您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
实战:工作中对并发问题的处理
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
实战:工作中对并发问题的处理
wy****
2023-08-09
IP归属:北京
656浏览
### 1\. 问题背景 问题发生在快递分拣的流程中,我尽可能将业务背景简化,让大家只关注并发问题本身。 分拣业务针对每个快递包裹都会生成一个任务,我们称它为 task。task 中有两个字段需要关注,一个是分拣中发生的 **异常(exp\_type)**,另一个是分拣任务的 **状态(status)**。另外,需要关注 **分拣状态上报接口**,通过它来记录分拣过程中的异常和状态变更。 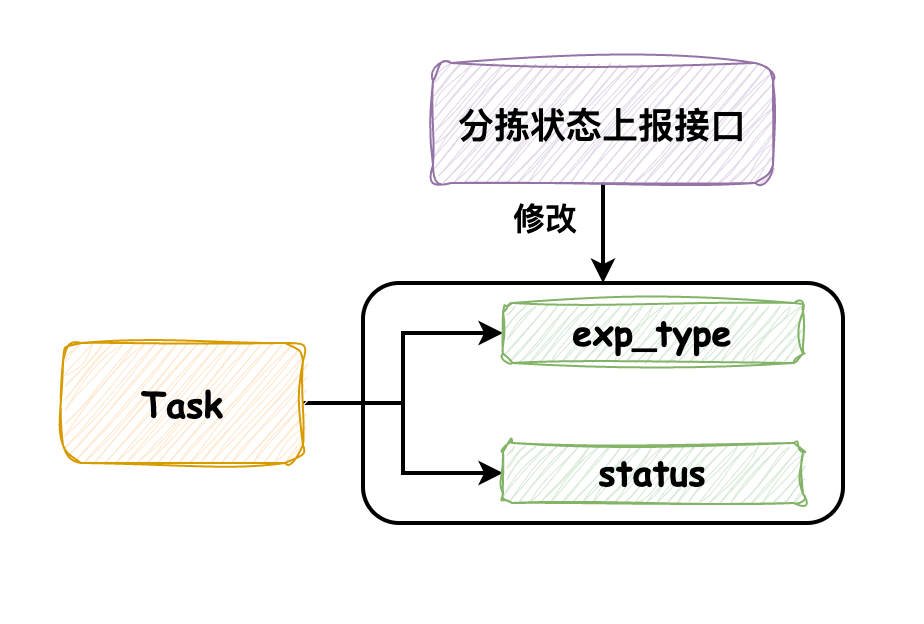 一般情况下,分拣机在分拣异常发生时会及时调用接口上报,在分拣完成时调用接口来标记为完成状态,两次接口调用的时间间隔较长,不会发生并发问题。 但是有一种特殊的分拣机,它不会在异常发生时及时上报,而是在分拣完成时将分拣过程中发生的异常和分拣结果一起上报,那么此时分拣状态上报接口在同一时间内就会有两次调用,这时便发生了预期外的并发问题。 我们先看下分拣状态上报接口的执行流程: 1. 先查询到该分拣任务 task,默认情况下 exp\_type 和 status 均为默认值0 2. 分拣异常修改 task 中的 exp\_type,分拣完成修改 status 字段信息 3. 修改完成将 task 写入 并发问题发生的图示如下: 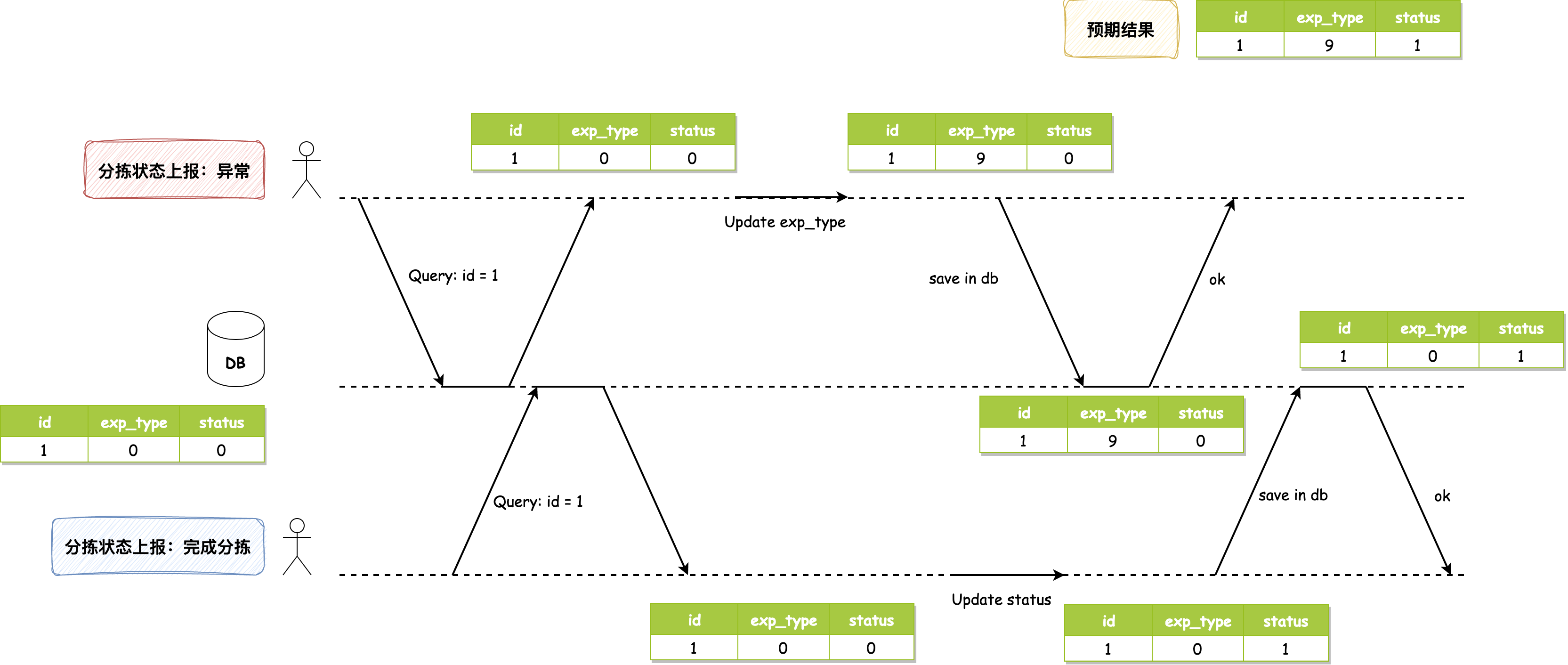 数据库初始值为 `1, 0, 0`,分拣异常和分拣完成几乎同时上报,它们都读取到该值。分拣异常动作将 exp\_type 修改为9,写入数据库,此时数据库值为 `1, 9, 0`;分拣完成动作将 status 修改为1,写入数据库,使得数据库最终值为 `1, 0, 1`,它**将异常字段的值覆盖掉了**。正常情况下,最终值应该为 `1, 9, 1`,分拣完成动作应该读取到分拣异常完成后的值 `1, 9, 0` 后再进行修改才对。 ### 2\. 解决方案 发生这个问题的原因很容易就能发现:两个事务同时执行 **读取-修改-写入** 序列,其中一个写操作在没有合并另一个写操作变更的情况下,直接覆盖了另一个写操作的结果,所以导致了数据的丢失。 这种问题是比较典型的 **丢失更新** 问题,可以通过对数据库读操作加锁或者改变数据库的隔离级别为可串行化使事务串行执行的方式进行避免。下面我会将大家在讨论避免丢失更新问题时提出的方案进行介绍,并尽可能的用代码来表现它们。 #### 2.1 数据库读操作加锁和可串行化隔离级别 我们可以考虑:如果对每条Task数据修改的事务都是在当前事务完成之后才允许后续事务进行修改,使事务串行执行,那么我们就能够避免这种情况。比较直接的实现是通过显式加锁来实现,如下 ```sql select exp_type, status from task where id = 1 for update; ``` 先查询该行数据的事务会获取到该行数据的 **排他锁**,后续针对该数据的所有读写请求都会被阻塞,直到先前事务执行完将锁释放。 这样通过加锁的方式实现了事务的串行执行。但是,在为SQL添加加锁语句时,需要确定是不是为该行数据加锁而不是锁住了整个表,如果是后者,那么可能会造成系统性能严重下降,而且还需要关注有哪些业务场景使用到了该SQL,是否存在长时间执行的只读事务使用,如果存在的话可能会出现因加锁导致延迟和系统性能下降,所以需要谨慎的评估。 此外,可串行化的数据库隔离级别也能保证事务的串行执行,不过它针对的是所有事务。一般情况下为了保证性能,我们不会采用这种方案(默认使用MySQL可重复读隔离级别)。 > MySQL的InnoDB引擎实现可串行化隔离级别采用的是2PL机制:在第一阶段事务执行时获取锁,第二阶段事务执行完成释放锁。 #### 2.2 针对业务只修改必要字段 如果异常状态请求仅修改 exp\_type 字段,分拣完成仅修改 status 字段的话,那么我们可以梳理一下业务逻辑,仅将必要修改的字段写入数据库,这样就不会发生丢失更新的异常,如下代码所示: ```java // 处理异常状态请求,封装修改数据的对象 Task task = new Task(); tast.setId(id); task.setExpType(expType); // 更改数据 taskService.updateById(task); ``` 在执行修改数据前,创建一个新的修改对象,并只为其必要修改字段赋值。但是还需要考虑的是:如果这个业务流程处理已经很复杂了,很可能不清楚该为哪些字段赋值而导致再发生新的异常,所以采用这种方法需要对业务足够熟悉,并且在修改完后进行充分的测试。 #### 2.3 分布式锁 分布式锁的方法与方法一类似,都是通过加锁的方式来保证同时只有一个事务执行,区别是方法一的锁加在了数据库层,而分布式锁是借助Redis来实现。 这种实现方式的好处是锁的粒度小,发生锁争抢仅限于单个包裹,无需像数据库加锁一样去考虑锁的粒度和对相关业务的影响。伪代码如下所示: ```java // 分布式锁KEY String distributedKey = String.format(DISTRIBUTED_KEY_PREFIX, packageNo); try { // 分布式锁阻塞同一包裹号的修改 lock(distributedKey); // 处理业务逻辑 handler(); } finally { // 执行完解锁 redissonDistributedLocker.unlock(distributedKey); } ``` 需要注意,`lock()` 加锁方法要保证加锁失败或发生其他异常情况不影响业务逻辑的执行,并设定好锁持有时间和等待锁的阻塞时间,此外解锁方法务必添加到 **finally** 代码块中保证锁的释放。 #### 2.4 CAS CAS是乐观的解决方案,它一般通过在数据库中增加时间戳列来记录上次数据更改的时间,当新的事务执行时,需要比对读取时该行数据的时间戳和数据库中保存的时间戳是否一致,以此来判断事务执行期间是否有其他事务修改过该行数据,只有在没有发生改变的情况下才允许更新,否则需要重试这个事务。样例SQL如下所示: ```sql update task set exp_type = #{expType}, status = #{status}, ts = #{currentTs} where id = #{id} and ts = #{readTs} ``` 它的原理不难理解,但是实现起来可能会存在困难,因为需要考虑在执行失败后该如何重试,重试的方式和重试的次数需要根据业务去判断。 --- ### 巨人的肩膀 * 《数据密集型应用系统设计》第七章 事务
上一篇:MySQL 执行计划详解
下一篇:分布式事务的华丽进化
wy****
文章数
47
阅读量
38472
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
1. 为什么要分区?分区(partitions) 也被称为 分片(sharding),通常采用对数据进行分区的方式来增加系统的 可伸缩性,以此来面对非常大的数据集或非常高的吞吐量,避免出现热点。分区通常和复制结合使用,使得每个分区的副本存储在多个节点上,保证数据副本的 高可用。如下图所示,如果数据库被分区,每个分区都有一个主库。不同分区的主库可能在不同的节点上,每个节点可能是某些分区的主库,同时是
01
深入理解分布式共识算法 Raft
“不可靠的网络”、“不稳定的时钟”和“节点的故障”都是在分布式系统中常见的问题,在文章开始前,我们先来看一下:如果在分布式系统中网络不可靠会发生什么样的问题。有以下 3 个服务构成的分布式集群,并在 server_1 中发生写请求变更 A = 1,“正常情况下” server_1 将 A 值同步给 server_2 和 server_3,保证集群的数据一致性:但是如果在数据变更时发生网络问题(延迟
01
缓存之美:从根上理解 ConcurrentHashMap
本文将详细介绍 ConcurrentHashMap 构造方法、添加值方法和扩容操作等源码实现。ConcurrentHashMap 是线程安全的哈希表,此哈希表的设计主要目的是在最小化更新操作对哈希表的占用,以保持并发可读性,次要目的是保持空间消耗与 HashMap 相同或更好,并支持利用多线程在空表上高效地插入初始值。在 Java 8 及之后的版本,使用 CAS 操作、 synchronized
01
缓存之美:万文详解 Caffeine 实现原理(上)
由于神灯社区最大字数限制,本文章将分为两篇,第二篇文章为缓存之美:万文详解 Caffeine 实现原理(下)文章将采用“总-分-总”的结构对配置固定大小元素驱逐策略的 Caffeine 缓存进行介绍,首先会讲解它的实现原理,在大家对它有一个概念之后再深入具体源码的细节之中,理解它的设计理念,从中能学习到用于统计元素访问频率的 Count-Min Sketch 数据结构、理解内存屏障和如何避免缓存伪
wy****
文章数
47
阅读量
38472
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
01
深入理解分布式共识算法 Raft
01
缓存之美:从根上理解 ConcurrentHashMap
01
缓存之美:万文详解 Caffeine 实现原理(上)
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 wy****
wy**** 2023-08-09
2023-08-09 656浏览
656浏览






