



1 SPI的概念
API
API在我们日常开发工作中是比较直观可以看到的,比如在 Spring 项目中,我们通常习惯在写 service 层代码前,添加一个接口层,对于 service 的调用一般也都是基于接口操作,通过依赖注入,可以使用接口实现类的实例。
简单形容就是这样的:
图1:API
如上图所示,服务调用方无需关心接口的定义与实现,只进行调用即可,接口、实现类都是由服务提供方提供。服务提供方提供的接口与其实现方法就可称为API,API中所定义的接口无论是在概念上还是具体实现,都更接近服务提供方(实现方),通常接口与实现类在同一包中;
SPI
如果我们将接口的定义放在调用方,服务的调用方定义一个接口规范,可以由不同的服务提供者实现。并且,调用方能够通过某种机制来发现服务提供方,通过调用接口使用服务提供方提供的功能,这就是SPI的思想。
SPI 的全称是Service Provider Interface,字面意思就是服务提供者的接口,是由服务提供者定义的接口。
图2:SPI
服务提供方按接口规范实现服务,服务调用方通过某种机制为这个接口寻找到这个服务, SPI的特点很明显:接口的定义(调用方提供)与具体实现是隔离的(服务提供方提供),使用接口的实现类需要依赖某种服务发现机制。
通过对比,我们可以看出接口在API与SPI中的含义还是有很大的不同,总的来说,API 中的接口是更像是服务提供者给调用者的一个功能列表,而 SPI 中更多强调的是,服务调用者对服务实现的一种约束。
2 为什么要使用SPI
- 面向接口编程:面向对象的设计与编程中,我们经常强调“依赖抽象而不是具体”,这样做就是为了实现高内聚、低耦合,提供代码灵活性和可维护性等等。
- 提供标准标准但没有具体实现的业务场景:SPI 机制的使用场景就是没有统一实现标准的业务场景。一般就是,服务调用方有定义好的标准接口,但是没有统一的实现,需要服务提供方提供其具体实现。
- 解耦:SPI 机制优势就是低耦合。将接口的定义以及具体实现分离,可以实现运行时根据业务实际场景启用或者替换具体实现类。
3 Java中如何使用SPI
接口定义、服务实现这些我们都轻车熟路,调用方直接依赖接口不依赖具体实现,这是依赖倒置原则,我们在Spring项目中使用API时,会使用Spring的依赖注入(DI)来实现“服务发现”,同样地,SPI的重点也是如何让调用方发现接口的具体实现,也就是上文提到的某种服务发现机制。
SPI的服务发现机制是由ServiceLoader提供,ServiceLoader是Java在JDK 6中引进的新特性,它主要是用来发现并加载一系列的service provider。当服务的提供者,提供了服务接口的一种实现之后,只需要在jar包的META-INF/services/目录里同时创建一个以服务接口命名的文件,该文件的内容就是实现该服务接口的具体实现类。而当外部程序装配这个模块的时候,就能通过该jar包META-INF/services/里的配置文件找到具体的实现类名,并加载实现类,完成依赖的注入,这就是Java SPI的服务发现机制。
下面就结合一个示例来具体讲讲。若有这样一个需求,需要使用一个接口来完成内容查找服务,接口的具体实现交给其他服务提供方,实现可能是基于文件系统的查找,也可能是基于数据库的查找。
(1)定义接口
作为服务调用方,需要先定义一套接口规范,用来规范之后的服务提供方按规范来实现接口。这样,不管是谁提供的实现方法,调用方都可以按相同的方式来调用接口。
创建一个项目search-standard,提供一个查找服务标准接口,先定义调用方的内容查找方法:
package com.gwz.spi.learn;
import java.util.List;
// 查找服务接口
public interface Search {
// 按关键字查询内容方法
String searchDoc(String keyword);
} 这个接口就是给服务提供方来实现的,将它打包发布mvn clean install,确保maven仓库中有该jar包,之后提供者在项目中就可以引入这个 jar 包了。
(2)服务实现
制定并发布完标准接口后,我们假设第一个服务提供方提供了一种文件查找的实现。新建项目search-file,并引入刚才发布的标准接口jar包:
<dependency>
<groupId>com.gwz.search</groupId>
<artifactId>search-standard</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>实现定义好的接口:
package com.gwz.file.search;
import com.gwz.spi.learn.Search;
public class FileSearch implements Search {
@Override
public String searchDoc(String keyword) {
return "文件查找:" + keyword;
}
}并在项目的resources的目录下,创建META-INF/services目录,然后以前面定义的接口名com.gwz.spi.learn.Search创建文件,并在文件中写入实现类的全限定名。
一个服务方的简单实现就完成了,用maven打成 jar 包,发布到maven之后就可以提供给调用方使用了。
接着,按上述实现方式,再创建一个项目search-database使用数据库的实现接口:
package com.gwz.database.search;
import com.gwz.spi.learn.Search;
public class DatabaseSearch implements Search {
@Override
public String searchDoc(String keyword) {
return "数据库查找:" + keyword;
}
}同样,打包发布后就可以提供给调用方使用了。
(3)服务发现
接下来关键的一步就是服务发现,服务发现需要依赖ServiceLoader的使用。创建一个新项目search-sever,引入上面打好的两个提供方的 jar 包。
<dependencies>
<dependency>
<groupId>com.gwz.search</groupId>
<artifactId>search-file</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.gwz.search</groupId>
<artifactId>search-database</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>虽然每个服务提供者对于接口都有不同的实现,但是作为调用者来说,它并不需要关心具体的实现类,我们要做的是通过接口来调用服务提供者实现的方法。
下面,就是关键的服务发现环节,使用ServiceLoader来加载具体的实现类,调用方只需调用对应接口方法即可。
package com.gwz.search.impl;
import com.gwz.spi.learn.Search;
import java.util.ServiceLoader;
public class SearchDoc {
public static void main(String[] args) {
new SearchDoc().searchDocByKeyWord("hello world");
}
public void searchDocByKeyWord(String keyWord) {
ServiceLoader<Search> searchServiceLoader = ServiceLoader.load(Search.class);
for (Search search : searchServiceLoader){
String doc = search.searchDoc(keyWord);
System.out.println(doc);
}
}
}测试结果:
可以看到,通过定义的Search发现了两个实现类。整段代码中没有出现过具体的服务实现类,操作都是通过接口调用。
4 Java SPI原理
了解了SPI的工作流程,我们应该有以下疑问:
- 为什么要在服务提供方的
META-INF/services/目录里同时创建一个以服务接口命名的文件?放在其他目录里面不行吗,文件名我随意命名不可以吗? - 为什么文件的内容需要是实现该服务接口的具体实现类?
ServiceLoader是如何发现接口的服务类的?
接下来我们看一下ServiceLoader的源码就可以解答了。
上述例子中,通过ServiceLoader.load(Search.class) 来加载Search接口的实现类,我们知道Java加载类都离不开类加载器,查看ServiceLoader.load()方法的源码就会发现,SPI加载类使用的是线程上下文加载器,可通过java.lang.Thread#setContextClassLoader方法进行设置,若未设置则会从父线程中继承,在应用程序全局都未设置的情况下,默认是应用程序类加载器,线程上下文加载器加载所需的SPI代码,实际上是父类加载器请求子类加载器来完成加载类的动作,打破了双亲委派模型的层次结构。

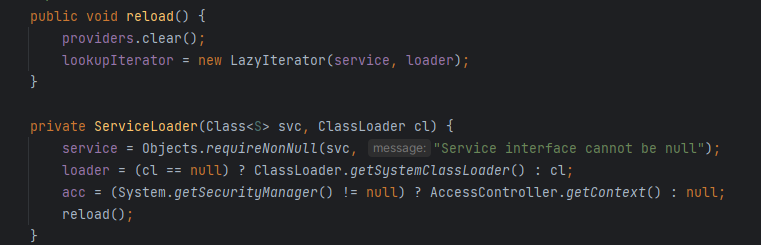
load方法实际上构造了一个ServiceLoader实例对象,该对象保持了一个加载SPI类代码的线程上下文加载器的引用loader、一个所需要加载实现类的接口类型的引用service、一个已经成功服务提供者(接口的具体实现类)的缓存providers。
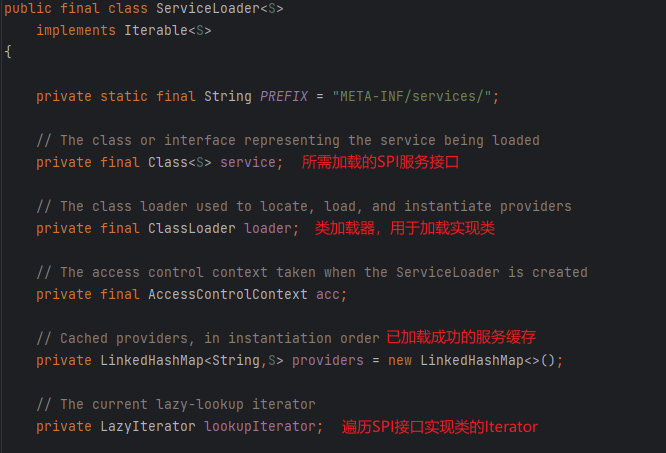
上述例子中我们使用了foreach遍历调用接口方法,本质上是通过调用迭代器Iterable的next()方法来获取的具体实现类,因为ServiceLoader实现了Iterable这一接口,而整个服务发现的核心,就在它的iterator()方法中。
这里面有两个关键的东西,一是providers,在迭代器中会先从服务类缓存中查找服务类,若查不到就用lookupIterator查找。接着往下看LazyIterator的hasNext()和next()源码实现。
acc是一个安全管理器,debug 看值是null,所以看hasNextService()和nextService()方法就可以了。在hasNextService()方法中,会通过PREFIX + service.getName()来拼接一个资源路径URL,拼接这个URL的目的就是为了能供通过该URL获取文件中的内容,看到这里应该就明白了为什么实现SPI服务时,需要创建名为META-INF/services/的文件夹,以及以接口名命名的文件,这是由PREFIX与service.getName()决定的,那么下图中的实现类名称是如何来的呢?
既然我们这里可以通过PREFIX + service.getName()来拼接一个资源路径URL,那是不是可以通过该URL来获取所指向的文件资源的内容?答案是肯定的,正如源码中parse()方法的实现一样, 通过Java提供的InputStream读取URL指向的文件内容。
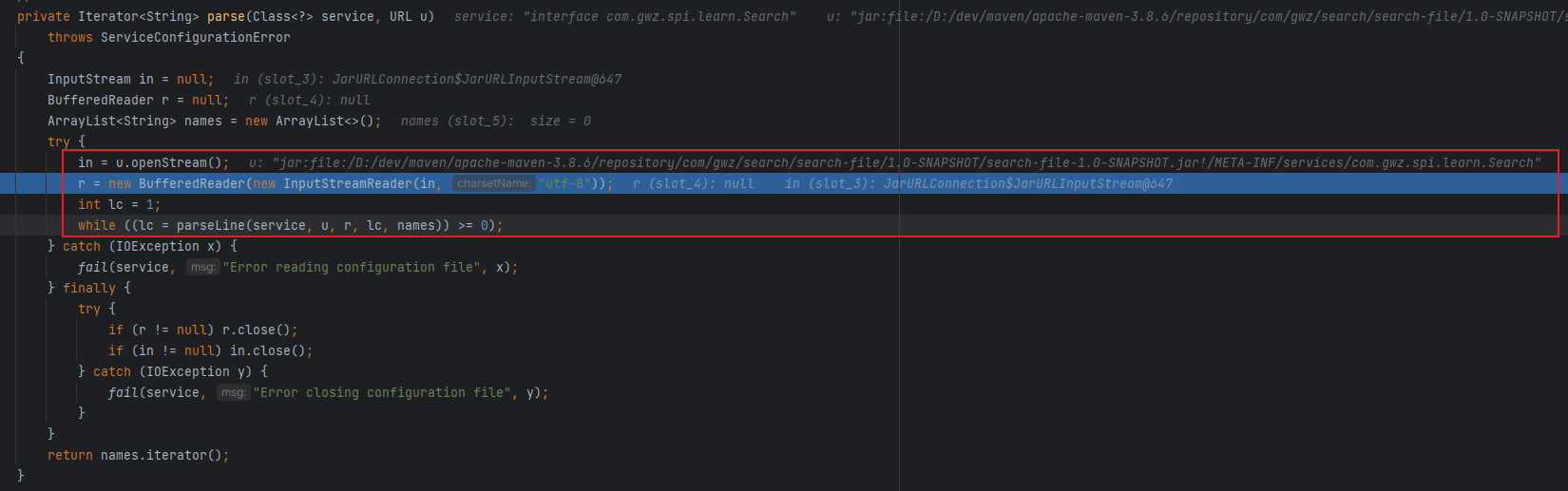
在读取文件内容时ServiceLoader主要做了几件事:
- 获取文本内容(实现类全路径名);
- 校验内容合法性(是否符合Java类命名规范);
- 若providers缓存中不存在该实现类(未加载),则保存该实现类全路径名以供下面流程进行加载该类;
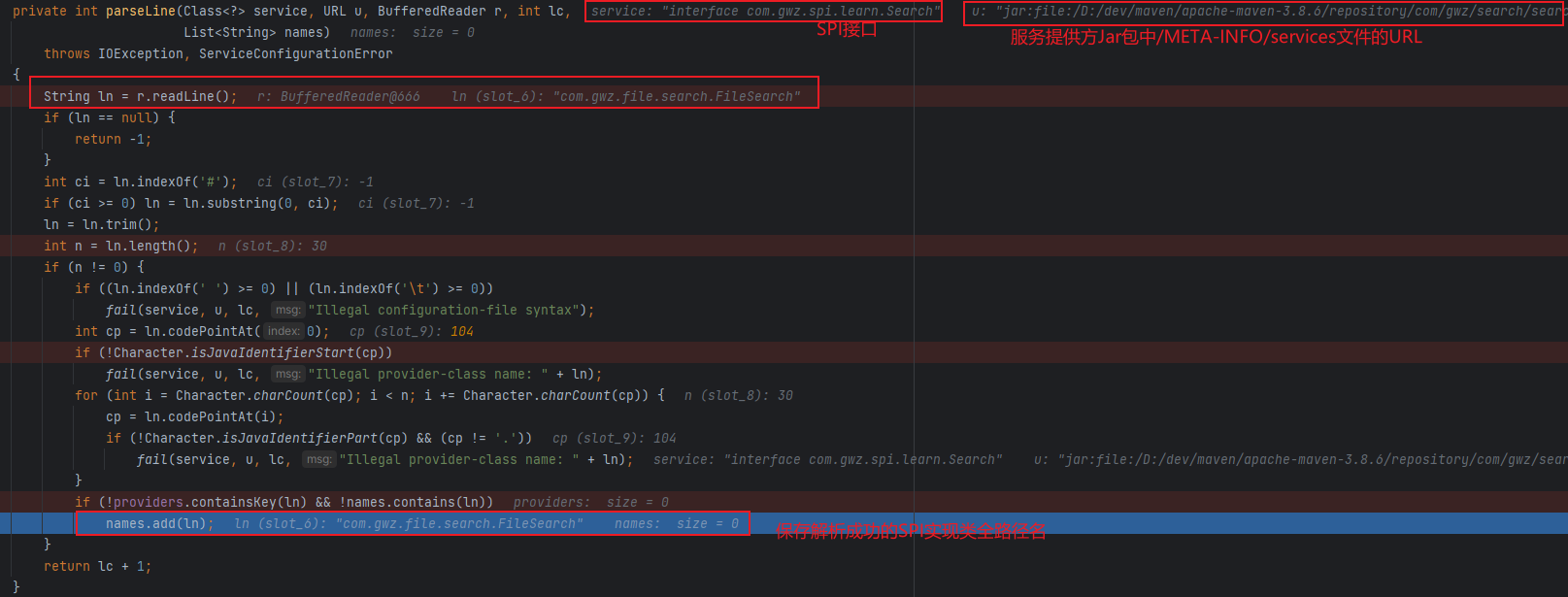
接下来,在nextService()方法中,则会通过上述解析到的实现类全路径名加载这个实现类,然后实例化对象,最终放入缓存中去。
在迭代器的迭代过程中,会基于Java 反射机制去完成所有实现类的实例化,这样就可以调用接口方法来使用SPI服务提供方实现的具体功能。
综上,Java SPI的实现是依靠ServiceLoader,ServiceLoader通过使用线程上下文类加载器来加载SPI接口实现类,实现类的全路径名需配置在META-INF/services/目录下,以接口名命名的文件内容中,ServiceLoader会读取文件中的全路径名,通过反射机制实例化接口实现类。
5 应用
(1)日志框架slf4j
SPI的实际应用,最常见的应该是日志框架slf4j,它就是个日志门面,并不提供具体的实现,需要绑定其他具体实现。例如可使用log4j2作为具体的绑定器,只需要在 pom 中引入slf4j-log4j12,就可以使用具体功能。
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>2.0.3</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>2.0.3</version>
</dependency>引入项目后,点开它的 jar 包看一下具体结构:
jar 包的META-INF.services里面,通过 SPI 注入了Reload4jServiceProvider这个实现类,它实现了SLF4JServiceProvider这一接口,在它的初始化方法initialize()中,会完成初始化等工作,后续可以继续获取到LoggerFactory和Logger等具体日志对象。
(2)DriverManager
DriverManager是JDBC里管理数据库驱动的的工具类。一个数据库可能会存在不同实现的数据库驱动。我们在使用特定的驱动实现时,通过一个简单的配置就而不用修改代码就可以达到效果。 例如,在运用Class.forName("com.mysql.jdbc.Driver")加载mysql驱动后,会执行其中的静态代码把driver注册到DriverManager中。
查看JDBC源码可知,驱动实现接口java.sql.Driver,然后通过registerDriver把当前driver加载到DriverManager中。查看DriverManager的源码,可以看到其内部的静态代码块loadInitialDrivers方法中使用了ServiceLoader:
查看mysql-connector-java的jar包在META-INF/services接口路径文件中的内容,可以看到com.mysql.jdbc.Driver。
(3)sharding-jdbc
sharding-jdbc是一款用于分库分表的中间件,在数据库分布式场景中,为了保证数据库主键的唯一性,会采取相应的主键生成策略,而主键生成策略有很多种实现。sharding-jdbc在主键生成策略使用了SPI进行装配。
源码中的 ShardingRule.class主要封装分库分表的策略规则,包括主键生成,核心在于底层调用的register方法,其中也是使用了ServiceLoader:
这里就是应用的SPI机制,再看下Jar包的META-INF/services/目录:
有两个实现,对应了sharding-jdbc的提供的两种生成策略分别是雪花算法和UUID。
6 总结
Java 中的 SPI 提供了一种比较特别的服务发现和调用机制,通过接口将服务调用与服务提供者分离,将接口提供给第三方实现扩展,体现了依赖倒置的设计思想,是高内聚、低耦合的一种体现。但SPI也有缺点,就是加载一个接口,会把所有实现类都加载进来,可能会加载到不需要的冗余服务。总的来说,SPI是一种非常不错的扩展、集成的思路。
参考资料
https://blog.csdn.net/CHIKA2333/article/details/132082244
《深入理解Java虚拟机:JVM高级特性与最佳实践》--周志明






