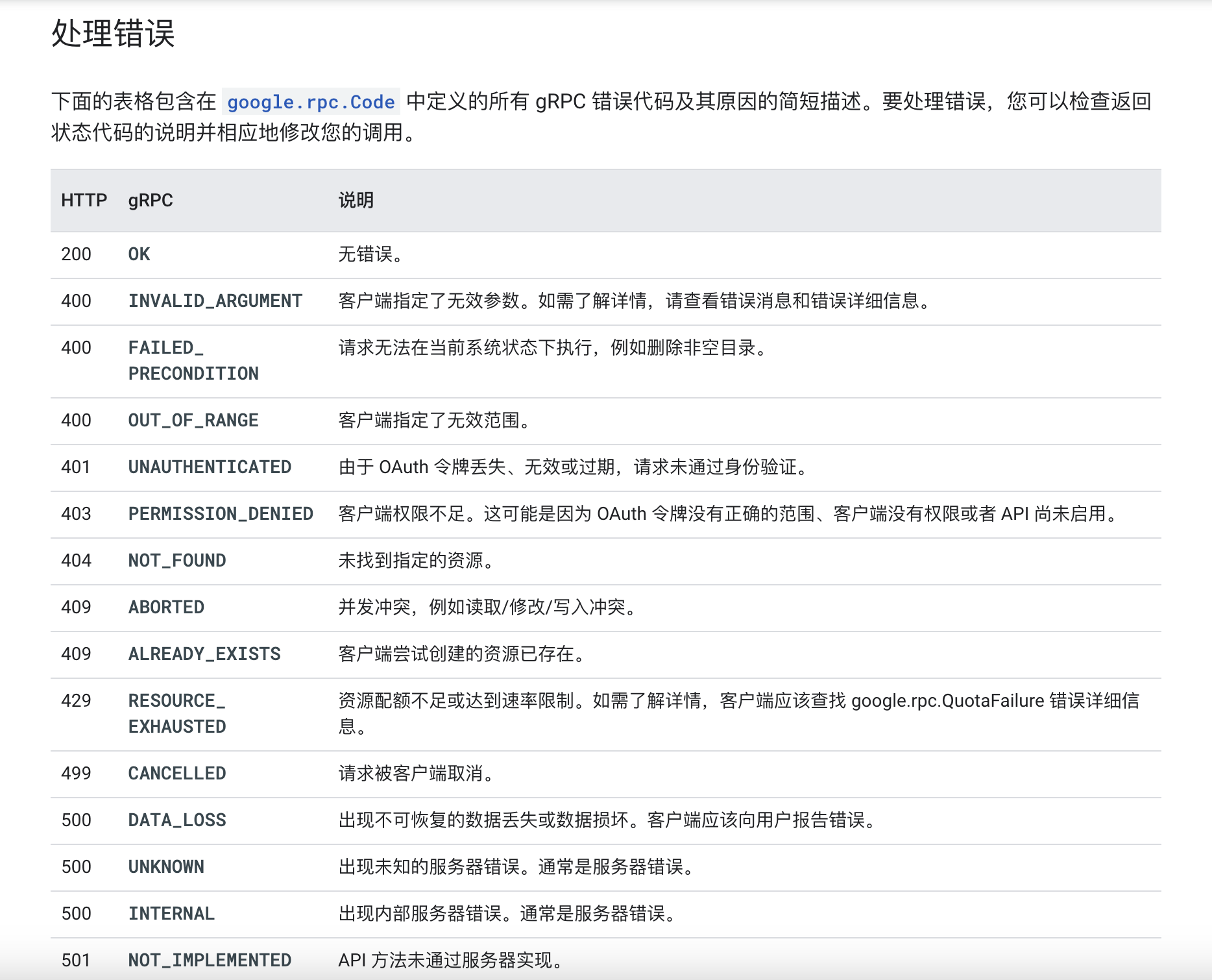
五、错误码传递
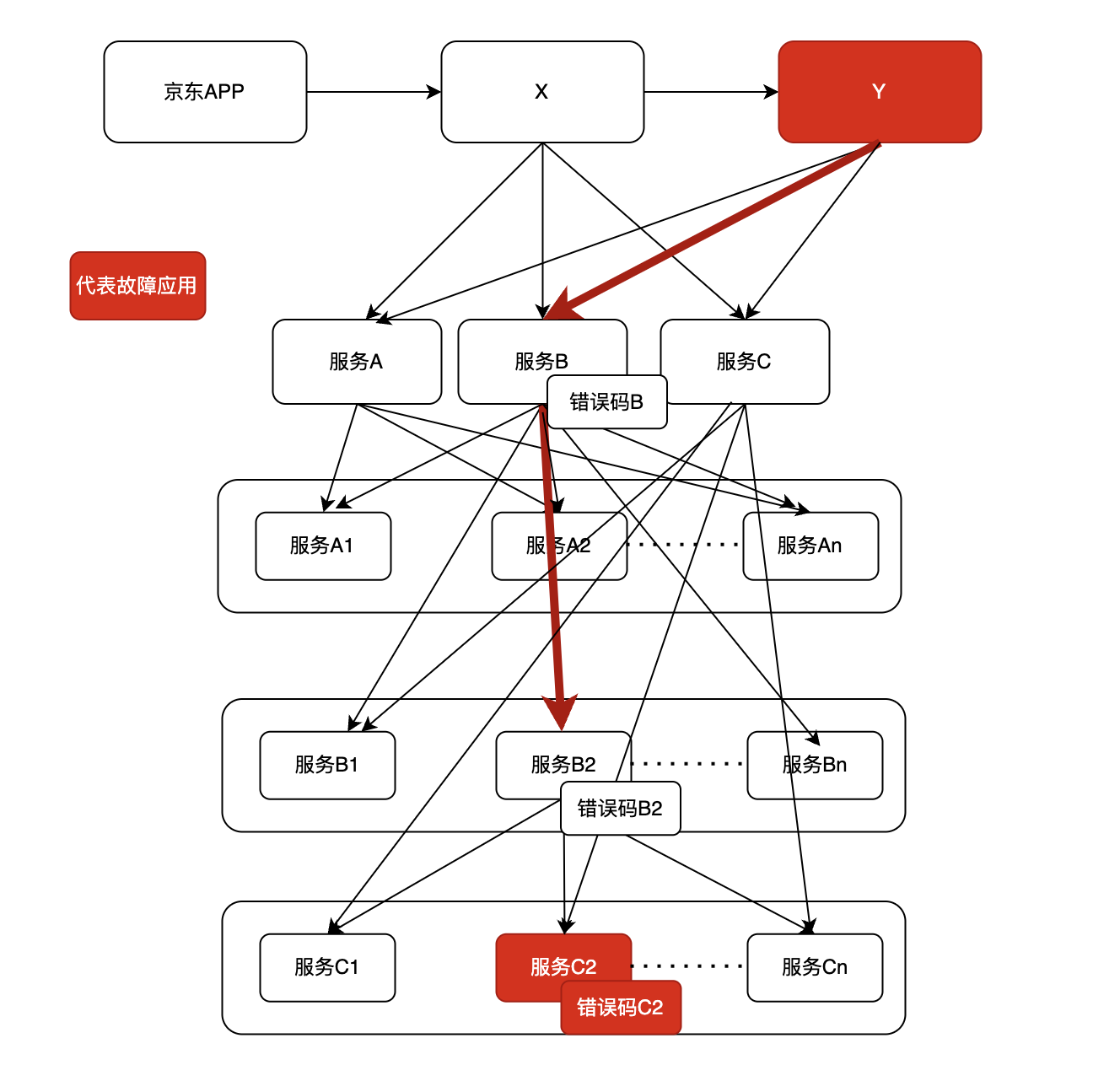
1)现在场景链路错误码信息
现有应用基本都是没有错误码传递功能,比如下图 Y应用出现故障,需要排查对应的依赖服务ABC,服务B返回的是服务B自定义的错误码B,但通过B是无法快速定位故障应用是C2。服务B经过各种排查,最终定位是服务B2的问题,服务B2通过错误码B2也无法快速定位是故障应用C2,继续每个应用排查,最终定位是服务C2错误。
2)错误码传递(转换)
接收下层模块发来的错误码A,错误码A是当下层模块有故障分支时生成的;然后将自身生成的错误码B和所接收到的错误码A合成错误码AB,将错误码AB传递给上层模块。
接收单元,用于接收下层模块发来的错误码A,错误码A是当下层模块有故障分支时生成的;
合成单元,用于将自身生成的错误码B和所接收到的错误码A合成错误码AB;
发送单元,用于将所述错误码AB传递给上层模块。
错误码在传递的过程中携带各层模块的故障分支信息,这样,根据错误码就可以确定错误码的传递路径,以便精确的定位故障错误原因,提高可维护性。
团队日常咨询案例
❌错误码设计---未传播错误码
案例:冷链外单无妥投时间,目前链路是A---->B---->C系统。但错误码是各自封装,没有把根本原因传播出去,而是各自加工,导致最终看到的原因跟真实的原因千差万别。导致整个链路牵扯 业务方--->A研发---->B研发---->C研发---->C业务同事 总共5个环节,如下图:

具体咨询链路如下
1、业务联系A系统开发,告知系统异常提示如下
2、联系B系统小蜜,小蜜根据订单查询调用纯配接口出入参查询日志:
3、B系统联系C系统研发,周知出入参
4、C同事联系 C业务,告知路线没配,信息如下:{"code":0,"data":[],"message":"派送范围维护->未查找到配置数据XXXXX","tid":44845519852540539}
现状:整个链路牵扯ABCD系统研发业务,沟通成本大(技术&业务),效率低
改进方案:✅错误码信息--传播错误码信息
推动错误码封装,错误信息传递功能,让最终A系统用户清晰明了根本原因(D系统)是什么。减少ABCD中间过程,A直接联系D,直接可见即所得。
1、如果api在翻译错误时,需要把底层根本原因返回上去,比如上面案例,把没有妥投日期的根本原因【派送范围维护->未查找到配置数据XXXX","tid":44845519852540539】周知
2、改造后链路 A业务方---->C业务同事 总共2个环节(改造前5个环节),因为界面提示错误信息,所见即所得,减少了中间环节。提升了业务效率,减少了研发内部中间环节的排查成本。

六、【探讨章节】全链路错误码系统设计
前面介绍了API的错误码设计及错误码传递,本章节探讨全链路错误码如何串联起来,不一定对,只是个人的思考,并且实践起来也是比较困难的不太现实
1)痛点:全链路排查问题慢
在京东复杂的系统架构中,故障诊断往往像是在迷宫中寻路。想象一下,一个由多达20+个相互依赖的系统组成的服务链路,从入口到底层的第N个服务,每个系统都是潜在的故障点。当前,一旦系统出现问题,都是上游拉群,定位问题拉下游N个系统,线上语音讨论是哪个出现的问题故障导致的,整个流程可能需要耗费长达1-2个小时甚至更长时间才能追踪到问题实际出现在M系统上。这个过程不仅耗时,而且效率低下。
现状故障处理流程:

现有系统交互图如下:
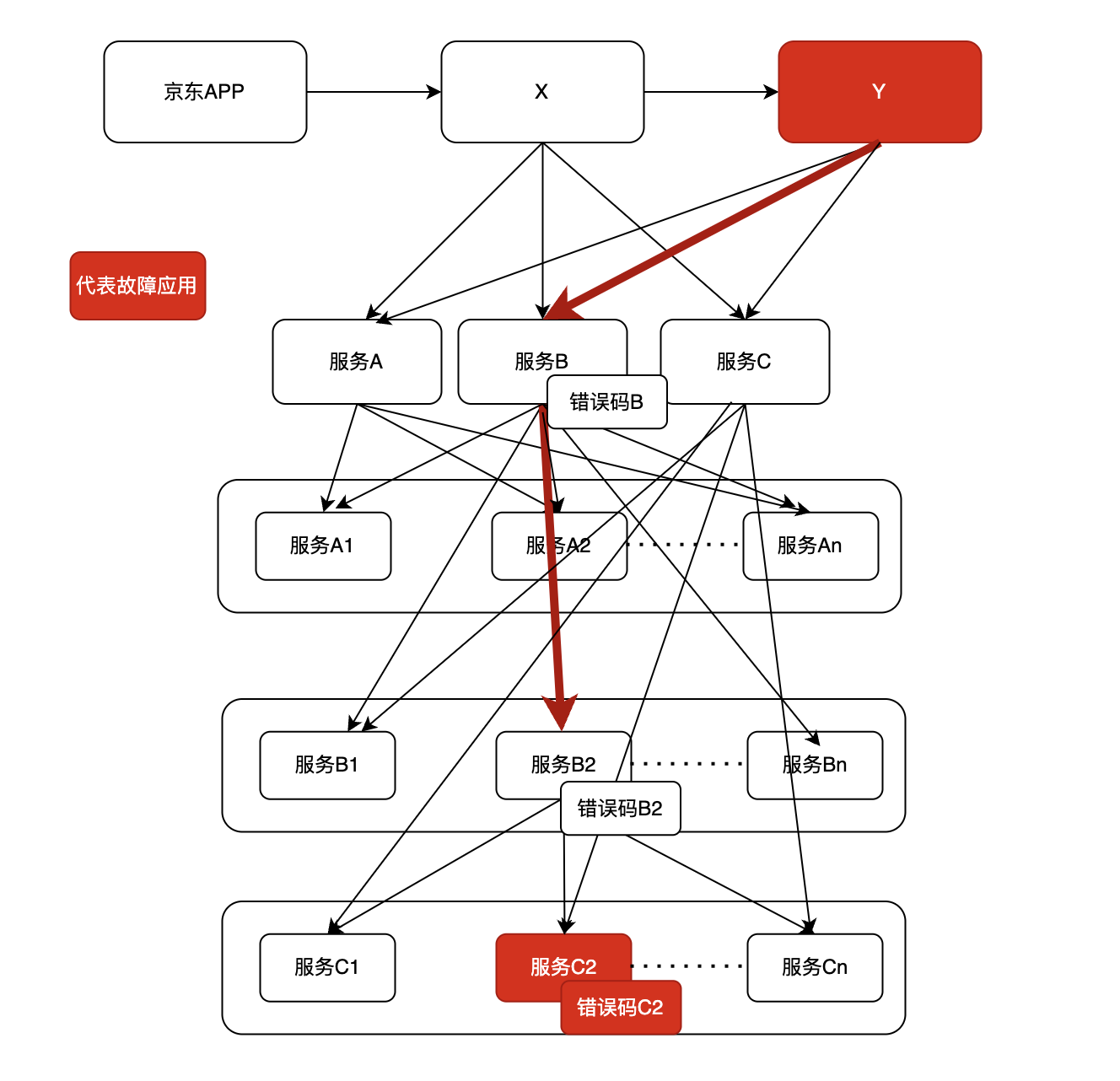
在这种复杂系统架构中,目前故障诊断的技术面临多个挑战和缺点,主要包括:
1、时间消耗长、效率低下:当系统出现问题时,故障诊断需要逐个检查各个系统,需要长时间才能定位到问题所在的系统,这直接影响了故障恢复时间和系统的整体可用性。
2、复杂性管理不足:在多个相互依赖的系统中,即使是小问题也可能迅速演变成复杂问题,现有的技术似乎没有很好地管理这种复杂性。
3、信息孤岛:系统间可能存在信息隔离,导致故障信息不能快速传递,增加了诊断时间。
4、依赖专业知识:可能过度依赖工程师的专业知识和经验进行故障排查,这不仅效率低,而且不利于知识传承和团队协作。
5、缺乏自动化:听起来这个过程很大程度上依赖于手动操作,缺乏自动化工具来快速识别和定位大概是哪个系统的问题。
API中如何设计一个号的错误码,链路调用错误码如何传递,线上故障如何通过错误码快速定位链路某个系统或者某个功能问题点
2)设计思想
如下图:如果服务C2有故障,则通过全链路traceId可快速查看Y的故障对应的错误码,根据错误码定位是因为C2应用故障导致的。
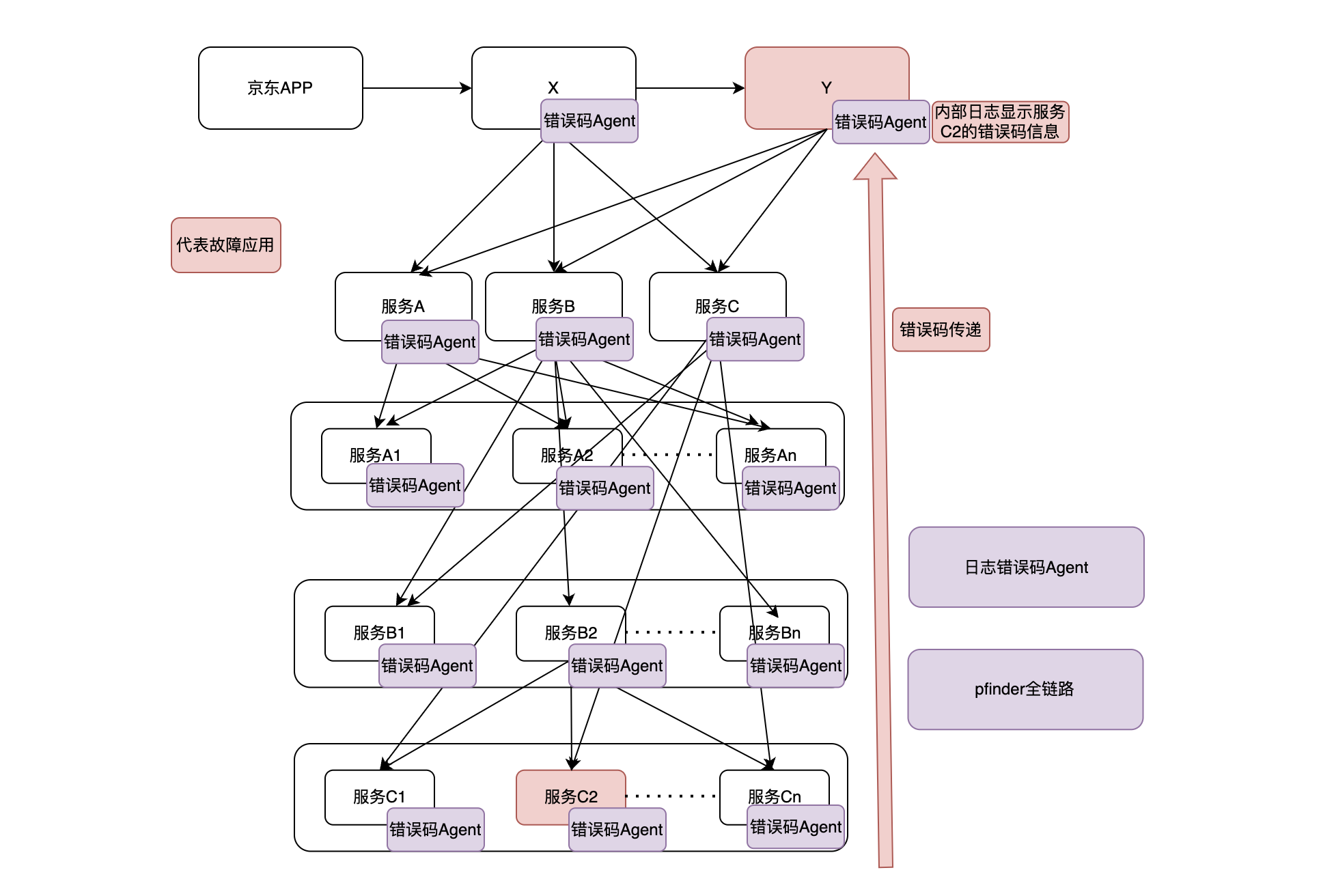
日志错误码架构思路如下:
参考【泰山】--》【业务监控】每个应用无需接入错误码Agent,错误码Agent其实就是日志采集。跟业务监控一样,你只需要把你应用的业务指标错误信息打印到日志中即可,比如服务ABCDEF链路都打印日志,相关的应用logbook接入TOPIC-1,则通过TOPIC-1可拿到整个链路traceId以及每个应用的错误码信息(如果有)。
日志格式:traceId|应用错误码|错误码信息描述
1677474.49460.17235995037011944.3460091.193151.9140|WMS_10001|调用Promise(系统B)系统异常,缺少预计妥投时间
1677474.49460.17235995037011944.3460091.193151.9140|PROMIES_10002|Promise调用路由系统(系统C)异常,缺少预计妥投时间
1677474.49460.17235995037011944.3460091.193151.9140|ROUTE_20003|派送范围维护->未查找到配置数据,请排查派送范围维护,派送地址:四川-达州市-宣汉县-龙泉土家族乡,产品:生鲜特殊次晨,生鲜特惠次晨,生鲜标快
这样通traceId(17235995037011944.3460091.193151.9140)可拿到链路中的AB(B1,B2,B3)C系统的错误码,其中B1/B2/B3等系统无错误,则可不打错误码。
具体系统设计图如下:
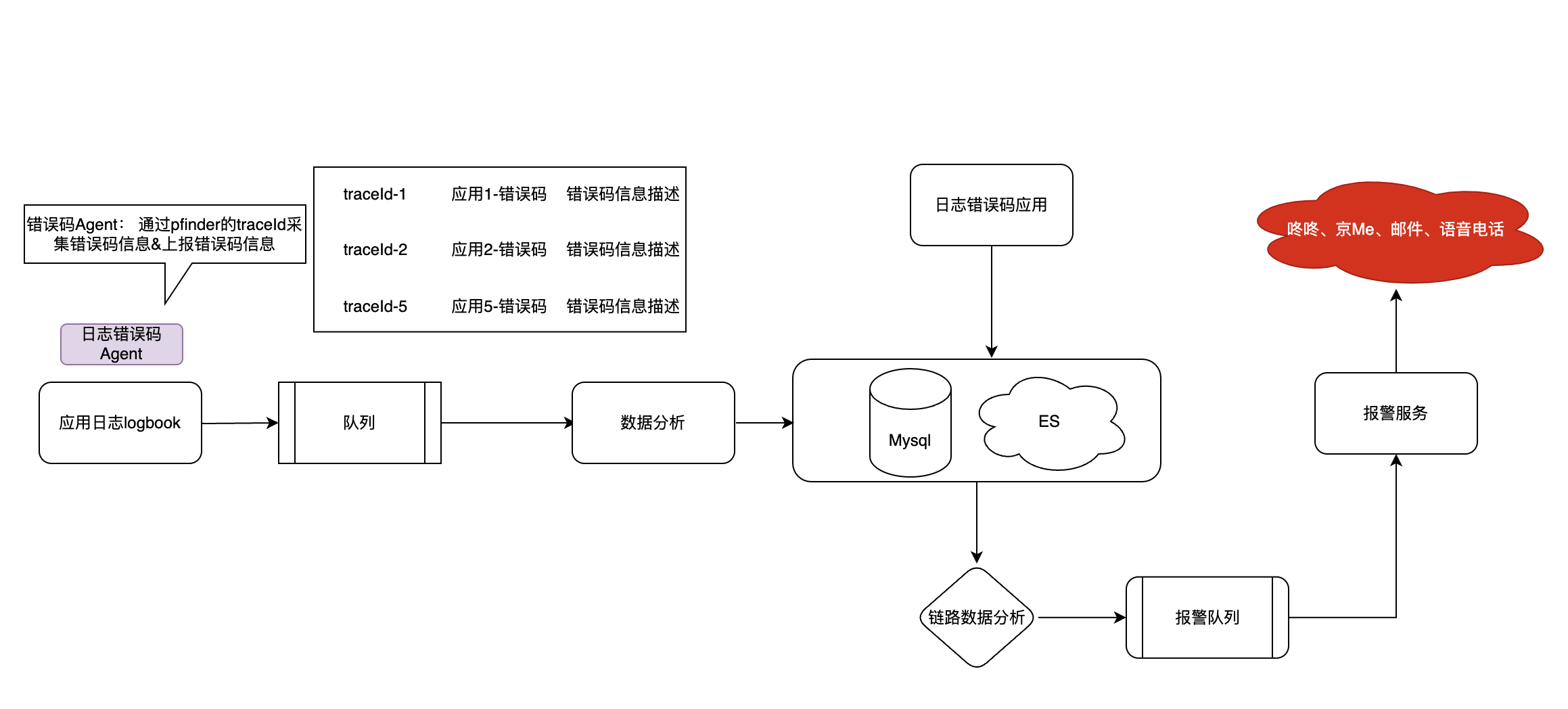
1)在应用程序中,使用日志打印功能记录接口对应的错误码及其详细信息,确保每次接口调用出现错误时都能捕获到相关数据。
2)错误码Agent会从日志中收集这些错误码信息,并将其发送到消息队列中,以便后续的处理和分析。
3)消费消息队列中的错误码信息,进行深入的数据分析,包括但不限于错误码的频率、分布和趋势等。
4)根据traceId,追踪并收集整个链路的数据,并将其存储到MySQL或Elasticsearch等数据库中,以便进行全链路的错误码信息查询和分析。
5)在应用程序的界面上,用户可以通过输入对应的traceId来查询整个链路的错误码信息,方便快速定位问题。
6)系统会自动对错误码信息进行实时的数据分析和趋势预测,帮助团队及时发现和解决潜在的故障。
7)如果错误码信息被识别为异常或高优先级事件,系统将自动触发报警服务,通过多种方式(如咚咚、电子邮件、京Me等)通知相关干系人。对于紧急情况,系统还可以通过电话等方式直接联系一线人员,确保问题得到及时处理。
3)挑战性:链路改造范围广
全链路错误码系统设计需要对现有系统进行大范围改造,确保每个系统都能记录和传递错误码。这不仅涉及大量的开发工作,还需要跨团队的协调和配合。此外,系统之间的日志格式和错误码标准需要统一,确保数据的可追溯性和一致性。
七、总结
设计一个好的API错误码是一个具有挑战性的任务,但它对于提高系统的可维护性和用户体验至关重要。本文抛砖引玉,希望提供的思路和实践能够帮助你在设计API错误码时更加得心应手。
如本文里面信息不对请指正,如有更好的知识点,欢迎评论交流完善补充。谢谢!
参考文献:
1、京东云错误码:https://docs.jdcloud.com/cn/face-compare/api/error-code
2、Google错误码:https://cloud.google.com/apis/design/errors?hl=zh-cn






