您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
百亿规模京东实时浏览记录系统的设计与实现
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
百亿规模京东实时浏览记录系统的设计与实现
fl****
2023-07-12
IP归属:北京
3125浏览
## 1. 系统介绍 浏览记录系统主要用来记录京东用户的实时浏览记录,并提供实时查询浏览数据的功能。在线用户访问一次商品详情页,浏览记录系统就会记录用户的一条浏览数据,并针对该浏览数据进行商品维度去重等一系列处理并存储。然后用户可以通过我的京东或其他入口查询用户的实时浏览商品记录,实时性可以达到毫秒级。目前本系统可以为京东每个用户提供最近200条的浏览记录查询展示。 ## 2. 系统设计与实现 ### 2.1 系统整体架构设计 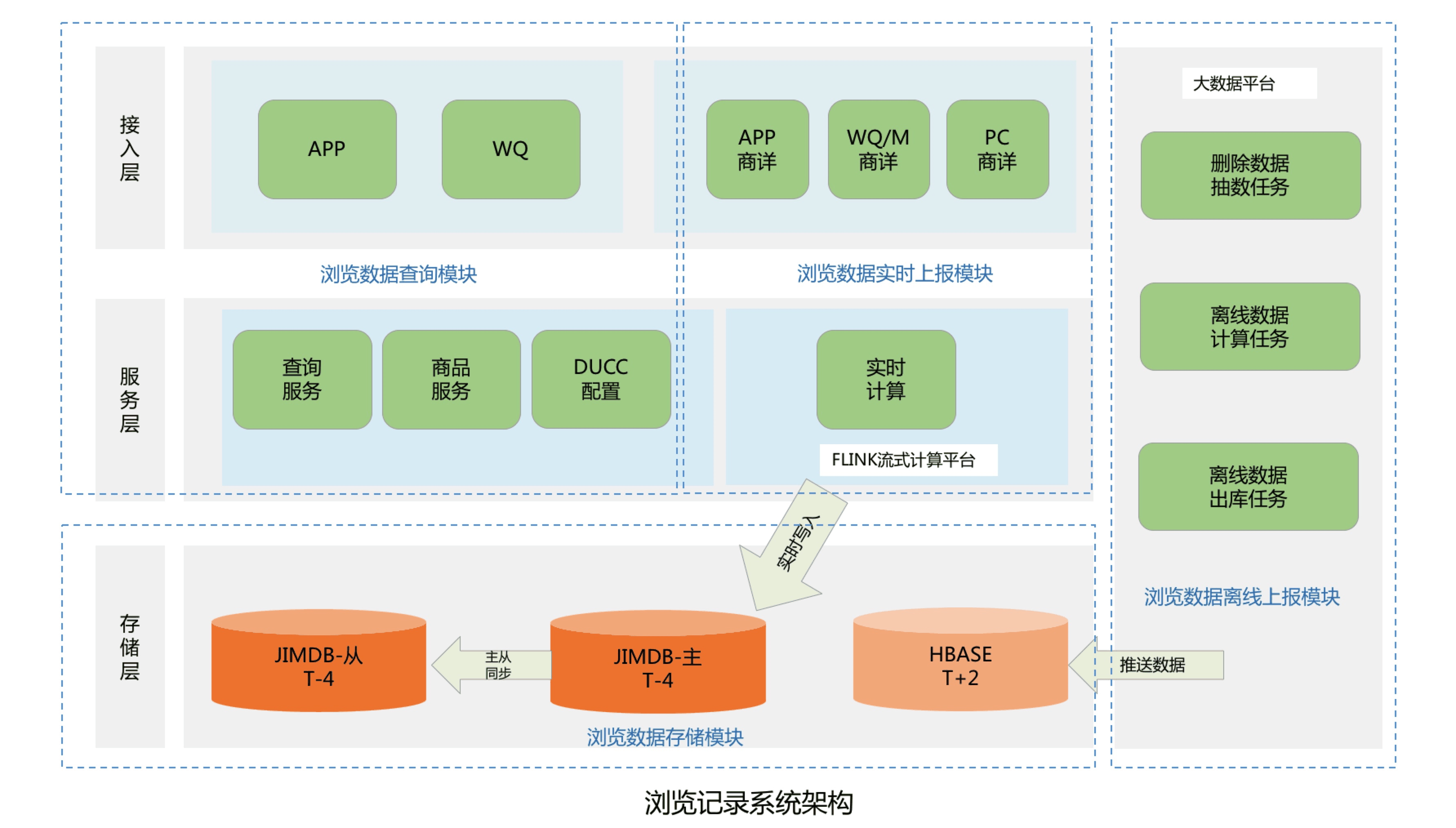 整个系统架构主要分为四个模块,包括浏览数据存储模块、浏览数据查询模块、浏览数据实时上报模块和浏览数据离线上报模块: * 浏览数据存储模块:主要用来存储京东用户的浏览历史记录,目前京东有近5亿的活跃用户,按照每个用户保留最少200条的浏览历史记录,需要设计存储近千亿条的用户浏览历史数据; * 浏览数据查询模块:主要为前台提供微服务接口,包括查询用户的浏览记录总数量,用户实时浏览记录列表和浏览记录的删除操作等功能; * 浏览数据实时上报模块:主要处理京东所有在线用户的实时PV数据,并将该浏览数据存储到实时数据库; * 浏览数据离线上报模块:主要用来处理京东所有用户的PV离线数据,将用户历史PV数据进行清洗,去重和过滤,最后将浏览数据推送到离线数据库中。 #### 2.1.1 数据存储模块设计与实现 考虑到需要存储近千亿条的用户浏览记录,并且还要满足京东在线用户的毫秒级浏览记录实时存储和前台查询功能,我们将浏览历史数据进行了冷热分离。Jimdb纯内存操作,存取速度快,所以我们将用户的(T-4)浏览记录数据存储到Jimdb的内存中,可以满足京东在线活跃用户的实时存储和查询。而(T+4)以外的离线浏览数据则直接推送到Hbase中,存储到磁盘上,用来节省存储成本。如果有不活跃的用户查询到了冷数据,则将冷数据复制到Jimdb中,用来提高下一次的查询性能。 热数据采用了JIMDB的有序集合来存储用户的实时浏览记录,使用用户名做为有序集合的KEY,浏览商品SKU作为有序集合的元素,浏览商品的时间戳作为元素的分数,然后针对该KEY设置过期时间为4天。 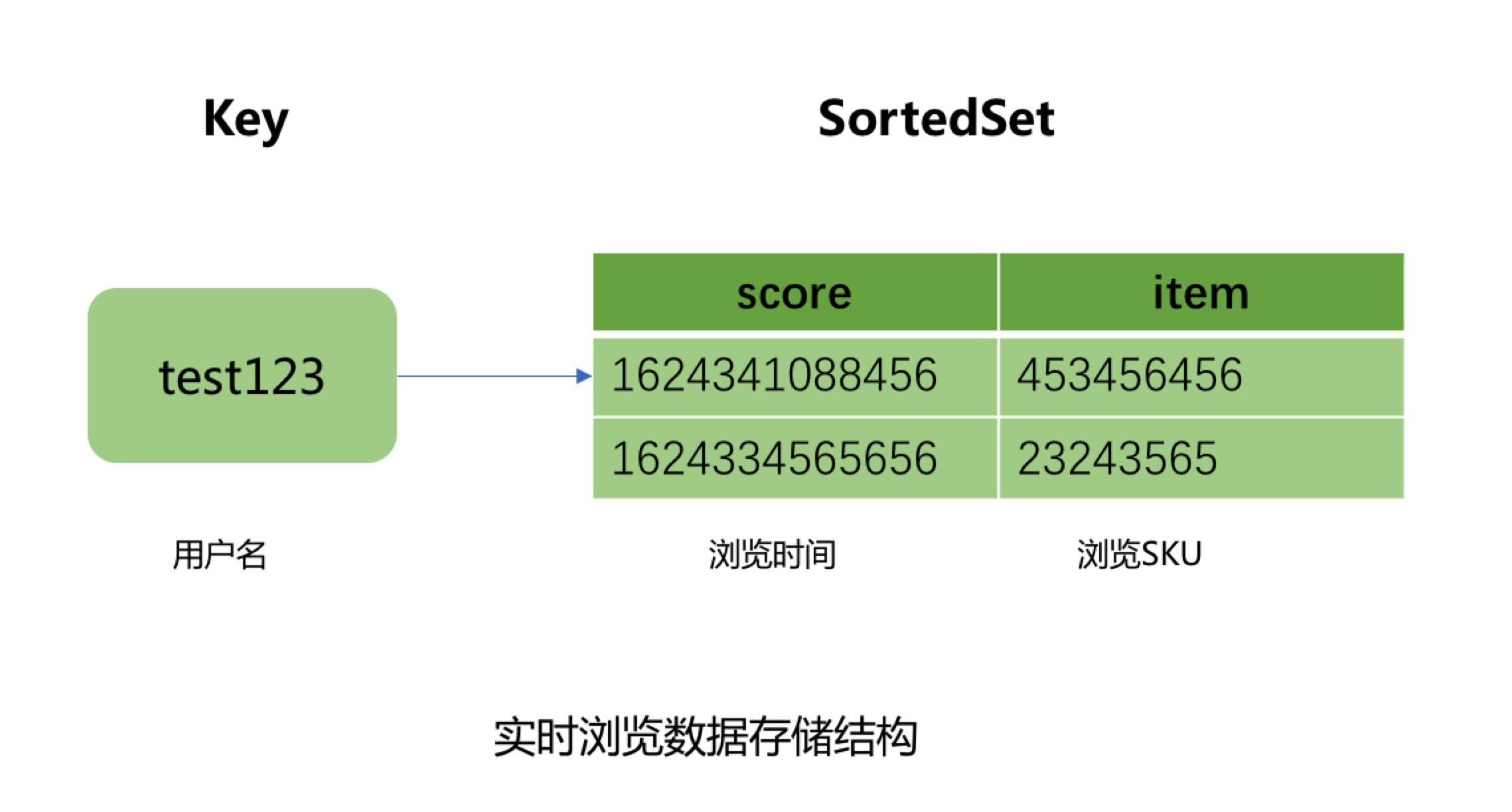 这里的热数据过期时间为什么选择4天? 这是因为我们的大数据平台离线浏览数据都是T+1上报汇总的,等我们开始处理用户的离线浏览数据的时候已经是第二天,在加上我们自己的业务流程处理和数据清洗过滤过程,到最后推送到Hbase中,也需要执行消耗十几个小时。所以热数据的过期时间最少需要设置2天,但是考虑到大数据任务执行失败和重试的过程,需要预留2天的任务重试和数据修复时间,所以热数据过期时间设置为4天。所以当用户4天内都没有浏览新商品时,用户查看的浏览记录则是直接从Hbase中查询展示。 冷数据则采用K-V格式存储用户浏览数据,使用用户名作为KEY,用户浏览商品和浏览时间对应Json字符串做为Value进行存储,存储时需要保证用户的浏览顺序,避免进行二次排序。其中使用用户名做KEY时,由于大部分用户名都有相同的前缀,会出现数据倾斜问题,所以我们针对用户名进行了MD5处理,然后截取MD5后的中间四位作为KEY的前缀,从而解决了Hbase的数据倾斜问题。最后在针对KEY设置过期时间为62天,实现离线数据的过期自动清理功能。 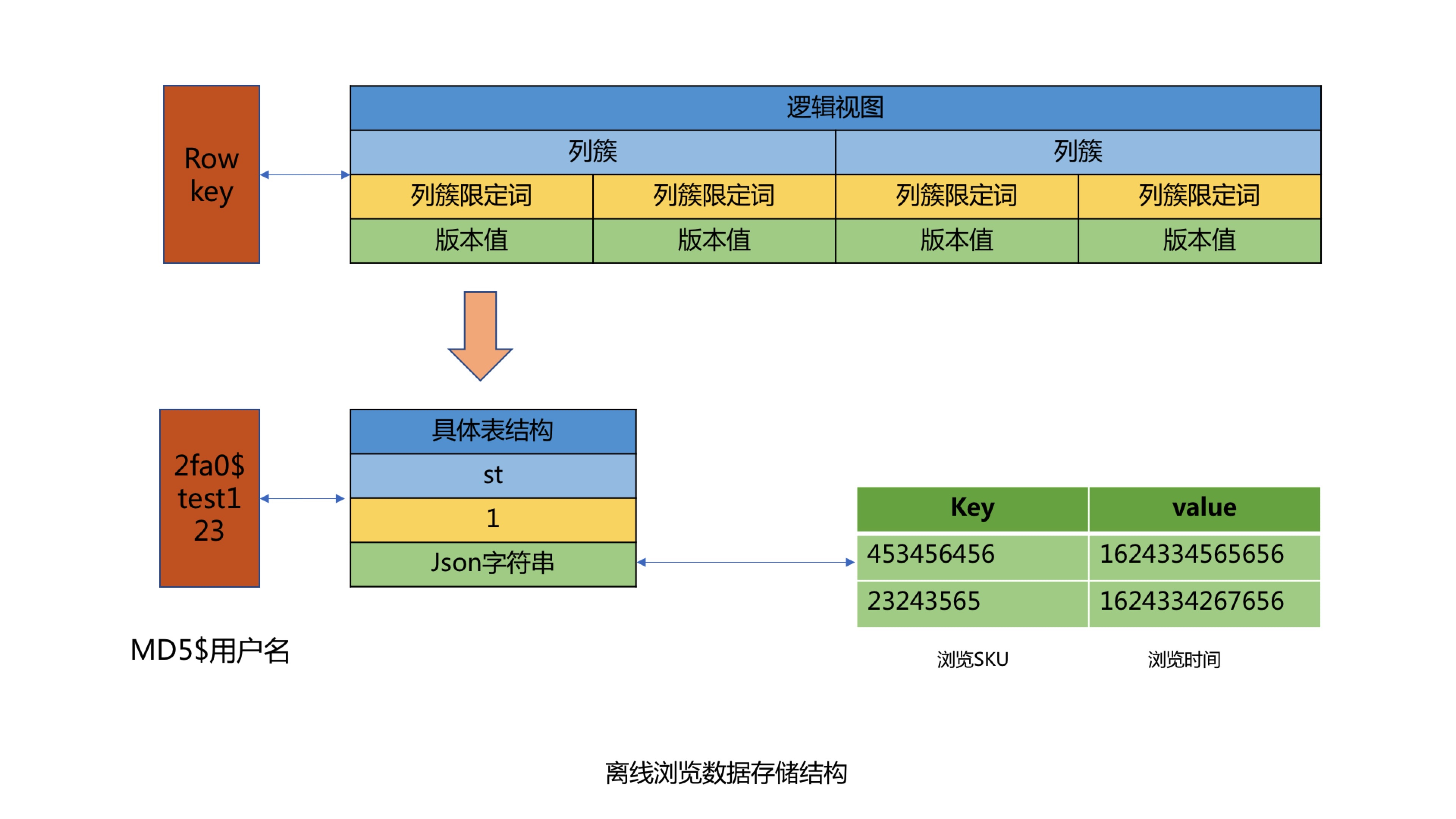 #### 2.1.2 查询服务模块设计与实现 查询服务模块主要包括三个微服务接口,包括查询用户浏览记录总数量,查询用户浏览记录列表和删除用户浏览记录接口。 * 查询用户浏览记录总数量接口设计面临的问题 1. 如何解决限流防刷问题? 基于Guava的RateLimiter限流器和Caffeine本地缓存实现方法全局、调用方和用户名三个维度的限流。具体策略是当调用发第一次调用方法时,会生成对应维度的限流器,并将该限流器保存到Caffeine实现的本地缓存中,然后设置固定的过期时间,当下一次调用该方法时,生成对应的限流key然后从本地缓存中获取对应的限流器,该限流器中保留着该调用方的调用次数信息,从而实现限流功能。 2. 如何查询用户浏览记录总数量? 首先查询用户浏览记录总数缓存,如果缓存命中,直接返回结果,如果缓存未命中则需要从Jimdb中查询用户的实时浏览记录列表,然后在批量补充商品信息,由于用户的浏览SKU列表可能较多,此处可以进行分批查询商品信息,分批数量可以动态调整,防止因为一次查询商品数量过多而影响查询性能。由于前台展示的浏览商品列表需要针对同一SPU商品进行去重,所以需要补充的商品信息字段包括商品名称、商品图片和商品SPUID等字段。针对SPUID字段去重后,在判断是否需要查询Hbase离线浏览数据,此处可以通过离线查询开关、用户清空标记和SPUID去重后的浏览记录数量来判断是否需要查询Hbase离线浏览记录。如果去重后的时候浏览记录数量已经满足系统设置的用户最大浏览记录数量,则不再查询离线记录。如果不满足则继续查询离线的浏览记录列表,并与用户的实时浏览记录列表进行合并,并过滤掉重复的浏览SKU商品。获取到用户完整的浏览记录列表后,在过滤掉用户已经删除的浏览记录,然后count列表的长度,并与系统设置的用户最大浏览记录数量做比较取最小值,就是该用户的浏览记录总数量,获取到用户浏览记录总数量后可以根据缓存开关来判断是否需要异步写入用户总数量缓存。 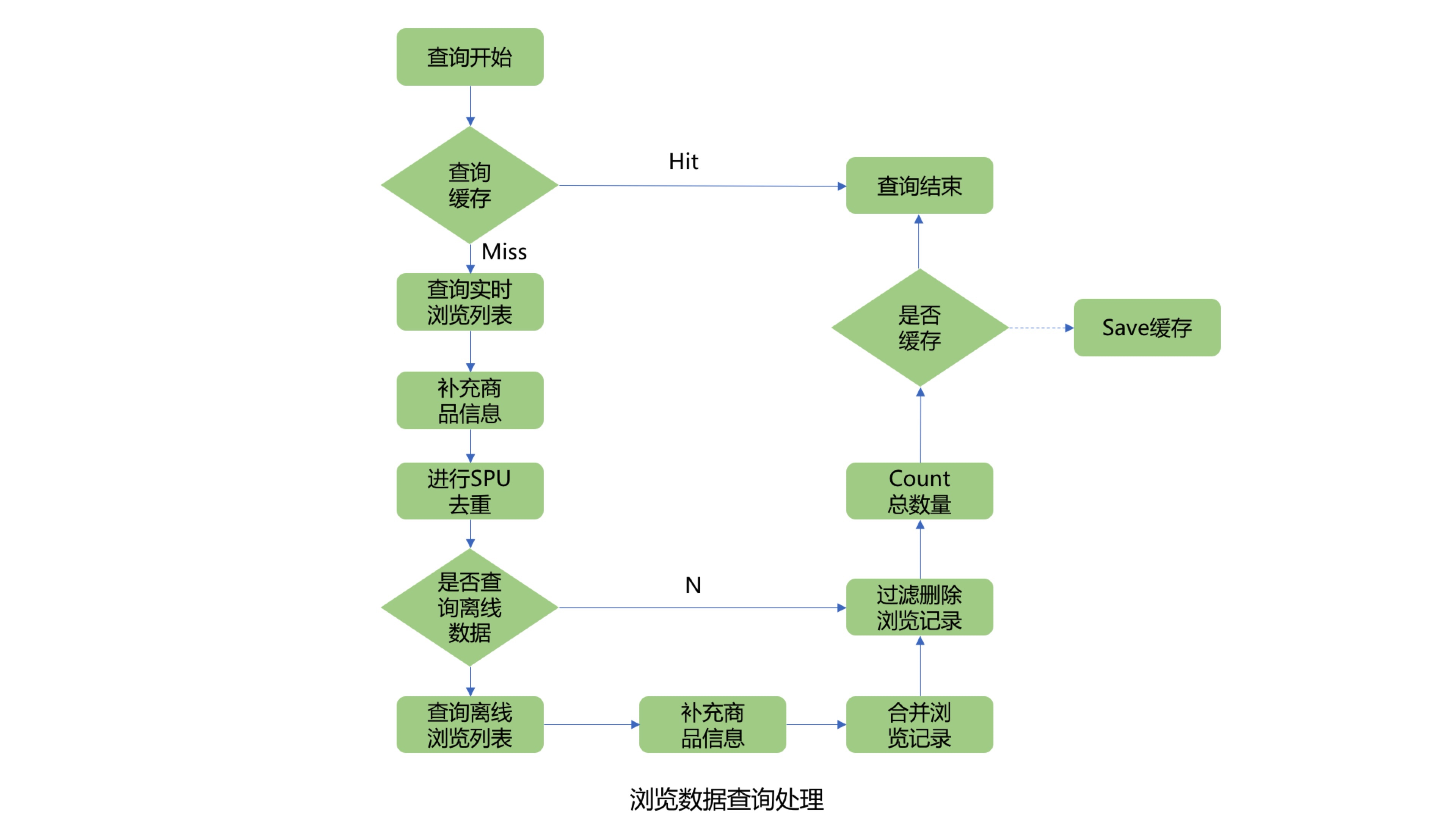 3. 查询用户浏览记录列表 查询用户浏览记录列表流程与查询用户浏览记录总数量流程基本一致。 #### 2.1.2 浏览数据实时上报模块设计与实现 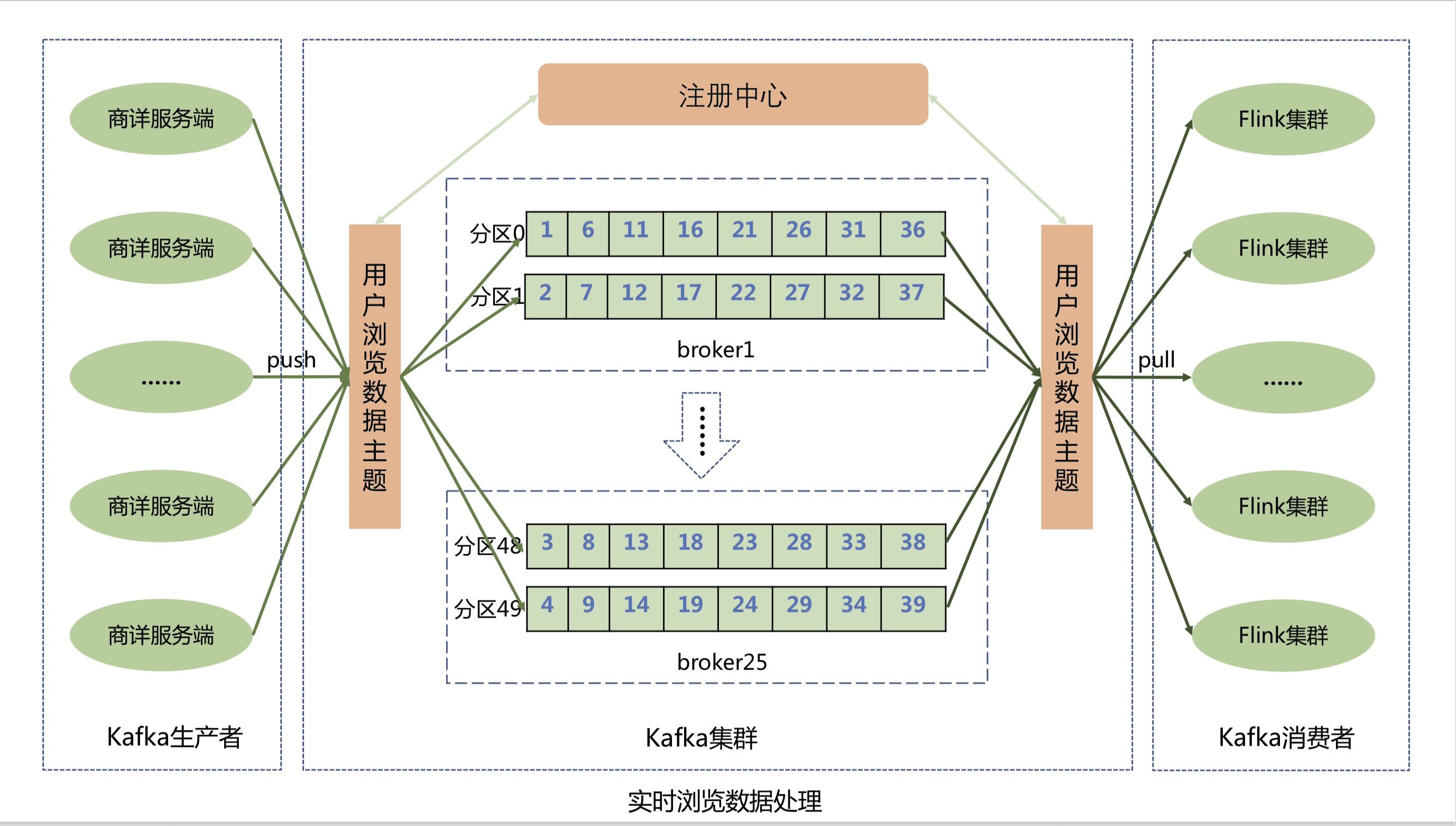 商详服务端将用户的实时浏览数据通过Kafka客户端上报到Kafka集群的消息队列中,为了提高数据上报性能,用户浏览数据主题分成了50个分区,Kafka可以将用户的浏览消息均匀的分散到50个分区队列中,从而大大提升了系统的吞吐能力。 浏览记录系统则通过Flink集群来消费Kafka队列中的用户浏览数据,然后将浏览数据实时存储到Jimdb内存中。Flink集群不仅实现了横向动态扩展,进一步提高Flink集群的吞吐能力,防止出现消息积压,还保证了用户的浏览消息恰好消费一次,在异常发生时不会丢失用户数据并能自动恢复。Flink集群存储实现使用Lua脚本合并执行Jimdb的多个命令,包括插入sku、判断sku记录数量,删除sku和设置过期时间等,将多次网络IO操作优化为1次。 为什么选择Flink流式处理引擎和Kafka,而不是商详服务端直接将浏览数据写入到Jimdb内存中呢? 首先,京东商城做为一个7x24小时服务的电子商务网站,并且有着5亿+的活跃用户,每一秒中都会有用户在浏览商品详情页,就像是流水一样,源源不断,非常符合分布式流式数据处理的场景。 而相对于其他流式处理框架,Flink基于分布式快照的方案在功能和性能方面都具有很多优点,包括: * 低延迟:由于操作符状态的存储可以异步,所以进行快照的过程基本上不会阻塞消息的处理,因此不会对消息延迟产生负面影响。 * 高吞吐量:当操作符状态较少时,对吞吐量基本没有影响。当操作符状态较多时,相对于其他的容错机制,分布式快照的时间间隔是用户自定义的,所以用户可以权衡错误恢复时间和吞吐量要求来调整分布式快照的时间间隔。 * 与业务逻辑的隔离:Flink的分布式快照机制与用户的业务逻辑是完全隔离的,用户的业务逻辑不会依赖或是对分布式快照产生任何影响。 * 错误恢复代价:分布式快照的时间间隔越短,错误恢复的时间越少,与吞吐量负相关。 第二,京东每天都会有很多的秒杀活动,比如茅台抢购,预约用户可达上百万,在同一秒钟就会有上百万的用户刷新商详页面,这样就会产生流量洪峰,如果全部实时写入,会对我们的实时存储造成很大的压力,并且影响前台查询接口的性能。所以我们就利用Kafka来进行削峰处理,而且也对系统进行了解耦处理,使得商详系统可以不强制依赖浏览记录系统。 这里为什么选择Kafka? 这里就需要先了解Kakfa的特性。 * 高吞吐、低延迟:kakfa 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒。 * 高伸缩性: 每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中。 * 持久性、可靠性: Kafka能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失,Kafka底层的数据存储是基于Zookeeper存储的,Zookeeper我们知道它的数据能够持久存储。 * 容错性: 允许集群中的节点失败,某个节点宕机,Kafka集群能够正常工作。 * 高并发: 支持数千个客户端同时读写。 Kafka为什么这么快? 1. Kafka通过零拷贝原理来快速移动数据,避免了内核之间的切换。 2. Kafka可以将数据记录分批发送,从生产者到文件系统到消费者,可以端到端的查看这些批次的数据。 3. 批处理的同时更有效的进行了数据压缩并减少I/O延迟。 4. Kafka采取顺序写入磁盘的方式,避免了随机磁盘寻址的浪费。 目前本系统已经经历多次大促考验,且系统没有进行降级,用户的实时浏览消息没有积压,基本实现了毫秒级的处理能力,方法性能TP999达到了11ms。 #### 2.1.3 浏览数据离线上报模块设计与实现 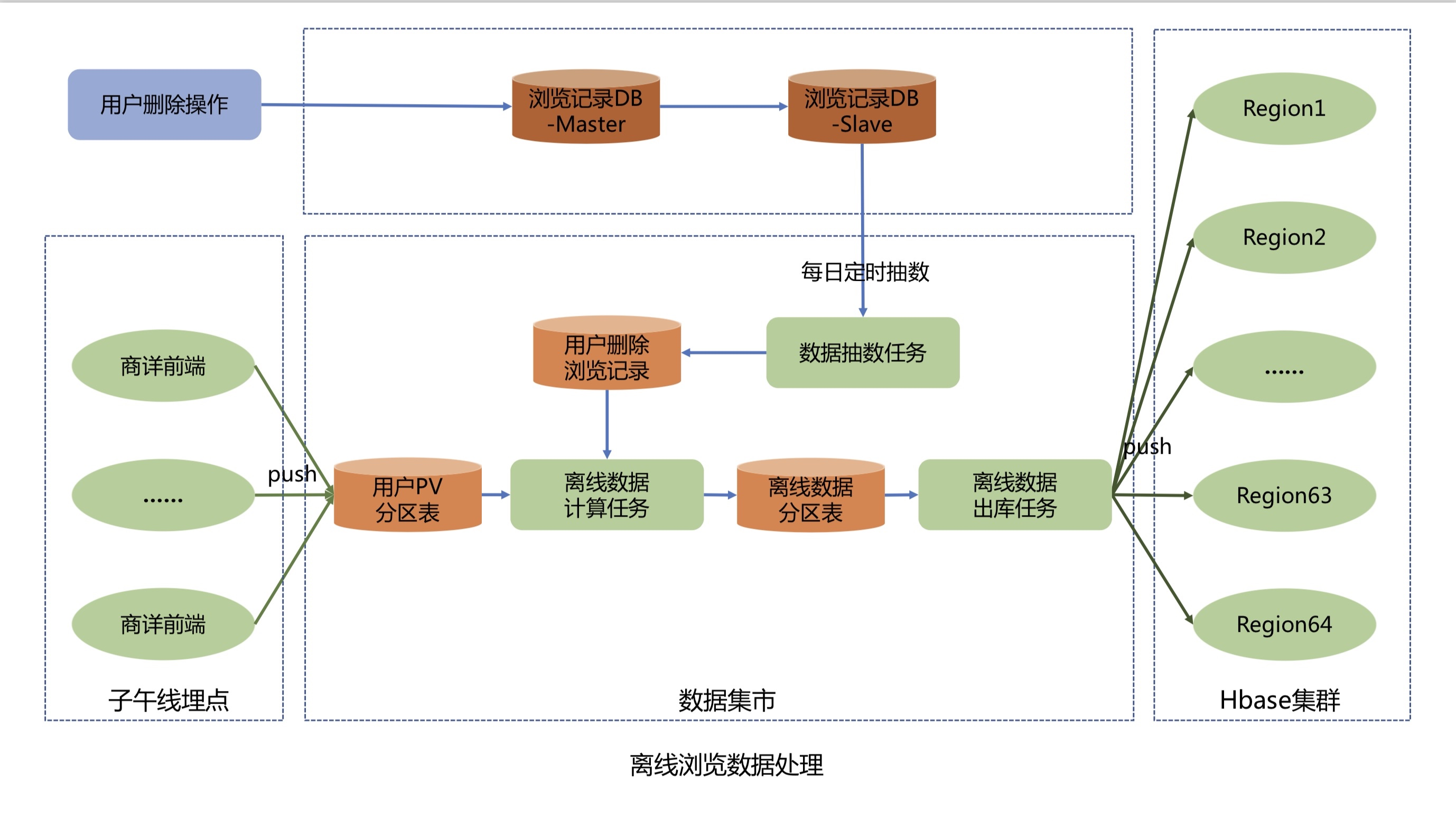 离线数据上报处理流程如下: 1. 商详前端通过子午线的API将用户的PV数据进行上报,子午线将用户的PV数据写入到数据集市的用户PV分区表中。 2. 数据抽数任务每天凌晨2点33分从浏览记录系统Mysql库的用户已删除浏览记录表抽数到数据集市,并将删除数据写入到用户删除浏览记录表。 3. 离线数据计算任务每天上午11点开始执行,先从用户PV分区表中提取近60天、每人200条的去重数据,然后根据用户删除浏览记录表过滤删除数据,并计算出当天新增或者删除过的用户名,最后存储到离线数据分区表中。 4. 离线数据出库任务每天凌晨2点从离线数据分区表中将T+2的增量离线浏览数据经过数据清洗和格式转换,将T+2活跃用户的K-V格式离线浏览数据推送到Hbase集群。
上一篇:基于ClickHouse解决活动海量数据问题
下一篇:一次性说透静态代理&动态代理
fl****
文章数
11
阅读量
21788
作者其他文章
01
千万级数据深分页查询SQL性能优化实践
一、系统介绍和问题描述 如何在Mysql中实现上亿数据的遍历查询?先来介绍一下系统主角:关注系统,主要是维护京东用户和业务对象之前的关注关系;并对外提供各种关系查询,比如查询用户的关注商品或店铺列表,查询用户是否关注了某个商品或店铺等。但是最近接到了一个新需求,要求提供查询关注对象的粉丝列表接口功能。该功能的难点就是关注对象的粉丝数量过多,不少店铺的粉丝数量都是千万级别,并且有些大V
01
百亿规模京东实时浏览记录系统的设计与实现
1. 系统介绍浏览记录系统主要用来记录京东用户的实时浏览记录,并提供实时查询浏览数据的功能。在线用户访问一次商品详情页,浏览记录系统就会记录用户的一条浏览数据,并针对该浏览数据进行商品维度去重等一系列处理并存储。然后用户可以通过我的京东或其他入口查询用户的实时浏览商品记录,实时性可以达到毫秒级。目前本系统可以为京东每个用户提供最近200条的浏览记录查询展示。2. 系统设计与实现2.1 系统整体架构
01
京东统一头尾管理系统探索实践
系统背景 问:修改一个网站的文案需要多久?对于一个小型个人网站来说,估计很简单,几分钟就能修改完成并发布。但如果说要修改的是上百个网站的文案呢?那估计就得需要产品提需求,研发排期开发,测试进行回归验证。由于涉及的应用众多,而每个应用都有自己的研发需求,可能无法快速排期进行文案修改。所以看似一个非常简单的需求,涉及到的应用和部门比较多的时候,也就成了产品经理的恶梦。尤其是像京东商城这样
01
CGLIB动态代理对象GC问题排查
一、问题是怎么发现的最近有个新系统开发完成后要上线,由于系统调用量很大,所以先对核心接口进行了一次压力测试,由于核心接口中基本上只有纯内存运算,所以预估核心接口的压测QPS能够达到上千。压测容器配置:4C8G先从10个并发开始进行发压,结果cpu一下就飙升到了100%,但是核心接口的qps才200左右。于是观察jvm的垃圾回收发现younggc很频繁,但是fullGC数量为零。二、排查问题的详细过
fl****
文章数
11
阅读量
21788
作者其他文章
01
千万级数据深分页查询SQL性能优化实践
01
京东统一头尾管理系统探索实践
01
CGLIB动态代理对象GC问题排查
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 fl****
fl**** 2023-07-12
2023-07-12 3125浏览
3125浏览






