



一、引言
Excel表格在后台管理系统中使用非常广泛,多用来进行批量配置、数据导出工作。在日常开发中,我们也免不了进行Excel数据处理。
那么,如何恰当地处理数据量庞大的Excel文件,避免内存溢出问题?本文将对比分析业界主流的Excel解析技术,并给出解决方案。
如果这是您第一次接触Excel解析,建议您从第二章了解本文基础概念;如果您已经对POI有所了解,请跳转第三章阅读本文重点内容。
二、基础篇-POI
说到Excel读写,就离不开这个圈子的的老大哥——POI。

Apache POI是一款Apache软件基金会用Java编写的免费开源的跨平台的 Java API,全称Poor Obfuscation Implementation,“简洁版的模糊实现”。它支持我们用Java语言和包括Word、Excel、PowerPoint、Visio在内的所有Microsoft Office文档交互,进行数据读写和修改操作。
(1)“糟糕”的电子表格
在POI中,每种文档都有一个与之对应的文档格式,如97-2003版本的Excel文件(.xls),文档格式为HSSF——Horrible SpreadSheet Format,意为“糟糕的电子表格格式”。虽然Apache幽默而谦虚地将自己的API冠以“糟糕”之名,不过这确实是一款全面而强大的API。
以下是部分“糟糕”的POI文档格式,包括Excel、Word等:
| Office文档 | 对应POI格式 |
|---|---|
| Excel (.xls) | HSSF (Horrible SpreadSheet Format) |
| Word (.doc) | HWPF (Horrible Word Processor Format) |
| Visio (.vsd) | HDGF (Horrible DiaGram Format) |
| PowerPoint(.ppt) | HSLF(Horrible Slide Layout Format) |
(2)OOXML简介
微软在Office 2007版本推出了基于XML的技术规范:Office Open XML,简称OOXML。不同于老版本的二进制存储,在新规范下,所有Office文档都使用了XML格式书写,并使用ZIP格式进行压缩存储,大大提升了规范性,也提高了压缩率,缩小了文件体积,同时支持向后兼容。简单来说,OOXML定义了如何用一系列的XML文件来表示Office文档。
Xlsx文件的本质是XML
让我们看看一个采用OOML标准的Xlsx文件的构成。我们右键点击一个Xlsx文件,可以发现它可以被ZIP解压工具解压(或直接修改扩展名为.zip后解压),这说明:Xlsx文件是用ZIP格式压缩的。解压后,可以看到如下目录格式:

打开其中的“/xl”目录,这是这个Excel的主要结构信息:
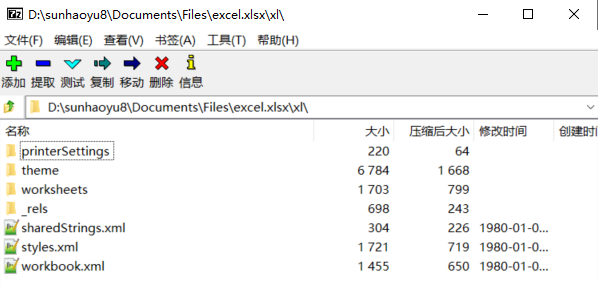
其中workbook.xml存储了整个Excel工作簿的结构,包含了几张sheet表单,而每张表单结构存储在/wooksheets文件夹中。styles.xml存放单元格的格式信息,/theme文件夹存放一些预定义的字体、颜色等数据。为了减少压缩体积,表单中所有的字符数据被统一存放在sharedStrings.xml中。经过分析不难发现,Xlsx文件的主体数据都以XML格式书写。
XSSF格式
为了支持新标准的Office文档,POI也推出了一套兼容OOXML标准的API,称作poi-ooxml。如Excel 2007文件(.xlsx)对应的POI文档格式为XSSF(XML SpreadSheet Format)。
以下是部分OOXML文档格式:
| Office文档 | 对应POI格式 |
|---|---|
| Excel (.xlsx) | XSSF (XML SpreadSheet Format) |
| Word (.docx) | XWPF (XML Word Processor Format) |
| Visio (.vsdx) | XDGF (XML DiaGram Format) |
| PowerPoint (.pptx) | XSLF (XML Slide Layout Format) |
(3)UserModel
在POI中为我们提供了两种解析Excel的模型,UserModel(用户模型)和EventModel(事件模型)。两种解析模式都可以处理Excel文件,但解析方式、处理效率、内存占用量都不尽相同。最简单和实用的当属UserModel。
UserModel & DOM解析
用户模型定义了如下接口:
1. Workbook-工作簿,对应一个Excel文档。根据版本不同,有HSSFWorkbook、XSSFWorkbook等类。
2. Sheet-表单,一个Excel中的若干个表单,同样有HSSFSheet、XSSFSheet等类。
3. Row-行,一个表单由若干行组成,同样有HSSFRow、XSSFRow等类。
4. Cell-单元格,一个行由若干单元格组成,同样有HSSFCell、XSSFCell等类。
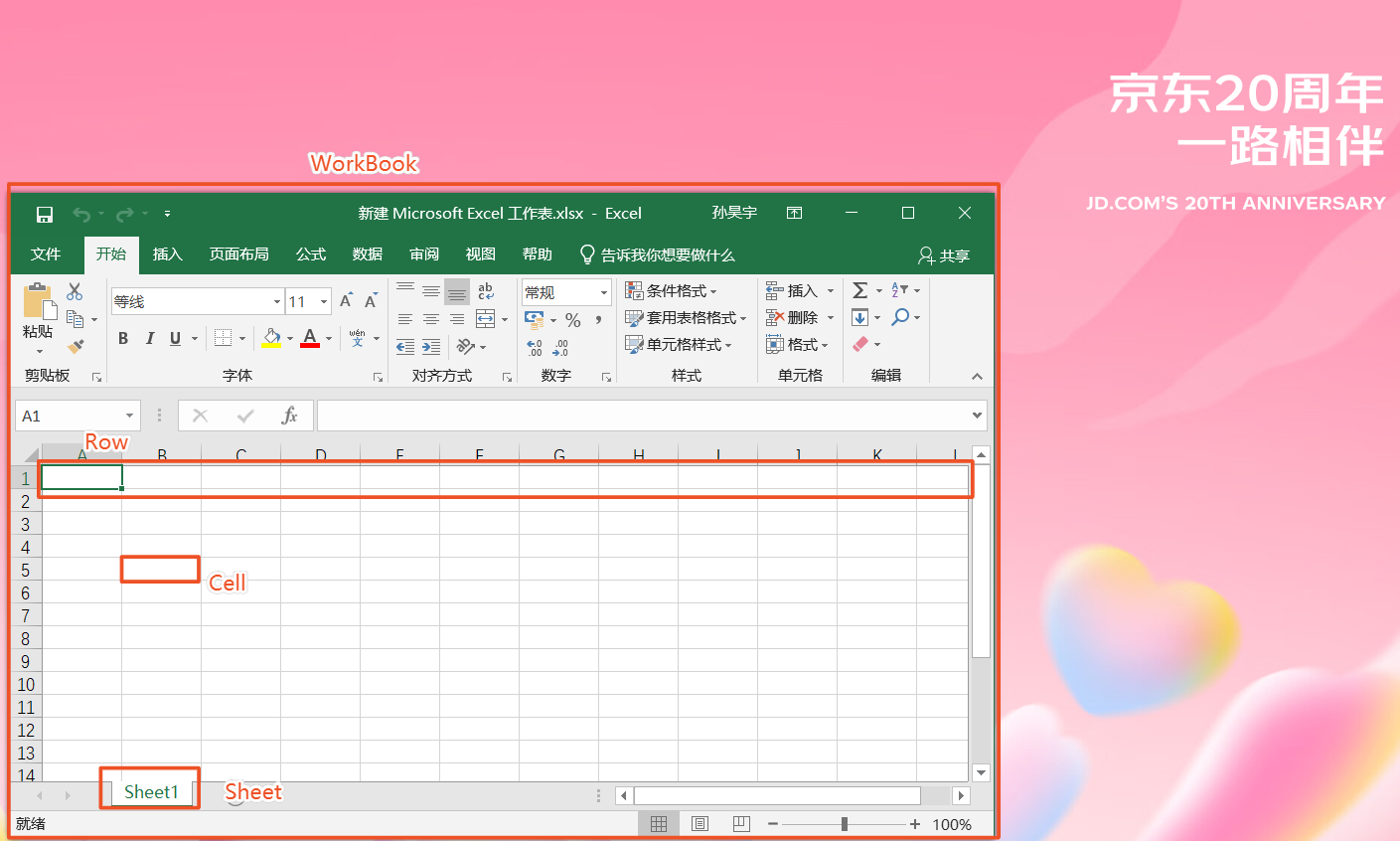
可以看到,用户模型十分贴合Excel用户的习惯,易于理解,就像我们打开一个Excel表格一样。同时用户模型提供了丰富的API,可以支持我们完成和Excel中一样的操作,如创建表单、创建行、获取表的行数、获取行的列数、读写单元格的值等。
为什么UserModel支持我们进行如此丰富的操作?因为在UserModel中,Excel中的所有XML节点都被解析成了一棵DOM树,整棵DOM树都被加载进内存,因此可以进行方便地对每个XML节点进行随机访问。

UserModel数据转换
了解了用户模型,我们就可以直接使用其API进行各种Excel操作。当然,更方便的办法是使用用户模型将一个Excel文件转化成我们想要的Java数据结构,更好地进行数据处理。
我们很容易想到关系型数据库——因为二者的实质是一样的。类比数据库的数据表,我们的思路就有了:
1. 将一个Sheet看作表头和数据两部分,这二者分别包含表的结构和表的数据。
2. 对表头(第一行),校验表头信息是否和实体类的定义的属性匹配。
3. 对数据(剩余行),从上向下遍历每一个Row,将每一行转化为一个对象,每一列作为该对象的一个属性,从而得到一个对象列表,该列表包含Excel中的所有数据。
接下来我们就可以按照我们的需求处理我们的数据了,如果想把操作后的数据写回Excel,也是一样的逻辑。
使用UserModel
让我们看看如何使用UserModel读取Excel文件。此处使用POI 4.0.0版本,首先引入poi和poi-ooxml依赖:
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.0.0</version>
</dependency>我们要读取一个简单的Sku信息表,内容如下:
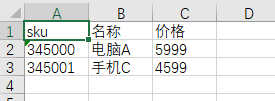
如何将UserModel的信息转化为数据列表?
我们可以通过实现反射+注解的方式定义表头到数据的映射关系,帮助我们实现UserModel到数据对象的转换。实现基本思路是:
① 自定义注解,在注解中定义列号,用来标注实体类的每个属性对应在Excel表头的第几列。
② 在实体类定义中,根据表结构,为每个实体类的属性加上注解。
③ 通过反射,获取实体类的每个属性对应在Excel的列号,从而到相应的列中取得该属性的值。
以下是简单的实现,首先准备自定义注解ExcelCol,其中包含列号和表头:
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface ExcelCol {
/**
* 当前列数
*/
int index() default 0;
/**
* 当前列的表头名称
*/
String header() default "";
}接下来,根据Sku字段定义Sku对象,并添加注解,列号分别为0,1,2,并指定表头名称:
import lombok.Data;
import org.shy.xlsx.annotation.ExcelCol;
@Data
public class Sku {
@ExcelCol(index = 0, header = "sku")
private Long id;
@ExcelCol(index = 1, header = "名称")
private String name;
@ExcelCol(index = 2, header = "价格")
private Double price;
}然后,用反射获取表头的每一个Field,并以列号为索引,存入Map中。从Excel的第二行开始(第一行是表头),遍历后面的每一行,对每一行的每个属性,根据列号拿到对应Cell的值,并为数据对象赋值。根据单元格中值类型的不同,如文本/数字等,进行不同的处理。以下为了简化逻辑,只对表头出现的类型进行了处理,其他情况的处理逻辑类似。全部代码如下:
import com.alibaba.fastjson.JSON;
import org.apache.commons.lang3.StringUtils;
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import org.shy.domain.pojo.Sku;
import org.shy.xlsx.annotation.ExcelCol;
import java.io.FileInputStream;
import java.lang.reflect.Field;
import java.text.DecimalFormat;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class MyUserModel {
public static void main(String[] args) throws Exception {
List<Sku> skus = parseSkus("D:\\sunhaoyu8\\Documents\\Files\\skus.xlsx");
System.out.println(JSON.toJSONString(skus));
}
public static List<Sku> parseSkus(String filePath) throws Exception {
FileInputStream in = new FileInputStream(filePath);
Workbook wk = new XSSFWorkbook(in);
Sheet sheet = wk.getSheetAt(0);
// 转换成的数据列表
List<Sku> skus = new ArrayList<>();
// 获取Sku的注解信息
Map<Integer, Field> fieldMap = new HashMap<>(16);
for (Field field : Sku.class.getDeclaredFields()) {
ExcelCol col = field.getAnnotation(ExcelCol.class);
if (col == null) {
continue;
}
field.setAccessible(true);
fieldMap.put(col.index(), field);
}
for (int rowNum = 1; rowNum <= sheet.getLastRowNum(); rowNum++) {
Row r = sheet.getRow(rowNum);
Sku sku = new Sku();
for (int cellNum = 0; cellNum < fieldMap.size(); cellNum++) {
Cell c = r.getCell(cellNum);
if (c != null) {
setFieldValue(fieldMap.get(cellNum), getCellValue(c), sku);
}
}
skus.add(sku);
}
return skus;
}
public static void setFieldValue(Field field, String value, Sku sku) throws Exception {
if (field == null) {
return;
}
//得到此属性的类型
String type = field.getType().toString();
if (StringUtils.isBlank(value)) {
field.set(sku, null);
} else if (type.endsWith("String")) {
field.set(sku, value);
} else if (type.endsWith("long") || type.endsWith("Long")) {
field.set(sku, Long.parseLong(value));
} else if (type.endsWith("double") || type.endsWith("Double")) {
field.set(sku, Double.parseDouble(value));
} else {
field.set(sku, value);
}
}
public static String getCellValue(Cell cell) {
DecimalFormat df = new DecimalFormat("#.##");
if (cell == null) {
return "";
}
switch (cell.getCellType()) {
case NUMERIC:
return df.format(cell.getNumericCellValue());
case STRING:
return cell.getStringCellValue().trim();
case BLANK:
return null;
}
return "";
}最后,将转换完成的数据列表打印出来。运行结果如下:
[{"id":345000,"name":"电脑A","price":5999.0},{"id":345001,"name":"手机C","price":4599.0}]Tips:如果您的程序出现“NoClassDefFoundError”,请引入ooxml-schemas依赖:
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>ooxml-schemas</artifactId>
<version>1.4</version>
</dependency>版本选择见下表,如POI 4.0.0对应ooxml-schemas 1.4版本:
UserModel的局限
以上处理逻辑对于大部分的Excel文件都很适用,但最大的缺点是内存开销大,因为所有的数据都被加载入内存。实测,以上3列的Excel文件在7万行左右就会出现OOM,而XLS文件最大行数为65535行,XLSX更是达到了1048576行,如果将几万甚至百万级别的数据全部读入内存,内存溢出风险极高。
那么,该如何解决传统UserModel无法处理大批量Excel的问题呢?开发者们给出了许多精彩的解决方案,请看下一章。
三、进阶篇-内存优化的探索
接下来介绍本文重点内容,同时解决本文所提出的问题:如何进行Excel解析的内存优化,从而处理百万行Excel文件?
(1)EventModel
前面我们提到,除了UserModel外,POI还提供了另一种解析Excel的模型:EventModel事件模型。不同于用户模型的DOM解析,事件模型采用了SAX的方式去解析Excel。
EventModel & SAX解析
SAX的全称是Simple API for XML,是一种基于事件驱动的XML解析方法。不同于DOM一次性读入XML,SAX会采用边读取边处理的方式进行XML操作。简单来讲,SAX解析器会逐行地去扫描XML文档,当遇到标签时会触发解析处理器,从而触发相应的事件Handler。我们要做的就是继承DefaultHandler类,重写一系列事件处理方法,即可对Excel文件进行相应的处理。
下面是一个简单的SAX解析的示例,这是要解析的XML文件:一个sku表,其中包含两个sku节点,每个节点有一个id属性和三个子节点。
<?xml version="1.0" encoding="UTF-8"?>
<skus>
<sku id="345000">
<name>电脑A</name>
<price>5999.0</price>
</sku>
<sku id="345001">
<name>手机C</name>
<price>4599.0</price>
</sku>
</skus>对照XML结构,创建Java实体类:
import lombok.Data;
@Data
public class Sku {
private Long id;
private String name;
private Double price;
}自定义事件处理类SkuHandler:
import com.alibaba.fastjson.JSON;
import org.shy.domain.pojo.Sku;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SkuHandler extends DefaultHandler {
/**
* 当前正在处理的sku
*/
private Sku sku;
/**
* 当前正在处理的节点名称
*/
private String tagName;
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if ("sku".equals(qName)) {
sku = new Sku();
sku.setId(Long.valueOf((attributes.getValue("id"))));
}
tagName = qName;
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
if ("sku".equals(qName)) {
System.out.println(JSON.toJSONString(sku));
// 处理业务逻辑
// ...
}
tagName = null;
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
if ("name".equals(tagName)) {
sku.setName(new String(ch, start, length));
}
if ("price".equals(tagName)) {
sku.setPrice(Double.valueOf(new String(ch, start, length)));
}
}
}其中,SkuHandler重写了三个事件响应方法:
startElement()——每当扫描到新XML元素时,调用此方法,传入XML标签名称qName,XML属性列表attributes;
characters()——每当扫描到未在XML标签中的字符串时,调用此方法,传入字符数组、起始下标和长度;
endElement()——每当扫描到XML元素的结束标签时,调用此方法,传入XML标签名称qName。
我们用一个变量tagName存储当前扫描到的节点信息,每次扫描节点发送变化时,更新tagName;
用一个Sku实例维护当前读入内存的Sku信息,每当该Sku读取完成时,我们打印该Sku信息,并执行相应业务逻辑。这样,就可以做到一次读取一条Sku信息,边解析边处理。由于每行Sku结构相同,因此,只需要在内存维护一条Sku信息即可,避免了一次性把所有信息读入内存。
调用SAX解析器时,使用SAXParserFactory创建解析器实例,解析输入流即可,Main方法如下:
import org.shy.xlsx.sax.handler.SkuHandler;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import java.io.InputStream;
public class MySax {
public static void main(String[] args) throws Exception {
parseSku();
}
public static void parseSku() throws Exception {
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
SAXParser saxParser = saxParserFactory.newSAXParser();
InputStream inputStream = ClassLoader.getSystemResourceAsStream("skus.xml");
saxParser.parse(inputStream, new SkuHandler());
}
}输出结果如下:
{"id":345000,"name":"电脑A","price":5999.0}
{"id":345001,"name":"手机C","price":4599.0}以上演示了SAX解析的基础原理。EventModel的API更复杂,同样通过重写Event handler,实现SAX解析。有兴趣的读者,请参见POI官网的示例代码: https://poi.apache.org/components/spreadsheet/how-to.html
EventModel的局限
POI官方提供的EventModel API虽然使用SAX方式解决了DOM解析的问题,但是存在一些局限性:
① 属于low level API,抽象级别低,相对比较复杂,学习使用成本高。
② 对于HSSF和XSSF类型的处理方式不同,代码需要根据不同类型分别做兼容。
③ 未能完美解决内存溢出问题,内存开销仍有优化空间。
④ 仅用于Excel解析,不支持Excel写入。
因此,笔者不建议使用POI原生的EventModel,至于有哪些更推荐的工具,请看下文。
(2)SXSSF
SXSSF简介
SXSSF,全称Streaming XML SpreadSheet Format,是POI 3.8-beta3版本后推出的低内存占用的流式Excel API,旨在解决Excel写入时的内存问题。它是XSSF的扩展,当需要将大批量数据写入Excel中时,只需要用SXSSF替换XSSF即可。SXSSF的原理是滑动窗口——在内存中保存一定数量的行,其余行存储在磁盘。这么做的好处是内存优化,代价是失去了随机访问的能力。SXSSF可以兼容XSSF的绝大多数API,非常适合了解UserModel的开发者。
内存优化会难以避免地带来一定限制:
① 在某个时间点只能访问有限数量的行,因为其余行并未被加载入内存。
② 不支持需要随机访问的XSSF API,如删除/移动行、克隆sheet、公式计算等。
③ 不支持Excel读取操作。
④ 正因为它是XSSF的扩展,所以不支持写入Xls文件。
UserModel、EventModel、SXSSF对比
到这里就介绍完了所有的POI Excel API,下表是所有这些API的功能对比,来自POI官网:
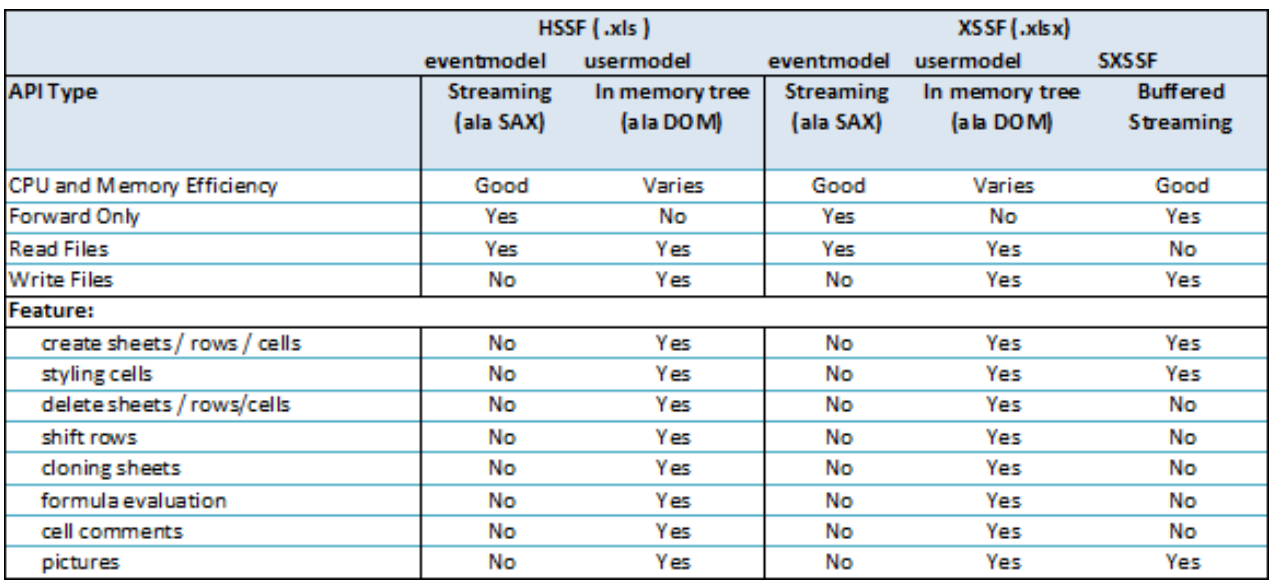
可以看到,UserModel基于DOM解析,功能是最齐全的,支持随机访问,唯一缺点是CPU和内存效率不稳定;
EventModel是POI提供的流式读取方案,基于SAX解析,仅支持向前访问,其余API不支持;
SXSSF是POI提供的流式写入方案,同样仅能向前访问,支持部分XSSF API。
(3)EasyExcel
EasyExcel简介
为了解决POI原生的SAX解析的问题,阿里基于POI二次开发了EasyExcel。下面是引用自EasyExcel官网的介绍:
Java解析、生成Excel比较有名的框架有Apache poi、jxl。但他们都存在一个严重的问题就是非常的耗内存,poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有一些缺陷,比如07版Excel解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。
easyexcel重写了poi对07版Excel的解析,一个3M的excel用POI sax解析依然需要100M左右内存,改用easyexcel可以降低到几M,并且再大的excel也不会出现内存溢出;03版依赖POI的sax模式,在上层做了模型转换的封装,让使用者更加简单方便。
如介绍所言,EasyExcel同样采用SAX方式解析,但由于重写了xlsx的SAX解析,优化了内存开销;对xls文件,在上层进一步进行了封装,降低了使用成本。API上,采用注解的方式去定义Excel实体类,使用方便;通过事件监听器的方式做Excel读取,相比于原生EventModel,API大大简化;写入数据时,EasyExcel对大批数据,通过重复多次写入的方式从而降低内存开销。
EasyExcel最大的优势是使用简便,十分钟可以上手。由于对POI的API都做了高级封装,所以适合不想了解POI基础API的开发者。总之,EasyExcel是一款值得一试的API。
使用EasyExcel
引入easyexcel依赖:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>2.2.3</version>
</dependency>首先,用注解定义Excel实体类:
import com.alibaba.excel.annotation.ExcelProperty;
import lombok.Data;
@Data
public class Sku {
@ExcelProperty(index = 0)
private Long id;
@ExcelProperty(index = 1)
private String name;
@ExcelProperty(index = 2)
private Double price;
}接下来,重写AnalysisEventListener中的invoke和doAfterAllAnalysed方法,这两个方法分别在监听到单行解析完成的事件时和全部解析完成的事件时调用。每次单行解析完成时,我们打印解析结果,代码如下:
import com.alibaba.excel.EasyExcel;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.event.AnalysisEventListener;
import com.alibaba.fastjson.JSON;
import org.shy.domain.pojo.easyexcel.Sku;
public class MyEasyExcel {
public static void main(String[] args) {
parseSku();
}
public static void parseSku() {
//读取文件路径
String fileName = "D:\\sunhaoyu8\\Documents\\Files\\excel.xlsx";
//读取excel
EasyExcel.read(fileName, Sku.class, new AnalysisEventListener<Sku>() {
@Override
public void invoke(Sku sku, AnalysisContext analysisContext) {
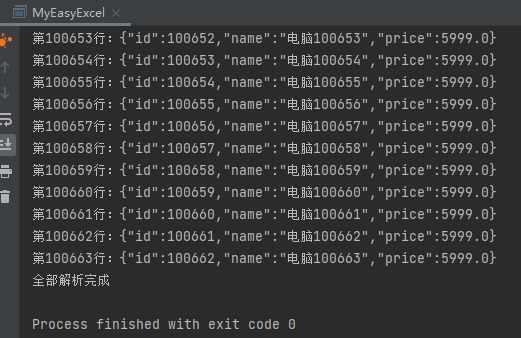
System.out.println("第" + analysisContext.getCurrentRowNum() + "行:" + JSON.toJSONString(sku));
}
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
System.out.println("全部解析完成");
}
}).sheet().doRead();
}
}测验一下,用它解析一个十万行的excel,该文件用UserModel读取会OOM,如下:
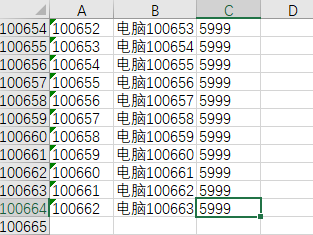
运行结果:
(4)Xlsx-streamer
Xlsx-streamer简介
Xlsx-streamer是一款用于流式读取Excel的工具,同样基于POI二次开发。虽然EasyExcel可以很好地解决Excel读取的问题,但解析方式为SAX,需要通过实现监听器以事件驱动的方式进行解析。有没有其他的解析方式呢?Xlsx-streamer给出了答案。
译自官方文档的描述:
如果您过去曾使用 Apache POI 读取 Excel 文件,您可能会注意到它的内存效率不是很高。 阅读整个工作簿会导致严重的内存使用高峰,这会对服务器造成严重破坏。 Apache 必须读取整个工作簿的原因有很多,但其中大部分与该库允许您使用随机地址进行读写有关。 如果(且仅当)您只想以快速且内存高效的方式读取 Excel 文件的内容,您可能不需要此功能。 不幸的是,POI 库中唯一用于读取流式工作簿的东西要求您的代码使用类似 SAX 的解析器。 该 API 中缺少所有友好的类,如 Row 和 Cell。 该库充当该流式 API 的包装器,同时保留标准 POI API 的语法。 继续阅读,看看它是否适合您。 注意:这个库只支持读取 XLSX 文件。
如介绍所言,Xlsx-streamer最大的便利之处是兼容了用户使用POI UserModel的习惯,它对所有的UserModel接口都给出了自己的流式实现,如StreamingSheet、StreamingRow等,对于熟悉UserModel的开发者来说,几乎没有学习门槛,可以直接使用UserModel访问Excel。
Xlsx-streamer的实现原理和SXSSF相同,都是滑动窗口——限定读入内存中的数据大小,将正在解析的数据读到内存缓冲区中,形成一个临时文件,以防止大量使用内存。缓冲区的内容会随着解析的过程不断变化,当流关闭后,临时文件也将被删除。由于内存缓冲区的存在,整个流不会被完整地读入内存,从而防止了内存溢出。
与SXSSF一样,因为内存中仅加载入部分行,故牺牲了随机访问的能力,仅能通过遍历顺序访问整表,这是不可避免的局限。换言之,如果调用StreamingSheet.getRow(int rownum)方法,该方法会获取sheet的指定行,会抛出“不支持该操作”的异常。
Xlsx-streamer最大的优势是兼容UserModel,尤其适合那些熟悉UserModel又不想使用繁琐的EventModel的开发者。它和SXSSF一样,都通过实现UserModel接口的方式给出解决内存问题的方案,很好地填补了SXSSF不支持读取的空白,可以说它是“读取版”的SXSSF。
使用Xlsx-streamer
引入pom依赖:
<dependency>
<groupId>com.monitorjbl</groupId>
<artifactId>xlsx-streamer</artifactId>
<version>2.1.0</version>
</dependency>下面是一个使用xlsx-streamer的demo:
import com.monitorjbl.xlsx.StreamingReader;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import java.io.FileInputStream;
public class MyXlsxStreamer {
public static void main(String[] args) throws Exception {
parseSku();
}
public static void parseSku() throws Exception {
FileInputStream in = new FileInputStream("D:\\sunhaoyu8\\Documents\\Files\\excel.xlsx");
Workbook wk = StreamingReader.builder()
//缓存到内存中的行数,默认是10
.rowCacheSize(100)
//读取资源时,缓存到内存的字节大小,默认是1024
.bufferSize(4096)
//打开资源,必须,可以是InputStream或者是File
.open(in);
Sheet sheet = wk.getSheetAt(0);
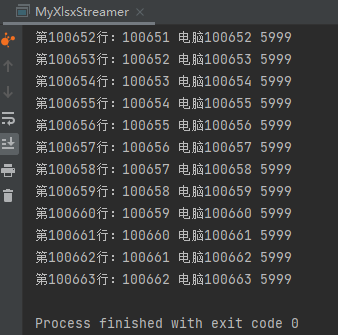
for (Row r : sheet) {
System.out.print("第" + r.getRowNum() + "行:");
for (Cell c : r) {
if (c != null) {
System.out.print(c.getStringCellValue() + " ");
}
}
System.out.println();
}
}
}如代码所示,Xlsx-streamer的使用方法为:使用StreamingReader进行参数配置和流式读取,我们可以手动配置固定的滑动窗口大小,有两个指标,分别是缓存在内存中的最大行数和缓存在内存的最大字节数,这两个指标会同时限制该滑动窗口的上限。接下来,我们可以使用UserModel的API去遍历访问读到的表格。
使用十万行量级的excel文件实测一下,运行结果:
StAX解析
Xlsx-streamer底层采用的解析方式,被称作StAX解析。StAX于2004年3月在JSR 173规范中引入,是JDK 6.0推出的新特性。它的全称是Streaming API for XML,流式XML解析。更准确地讲,称作“流式拉分析”。之所以称作拉分析,是因为它和“流式推分析”——SAX解析相对。
之前我们提到,SAX解析是一种事件驱动的解析模型,每当解析到标签时都会触发相应的事件Handler,将事件“推”给响应器。在这样的推模型中,解析器是主动,响应器是被动,我们不能选择想要响应哪些事件,因此这样的解析比较不灵活。
为了解决SAX解析的问题,StAX解析采用了“拉”的方式——由解析器遍历流时,原来的响应器变成了驱动者,主动遍历事件解析器(迭代器),从中拉取一个个事件并处理。在解析过程中,StAX支持使用peek()方法来"偷看"下一个事件,从而决定是否有必要分析下一个事件,而不必从流中读取事件。这样可以有效提高灵活性和效率。
下面用StAX的方式再解析一下相同的XML:
<?xml version="1.0" encoding="UTF-8"?>
<skus>
<sku id="345000">
<name>电脑A</name>
<price>5999.0</price>
</sku>
<sku id="345001">
<name>手机C</name>
<price>4599.0</price>
</sku>
</skus>这次我们不需要监听器,把所有处理的逻辑集成在一个方法中:
import com.alibaba.fastjson.JSON;
import org.apache.commons.lang3.StringUtils;
import org.shy.domain.pojo.Sku;
import javax.xml.stream.XMLEventReader;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.events.Attribute;
import javax.xml.stream.events.StartElement;
import javax.xml.stream.events.XMLEvent;
import java.io.InputStream;
import java.util.Iterator;
public class MyStax {
/**
* 当前正在处理的sku
*/
private static Sku sku;
/**
* 当前正在处理的节点名称
*/
private static String tagName;
public static void main(String[] args) throws Exception {
parseSku();
}
public static void parseSku() throws Exception {
XMLInputFactory inputFactory = XMLInputFactory.newInstance();
InputStream inputStream = ClassLoader.getSystemResourceAsStream("skus.xml");
XMLEventReader xmlEventReader = inputFactory.createXMLEventReader(inputStream);
while (xmlEventReader.hasNext()) {
XMLEvent event = xmlEventReader.nextEvent();
// 开始节点
if (event.isStartElement()) {
StartElement startElement = event.asStartElement();
String name = startElement.getName().toString();
if ("sku".equals(name)) {
sku = new Sku();
Iterator iterator = startElement.getAttributes();
while (iterator.hasNext()) {
Attribute attribute = (Attribute) iterator.next();
if ("id".equals(attribute.getName().toString())) {
sku.setId(Long.valueOf(attribute.getValue()));
}
}
}
tagName = name;
}
// 字符
if (event.isCharacters()) {
String data = event.asCharacters().getData().trim();
if (StringUtils.isNotEmpty(data)) {
if ("name".equals(tagName)) {
sku.setName(data);
}
if ("price".equals(tagName)) {
sku.setPrice(Double.valueOf(data));
}
}
}
// 结束节点
if (event.isEndElement()) {
String name = event.asEndElement().getName().toString();
if ("sku".equals(name)) {
System.out.println(JSON.toJSONString(sku));
// 处理业务逻辑
// ...
}
}
}
}
}以上代码与SAX解析的逻辑是等价的,用XMLEventReader作为迭代器从流中读取事件,循环遍历事件迭代器,再根据事件类型做分类处理。有兴趣的小伙伴可以自己动手尝试一下,探索更多StAX解析的细节。
四、结论
EventModel、SXSSF、EasyExcel和Xlsx-streamer分别针对UserModel的内存占用问题给出了各自的解决方案,下面是对所有本文提到的Excel API的对比:
| UserModel | EventModel | SXSSF | EasyExcel | Xlsx-streamer | |
|---|---|---|---|---|---|
| 内存占用量 | 高 | 较低 | 低 | 低 | 低 |
| 全表随机访问 | 是 | 否 | 否 | 否 | 否 |
| 读Excel | 是 | 是 | 否 | 是 | 是 |
| 读取方式 | DOM | SAX | -- | SAX | StAX |
| 写Excel | 是 | 是 | 是 | 是 | 否 |
建议您根据自己的使用场景选择适合的API:
1. 处理大批量Excel文件的需求,推荐选择POI UserModel、EasyExcel;
2. 读取大批量Excel文件,推荐选择EasyExcel、Xlsx-streamer;
3. 写入大批量Excel文件,推荐选择SXSSF、EasyExcel。
使用以上API,一定可以满足关于Excel开发的需求。当然Excel API不止这些,还有许多同类型的API,欢迎大家多多探索和创新。
页面链接:
POI官网: https://poi.apache.org/
EasyExcel官网:https://easyexcel.opensource.alibaba.com
Xlsx-streamer Github: https://github.com/monitorjbl/excel-streaming-reader






