您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
记一次618军演压测TPS上不去排查及优化
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
记一次618军演压测TPS上不去排查及优化
jd****
2023-06-02
IP归属:北京
801浏览
本文内容主要介绍,618医药供应链质量组一次军演压测发现的问题及排查优化过程。旨在给大家借鉴参考。 ### 背景 本次军演压测背景是,2B业务线及多个业务侧共同和B中台联合军演。 ### 现象 当压测商品卡片接口的时候,cpu达到10%,TPS只有240不满足预期指标,但是TP99已经达到了1422ms。 ### 排查 对于这种TPS不满足预期目标,但是TP99又超高,其实它的原因有很多中可能,通过之前写过的文章对性能瓶颈的一个分析方式《性能测试监控指标及分析调优》,我们可以采用自下而上的策略去进行排查, 首先是操作系统层面的CPU、内存、网络带宽等,对于集团内部的压测,机器的配置、网络带宽,这些因素运维人员已经配置到最优的程度了,无需我们再关心是否是因为硬件资源系统层面导致的因素。 接下来从代码层面和JVM层面进行排查,可能是项目代码中出现了线程阻塞,导致线程出现等待,响应时间变长,请求不能及时打到被测服务器上。对于这种猜测,我们可以在压测过程中打线程dump文件,从dump文件中找到哪个线程一致处于等待状态,从而找到对应的代码,查看是否可以进行优化。这块同开发一同分析整个接口的调用链路,商品卡片接口调用运营端的优惠券的可领可用接口,通过查看此接口的ump监控那个,发现调用量其实并不高。接下来通过查看运营端机器的日志发现,调用可领可用优惠券接口已经超时了,并且机器CPU已经偏高,使用率平均在80%以上。是什么原因导致调用可领可用接口大量超时,成为了问题的关键点。 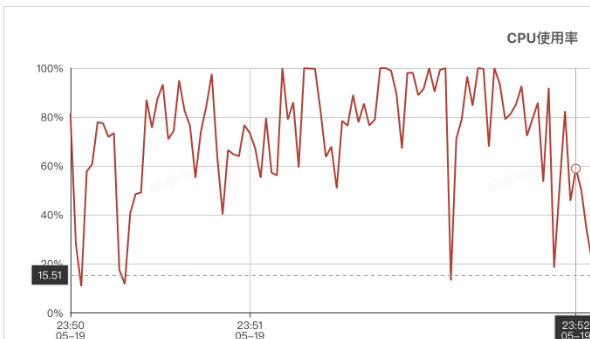 首先我们代码层面分析,这个可领可用优惠券接口还会调用一个过滤器进行过滤,于是猜测是不是这个过滤器接口把CPU打满了,但是通过监控过滤器接口的ump中可以看到它的TP99并不是很高,说明它的调用量没有上去,这种猜测可能不成立。还好当时代码这设置了一个开关是否使用过滤器,我们把过滤器的开关关闭后。再次进行压测商品卡片接口,发现还是没有解决问题,TPS仍然不高,并且TP99还是很高。说明这个猜测真是不成立的。 接下来我们转换思路,查看JVM日志,是否从中寻找到一些蛛丝马迹,果然从JVM的GC日志中可看到Ygc和Fgc的时间占用比较长,其中Fullgc的时间占用时间达到了7165ms,并且从中可以查看jvm的参数配置,发现Xms 和Xmx配置的值都是1024,只有1个G。问题的原因找到了,这台被压测的机器JVM参数配置的Xms 和Xmx值太小了,如果-Xmx指定偏小,应用可能会导致java.lang.OutOfMemory错误   对于JVM的介绍这部分比较庞大涉及到类加载方式、JVM内存模型、垃圾回收算法、垃圾收集器类型、GC日志,在这就不做详细说明了,想要了解详细内容可以看看《深入理解 JAVA 虚拟机》这本书。 此处简单说明下什么是Ygc和Fgc,以及Xms、Xmx的含义。 JVM内存模型中,分为新生代、老年代和元空间,新生代又分为eden区、Survivor0、Survivor1区。对象优先在Eden区分配,当Eden区没有足够空间时会进行一次Minor GC,执行完第一次MGC之后,存活的对象会被移动到Survivor(from)分区,当Survivor区存储满了之后会进行一次Ygc,但是Ygc一般不会影响应用。当老年代内存不足的时候,会进行一次Full GC,也就是Stop the world,系统将停止运行,清理整个内存堆(包括新生代和老年代) ,FullGC频率过大和时间过长,会严重影响系统的运行。 Xms,JVM初始分配的堆内存 Xmx,JVM最大分配的堆内存 一般情况这两个参数配置的值是相等的,以避免在每次GC 后堆内存重新进行分配。 ### 优化 最后修改机器的JVM数配置 查看JVM配置参数 重启后再次进行压测,我们的TPS指标上来了,并且TP99的值也下去了。达到了预期的一个目标。 ### 总结 其实对于一个性能瓶颈问题的分析排查定位,犹如医生看病,需要望闻问切,通过表面现象逐层的去排除一种种的可能性,最终找到其根本原因,对症下药解决问题。本文介绍的也只是性能瓶颈问题中的一个小小的部分,其实在压测过程中还会遇到各种各样的问题,但是我们掌握了方法论,其实都可以按照相同的思路去排查,最终找到根源。
上一篇:轻量灵动: 革新轻量级服务开发
下一篇:大型 3D 互动开发和优化实践
jd****
文章数
2
阅读量
1496
作者其他文章
01
记一次618军演压测TPS上不去排查及优化
本文内容主要介绍,618医药供应链质量组一次军演压测发现的问题及排查优化过程。旨在给大家借鉴参考。背景本次军演压测背景是,2B业务线及多个业务侧共同和B中台联合军演。现象当压测商品卡片接口的时候,cpu达到10%,TPS只有240不满足预期指标,但是TP99已经达到了1422ms。排查对于这种TPS不满足预期目标,但是TP99又超高,其实它的原因有很多中可能,通过之前写过的文章对性能瓶颈的一个分析
01
性能测试监控指标及分析调优
一、哪些因素会成为系统的瓶颈?1、CPU,如果存在大量的计算,他们会长时间不间断的占用CPU资源,导致其他资源无法争夺到CPU而响应缓慢,从而带来系统性能问题,例如频繁的FullGC,以及多线程造成的上下文频繁的切换,都会导致CPU繁忙,一般情况下CPU使用率<75%比较合适。2、内存,Java内存一般是通过jvm内存进行分配的,主要是用jvm中堆内存来存储Java创建的对象。内存的读写速度非常快
jd****
文章数
2
阅读量
1496
作者其他文章
01
性能测试监控指标及分析调优
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 jd****
jd**** 2023-06-02
2023-06-02 801浏览
801浏览






