您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
ChatGPT的原理与前端领域实践
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
ChatGPT的原理与前端领域实践
jd****
2023-05-22
IP归属:北京
1334浏览
AI研习社
# 一、ChatGPT 简介 ## ChatGPT的火爆 ChatGPT作为一个web应用,自22年12月发布,仅仅不到3个月的时间,月活用户就累积到1亿。在此之前,最快记录的保持着TikTok也需要9个月才打到月活1亿(PS:temu的月活目前还在千万级) 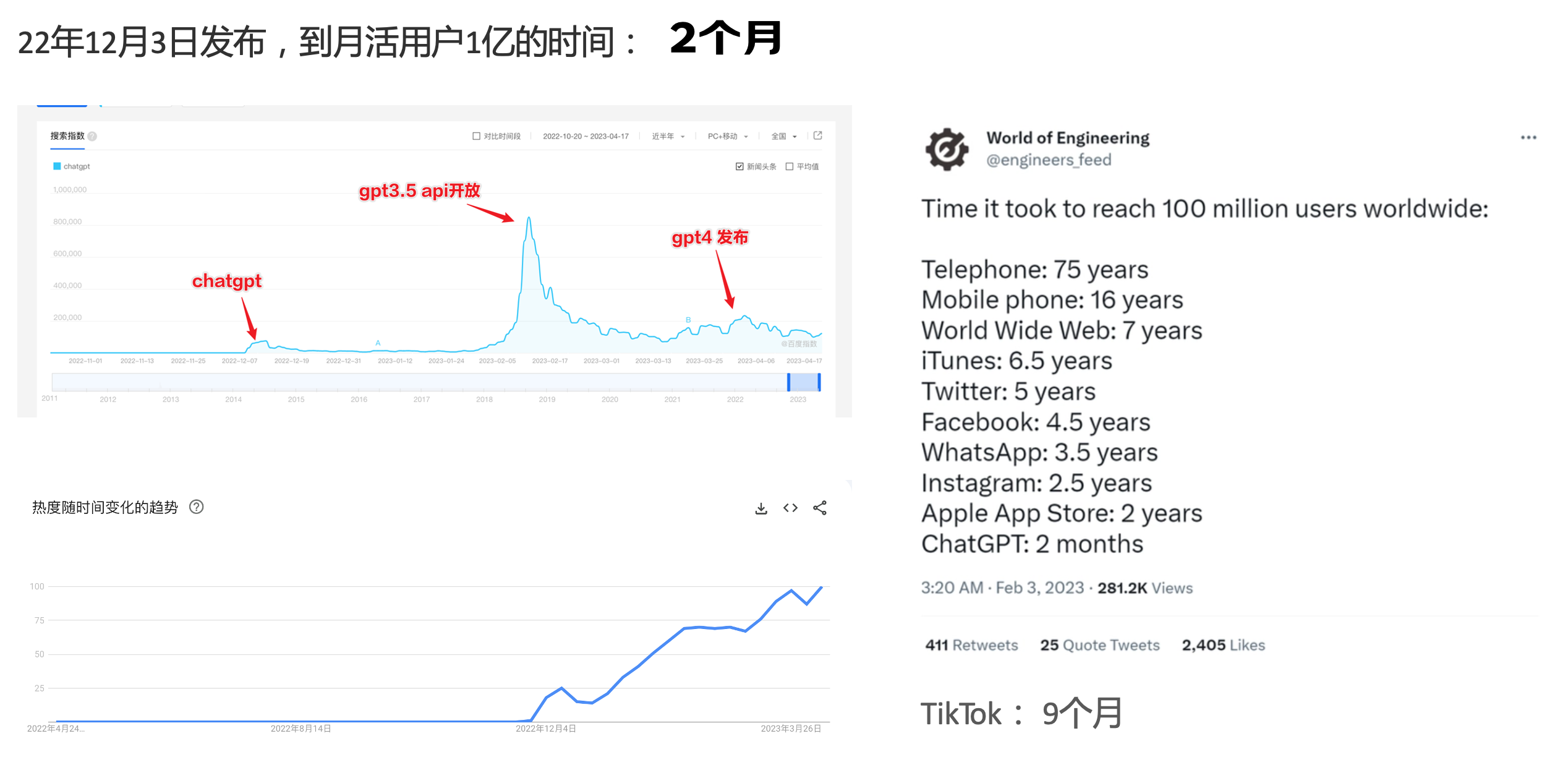 ## ChatGPT的反爬 https://chat.openai.com 因为各种政策&倾向性问题,ChatGPT目前在中国无法访问。而它又是如此火爆,所以就有大量用户通过代理、爬虫等形式来体验ChatGPT。 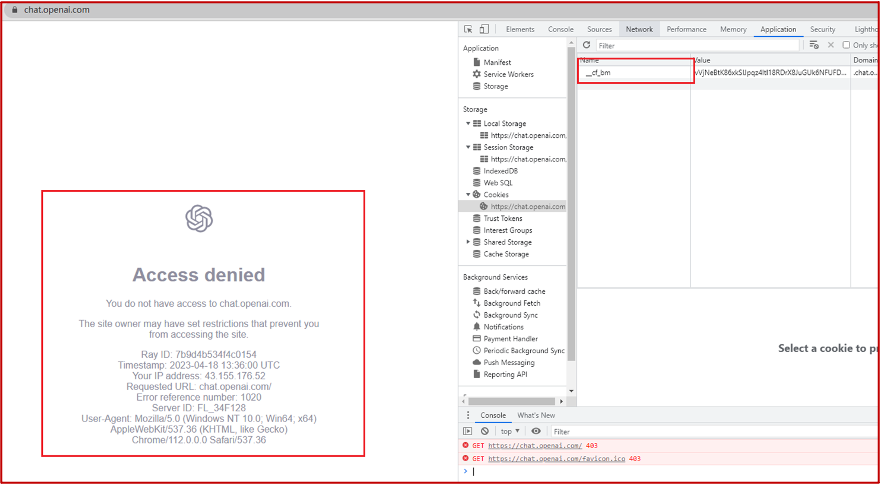 OpenAI不是专业做网络服务的公司,因此把反爬交给第三方公司CloudFlare去做。  CloudFlare目前全球最大CDN服务商,占比16%;而OpenAI的流量在CloudFlare中占比已经占据前二。 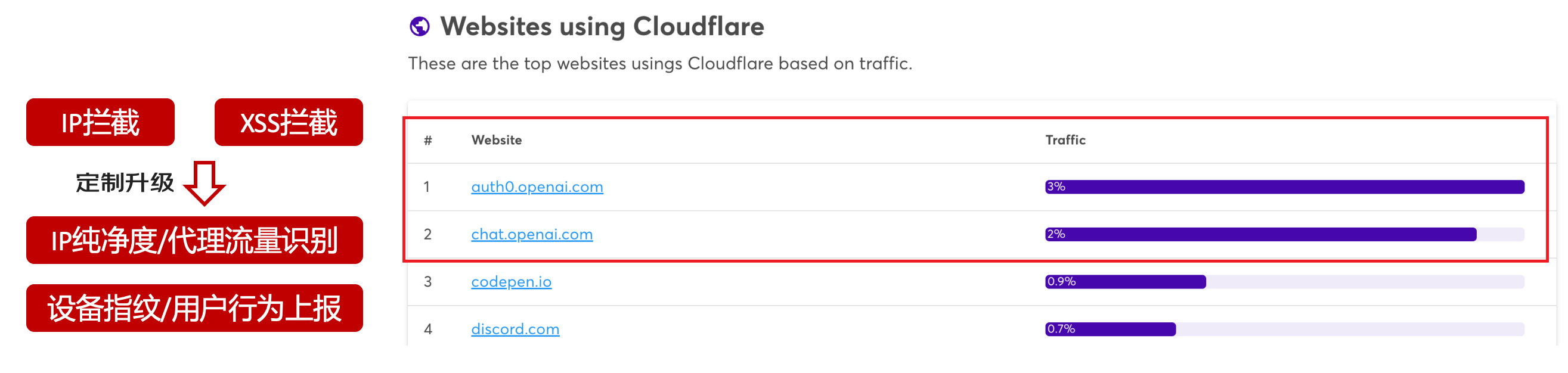 ## ChatGPT的打字效果  可以看到ChatGPT的输出是逐字输出的打字效果,这里应用到了SSE(SeverSideEvent)服务端推送的技术。一个SSE服务的Chrome开发工具化network截图 : 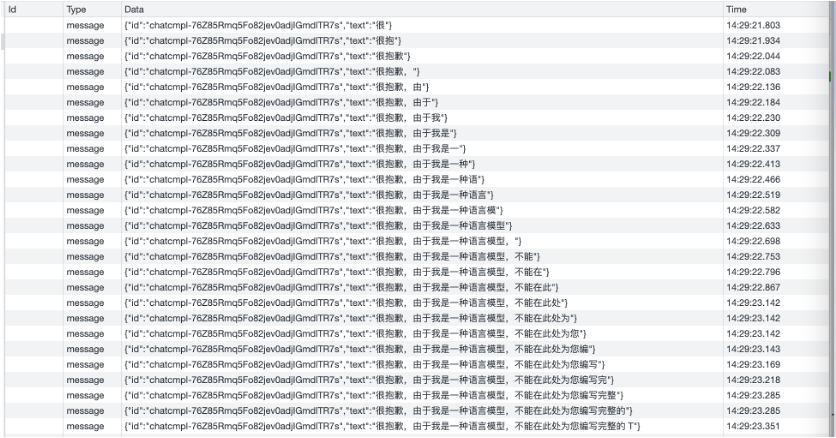 SSE对比常见Websocket如下: 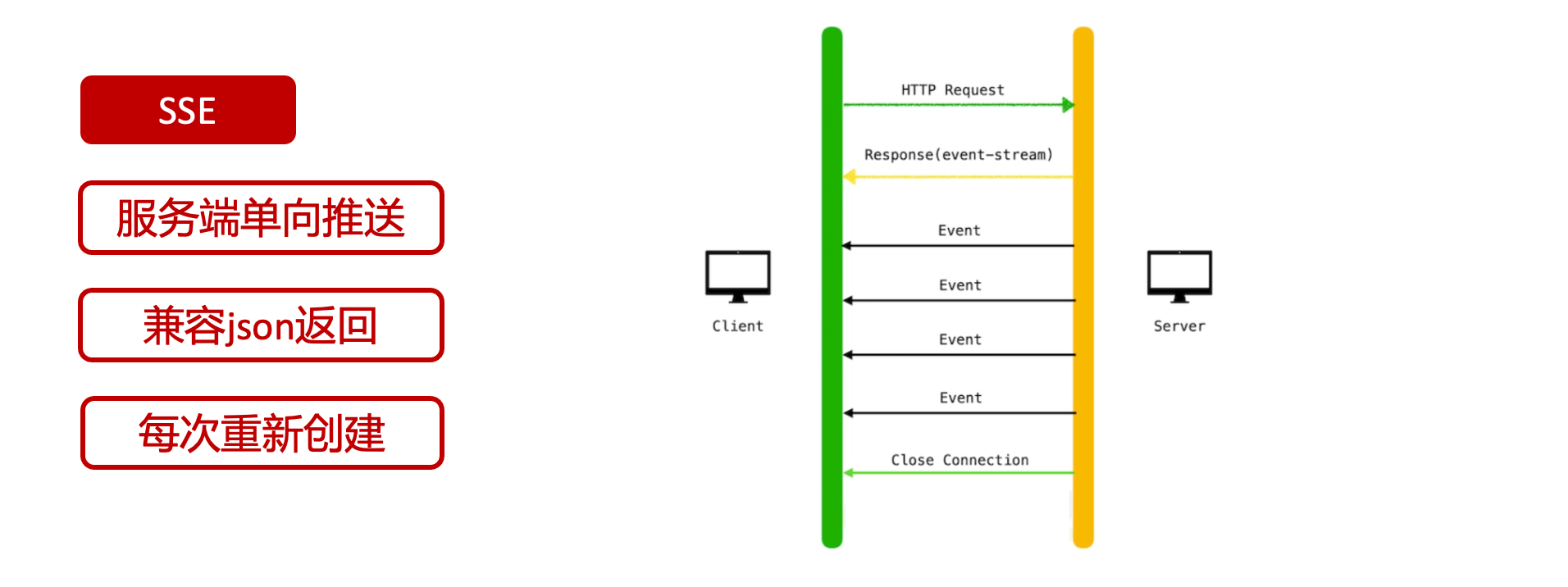 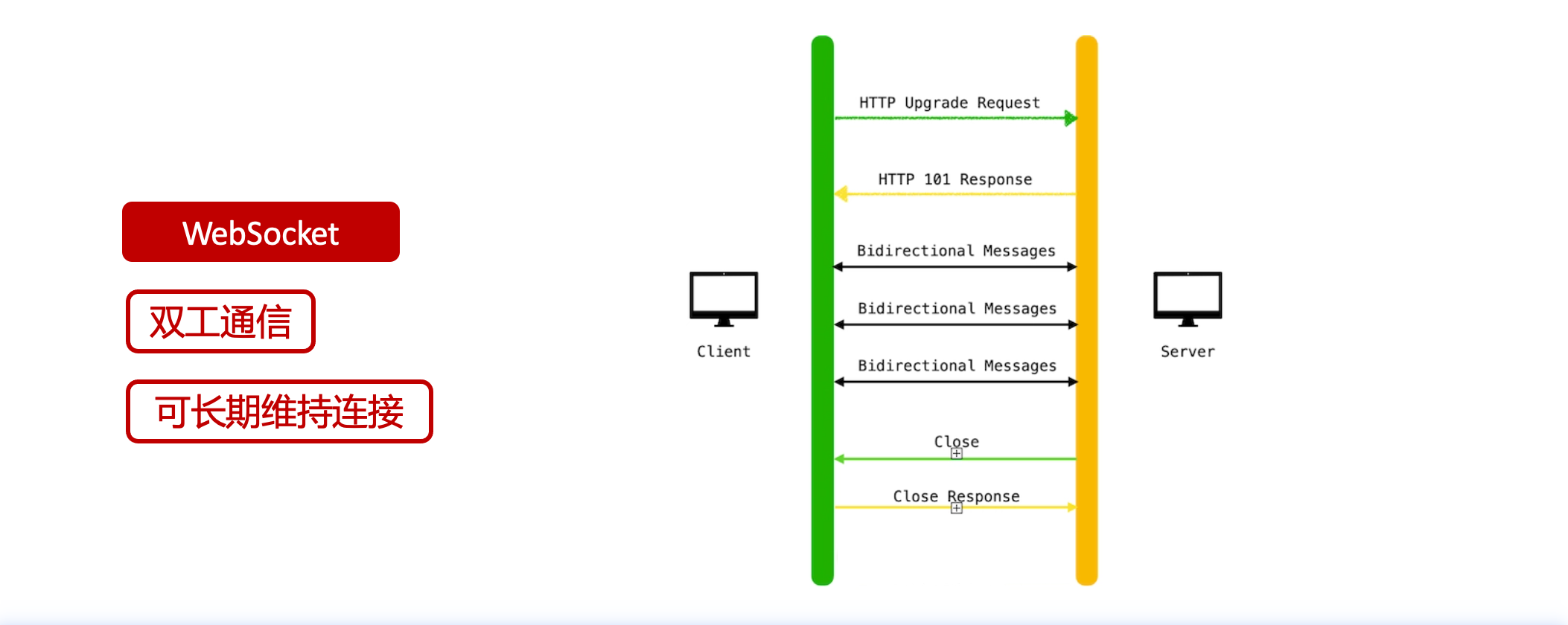 那么这种打字效果它是故意的还是不小心的? # 二、ChatGPT核心原理  ChatGPT我们可以拆解成 Chat、G、P、T 这四个部分讲述。在后续内容前,我们先补充几个机器学习容易理解的概念: 1. 模型:所谓模型,本质上就是一个程序(函数),类似 y=ax+bx^2,这里的a和b就是参数,比如GPT3的参数量就是175B说的就是1750亿参数的程序,ChatGLM-6B的参数量是60亿。 2. 机器学习:我们平时写的函数,是人来控制的逻辑和参数,而机器学习指的是机器通过某种方式(训练)来确认参数。这个找特定参数的函数的过程,一般分别为3步: 1. 确定函数集合:尽可能穷尽所有参数的可能,比如文章中常见的CNN、RNN、Transform等就是函数集合; 2. 数据:通过数据集,得到评价函数好坏的方式; 3. 执行过程的参数:比如每批次对每个函数执行多少次,最大执行多少次等,这些参数一般称为“超参”,区别于函数内的参数(算法工程师一般自嘲的调参工程师,指的是这个“超参”) ## Generative 文字接龙 ChatGPT本质上是个不断递归执行的生成式的函数,下面我们来看2个例子: ### Case1:萝卜青菜 当你看到`萝卜青菜`这4个字的时候,脑海中想的是什么? 我想大概率是`各有所爱`。 给到GPT的时候,GPT根据这4个字和逗号,推测出下个字的大概率是`各`  然后GPT会再次将`萝卜青菜,各`输入给自己,推测出下个字的大概率是`有`  这就是ChatGPT在输出文字时是逐字输出的原因,这种形式最符合LLM运行的底层原理,在用户体验上也能让用户更快看到第一个字,体验上接近聊天而不是阅读。`它是故意的`。这里我们得到第一个结论: **ChatGPT(模型 / Fn)的运行原理是每次输入文本(包含上次返回的内容),预测输出后续1个字词。** ### Case2:书呆子 举个[【原创】前端技术十年回顾](http://xingyun.jd.com/shendeng/article/detail/12948) 文章中的例子:  在这个例子中,为什么输出是“欺负一样”? 从全文中看,这里的主体应该是`前端技术`,单纯考虑`前端技术`和`就像在小学被`,我们可以想出“推广”、“普及。即使不考虑“前端技术”,单纯从`就像在小学被`,还有可能推测出后文是“教育”、“表扬”。都很难联想到“欺负”。 这里出现“欺负”,很大原因是在前文中`欺负(就像`,这几个关键字的影响远大于`前端技术`。所以我们得到第二个结论: **在生成式语言模型中,上文单词离得越远,对生成结果的影响就越小** ### 文字接龙VS完形填空 这里补充下GPT类似的BERT,他们都是基于后面提到的Transform结构,他们的对比如下,总的来说,文字接龙更服务人类大部分情况下的语言模式,因此像马斯克也更青睐于这种第一性原理的东西。  ## Transform 注意力机制 ### Case3:绿洲  在这个Case中,`绿洲`的出现,反而不是因为最近的`寻找新的`,而是3句话之前的`沙漠`和`骆驼`。这里就不得不提到大名鼎鼎的`Transform`结构,这是Google在2017年在一篇论文 [《Attention is all you need》](https://arxiv.org/abs/1706.03762)首次提出的一种类神经网络结构,它和核心是`自注意力机制`,用来解决长距离文本的权重问题。 作者不是机器学习专业,就不展开说了,建议看相关论文和讲解的文章。 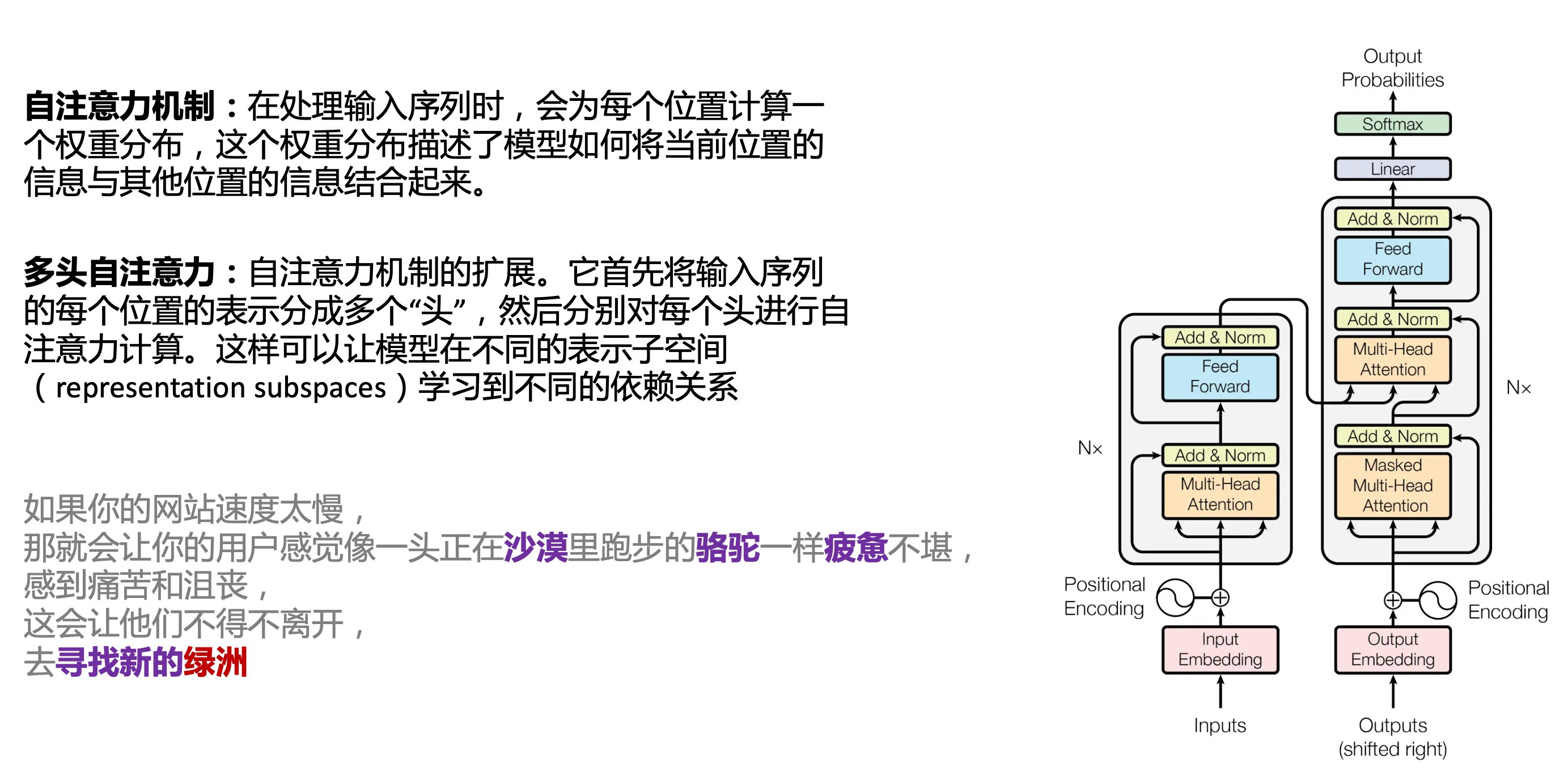 ## Pretrained 预训练 通过前面的文字接龙模式,用大量数据喂出来的预训练模型,使其具备通用的语言能力,这里的预训练有2层含义: 1. 能完成各种通用NLP任务(分类、排序、归纳等等) 2. 稍加微调训练,能完成特定领域的语言任务(不必从头开始)  ## Chat 对话(通过Finetuning实现) 因为预训练是无人类的监督,因此通用模型不一定按照聊天形式返回文本,因为它的训练素材包罗万象,比如我说`今天天气差`,它根据历史的经验:今天天气差的表述方式有下面几种,就会输出这句话的不同的表述,而不是像聊天一样跟我一起吐槽 。下面的OpenAI的GPT3模型对`今天天气差`的输出:  要让GPT3像聊天一样输出,就需要有针对性的对它就行微调(fine-tuning)训练,例如通过特定的问答结构的语料训练:  能聊天之后,想要上线,就必须给模型上枷锁,不能回答和人类价值观不符的内容,否则资本主义的铁拳也会降临😁 OpenAI通过人工标注和强化训练的方式提升ChatGPT回答质量并校正它的价值观倾向,想要更多了解这块内容,很建议阅读这篇神灯文章:[ChatGPT背后的模型三兄弟](http://xingyun.jd.com/shendeng/article/detail/12805 )  # 三、ChatGPT的应用 OpenAI官方给到了49个常见的ChatGPT应用场景:https://openai.com/blog/chatgpt  总的来说可以分为: 1. 文案创作 2. 提炼总结 3. 代码编写 4. 语言美化/跨语言转换 5. 角色扮演 对于前端开发同学来说,最关注它的代码能力。正好在一个小程序转taro重构的项目中体验了ChatGPT的能力: ### 1. 能理解小程序模板语法,并转换出ts的taro组件 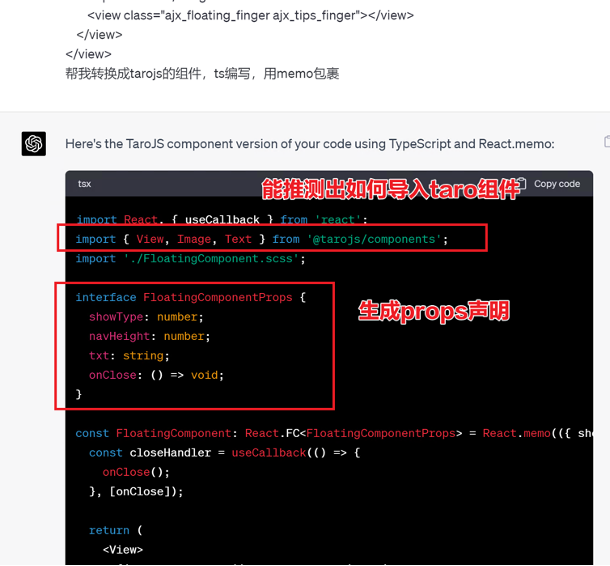 ### 2. 理解小程序页面逻辑,并修正props 小程序的页面逻辑page.js是独立于index.wxml的,在得到纯wxml生成的taro组件后,把page.js的代码合并进去 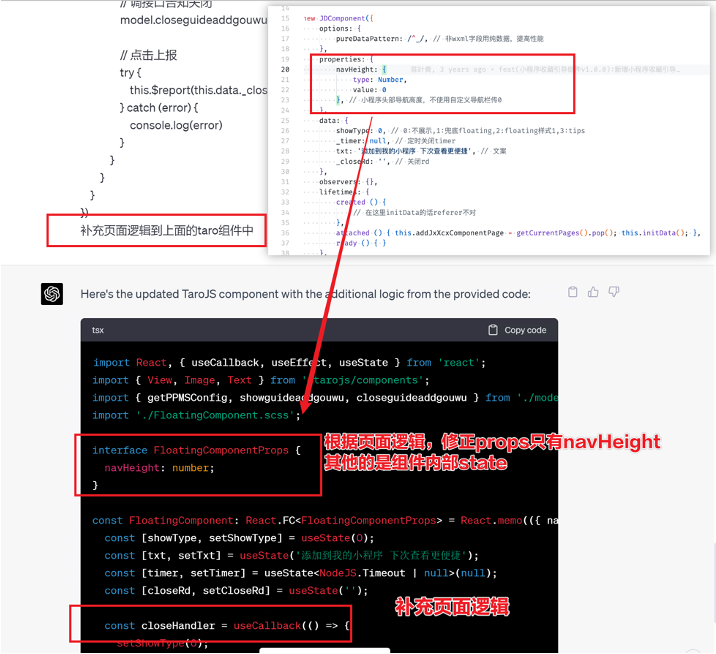 ### 3. 可以补充知识,教它举一反三特有的语法 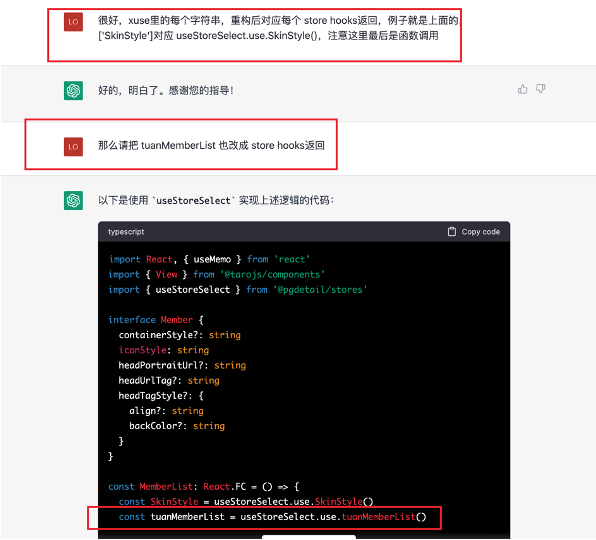 ## HiBox融合ChatGPT 这么好的能力,应该如何沉淀呢? 我们首先想到了VSCode插件,刚好HiBox本身有登录态、自定义Webview、远程配置化的能力,那就将ChatGPT集成到HiBox中(太酷啦),Node端接入ChatGPT的接口,通过Webview前端实现一个聊天窗,再通过配置系统集成常用的Prompt,这样前端开发就能通过VSCode方便地用到ChatGPT的能力。整体结构如下:  数据源方面,也从爬虫版本ChatGPT,逐步切换到API代理服务中,代理服务接入GPT3.5的模型能力,整体体验非常接近ChatGPT。代理服务文档:[https://joyspace.jd.com/pages/yLnDY3B5UJ1rXP8UYrN6](https://joyspace.jd.com/pages/yLnDY3B5UJ1rXP8UYrN6)  HiBox的ChatGPT目前仅需erp登录即可免费使用,更多使用方式和安装方式:[HiBox快速开始](http://doc.jd.com/szfe/hibox/docs/quickstart ) ## 私域数据集成 在使用ChatGPT的过程中,也注意到2个问题: 1. 公司敏感的代码和信息不能传给ChatGPT 2. 特定领域的非敏感知识,比如水滴模板,ChatGPT没学习过 首先想到的是,采用微调(fine-tuning)的方式,将私域数据数据集成到大语言模型(LLM)中,然后私有化部署在公司的服务器上,这样任意代码和文档都可以发送给它,我们尝试了下面2种方式: ### GPT3 fine-tuning 一是通过OpenAI官网提到的`GPT3`的`fine-tuning接口`,将私域数据传给OpenAI,OpenAI在他们的服务器里微调训练,然后部署在OpenAI的服务器中,整个过程是黑盒。  ### ChatGLM-6B fine-tuning 二是用清华开源的`ChatGLM-6B`作为基础模型,在公司的九数平台上申请GPU机器,将私域数据通过LORA的方式微调得到LORA权重,然后自己部署,整个过程完全私有化。 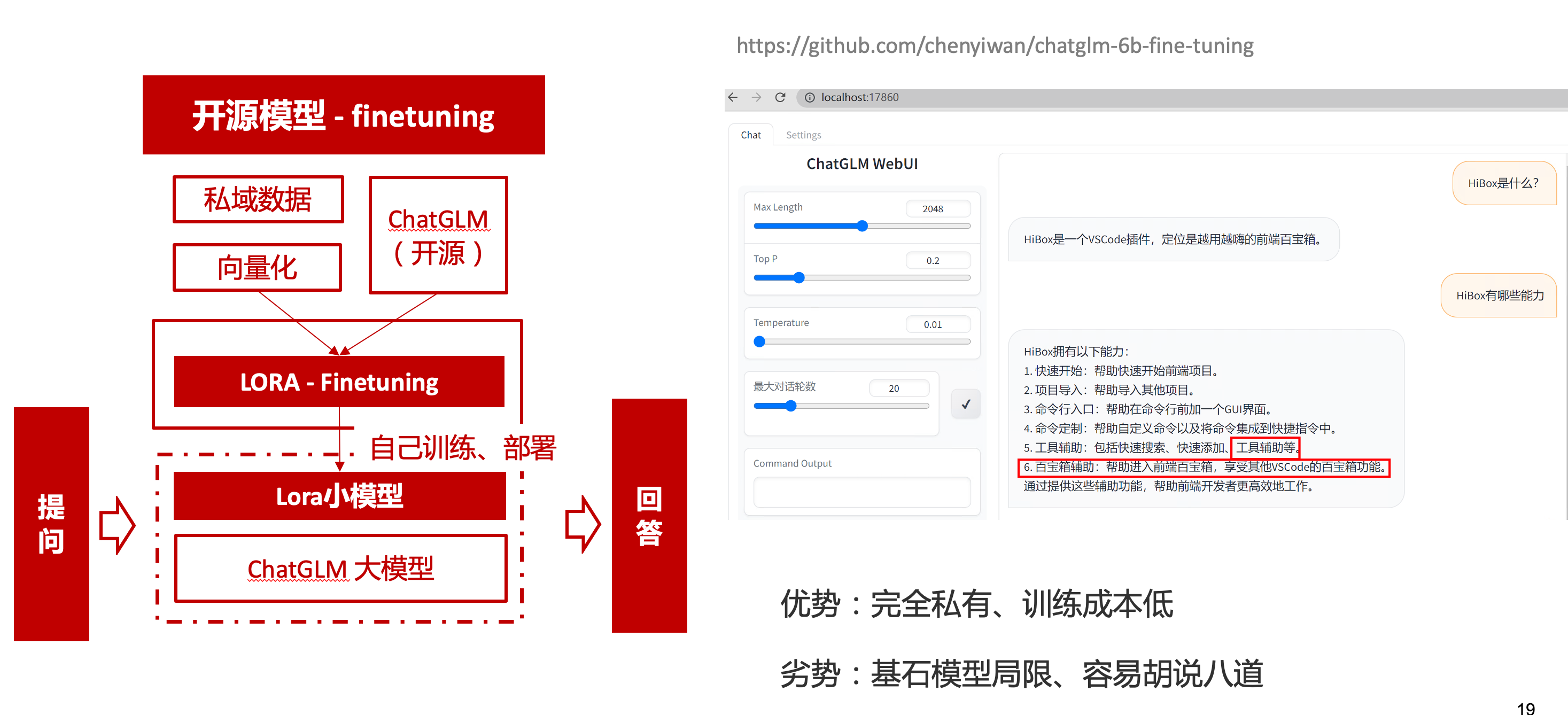 ### GPT3.5 langChain 上面的两种方式总的来说,部署后的推理效果都很难达到GPT3.5-API的效果,因此我们最后尝试了embedding外挂知识库的方式。使用开源的langchain处理文档切割、向量化存储、向量化匹配等。数据还是会暴露给OpenAI。 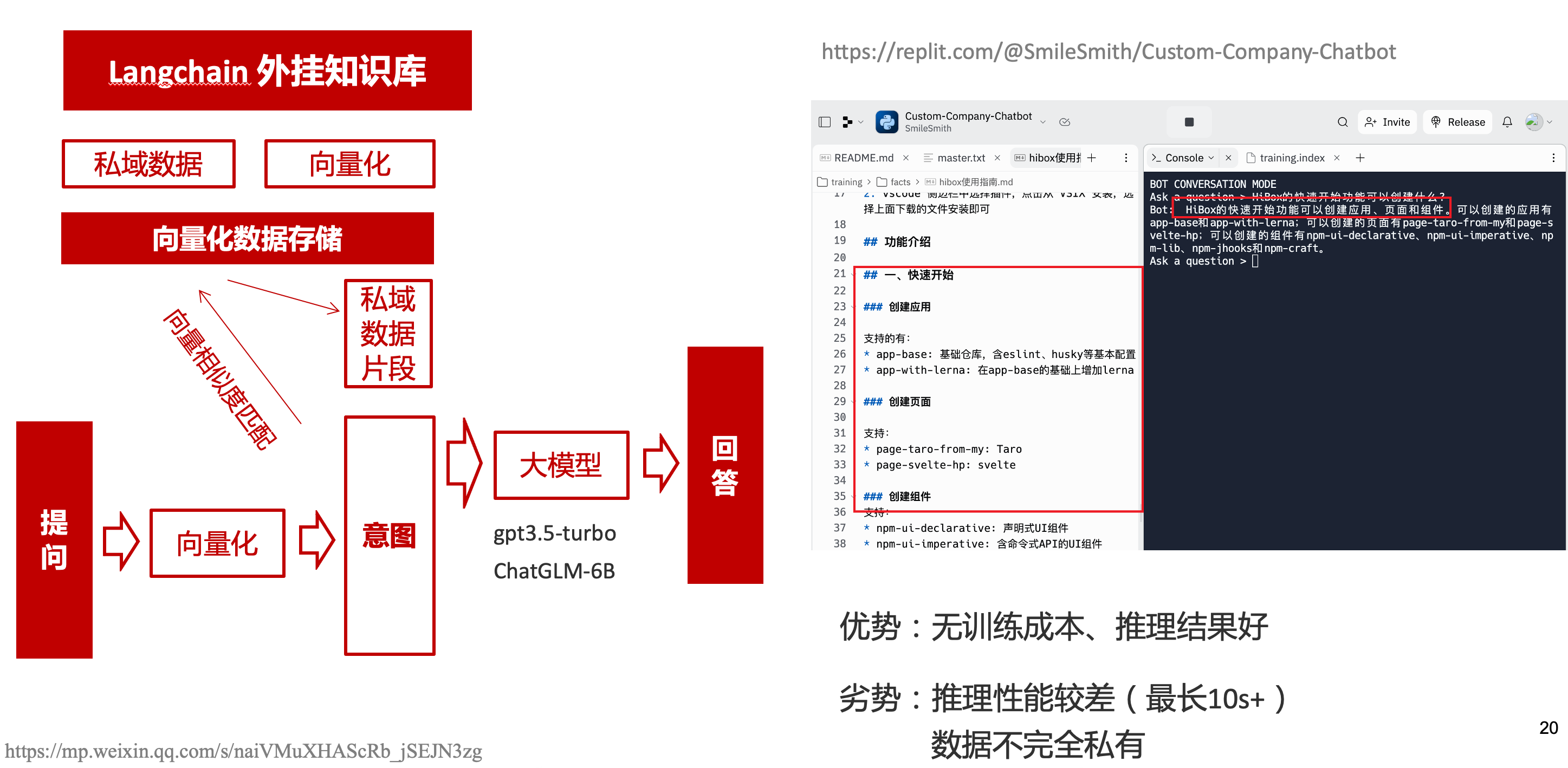 # 四、LLM现状和展望 ## LLM大爆发 其实在20年GPT3出来之后,机器学习的大部分头部都意识到了这条路线的可行性,积极地在跟进了: 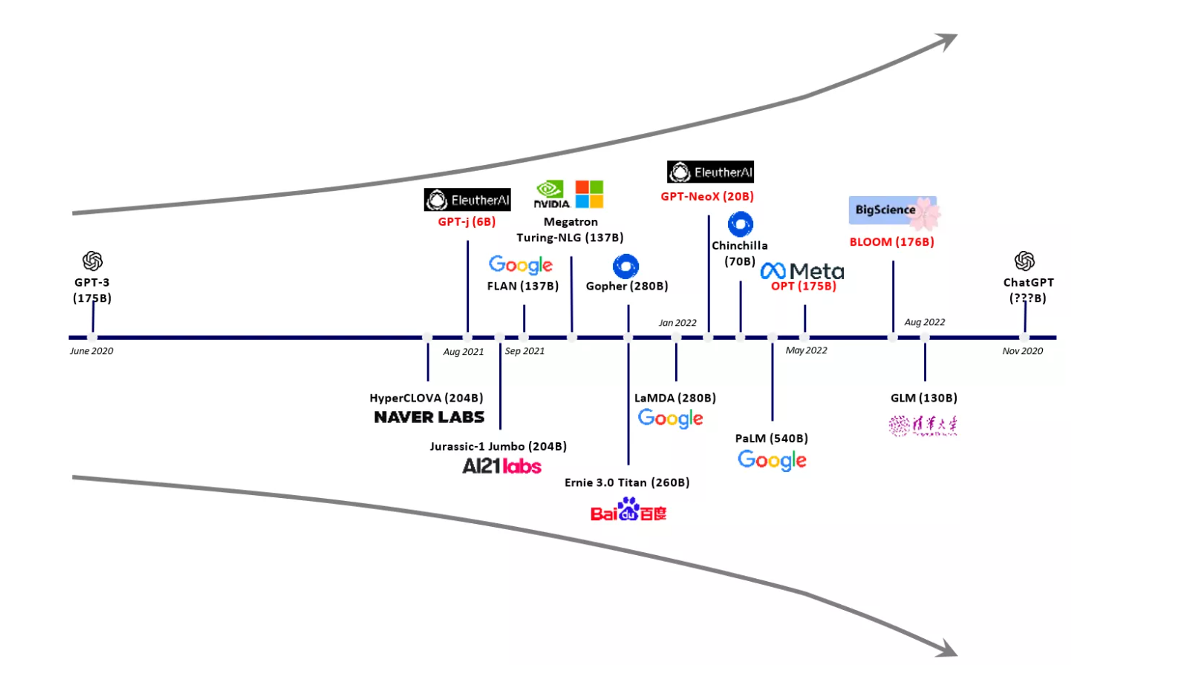 这里专门讲下百度,据公开可靠的文档,百度早在2019年就推出了Ernie(对标谷歌Bard,Ernie和bard在动画Muppet中是1对兄弟),确实是国内最早接入LLM的玩家。百度走的和谷歌一样,是BERT的完形填空的路线,因为在2018~2019年的时间点,GPT一代刚刚问世,第一代的GPT对比各方面都不如BERT,再加上百度和谷歌一样在搜索引擎方面沉淀较多,因此选择的路线是BERT。  近期羊驼系列和国内大语言模型也在大爆发: 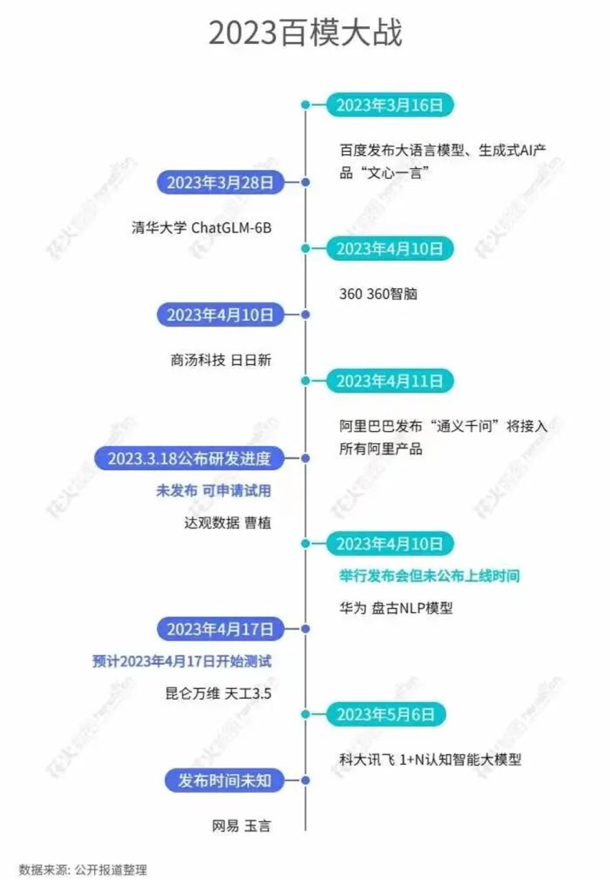 ## LLM应用现状&趋势 ### 平台化 LLM的角色扮演能力可能是下个`人机交互`变革的关键点,OpenAI也推出了Plugin模型,通过插件,用户可以通过一句自然语言聊天就买一张机票,搜索想看的文章。有人说这是类似AppStore发布的IPhone时刻:  ### 自驱动、能力集成 类似Auto-GPT,langchain等,通过约定特性的模板,可以让ChatGPT返回执行特定命令的文本,例如和ChatGPT约定如果要搜索的时候,返回`[search: 搜索内容]`,然后在客户端通过正则匹配 `/\[search\:(.*?)\]/`,拿到对应的内容执行搜索,再将结果返回给ChatGPT整理最终答案。 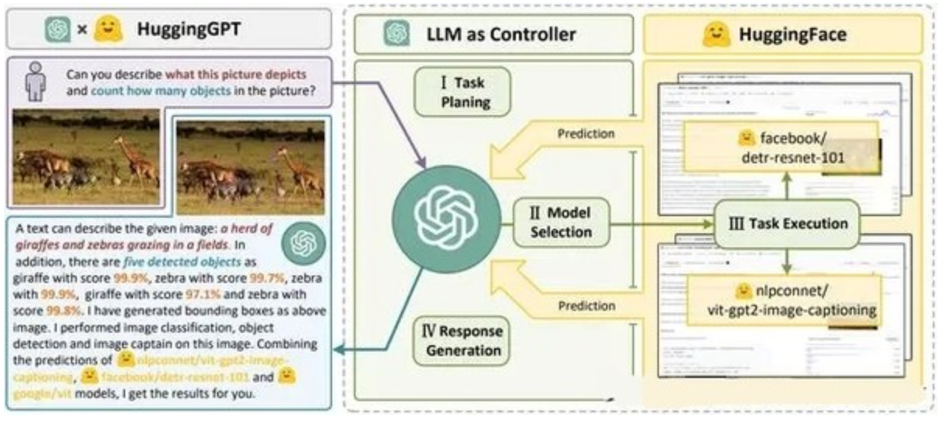 虚拟一个例子: ``` 1. user: 深圳明天的天气怎么样? 2. chatgpt(触发知识限制2021年,返回约定的搜索格式):[search:2023年4月27日的深圳天气] 3. user接收到正则匹配触发搜索,打开无头浏览器搜索百度并取第1条结果:2023年4月27日星期四深圳天气:多云,北风,风向角度:0°风力1-2级,风速:3km/h,全天气温22℃~27℃,气压值:1006,降雨量:0.0mm,相对湿度:84%,能见度:25km,紫外线指数:4, 日照... 4. user(将搜索的内容连带问题第二次发给ChatGPT): 深圳明天的天气怎么样?可参考的数据:2023年4月27日星期四深圳天气:多云,北风,风向角度:0°风力1-2级,风速:3km/h,全天气温22℃~27℃,气压值:1006,降雨量:0.0mm,相对湿度:84%,能见度:25km,紫外线指数:4, 日照... 5. chatgpt(根据问题和上下文,输出人类语言的表达): 深圳明天的天气还可以,整体多云为主,气温22℃~27℃ ``` ### 多模态 4月份发布的GPT4已经具备图像识别的能力,下面的Case是主持人用一致设计稿草图生成前端页面的过程。经典“前端已死”时刻: 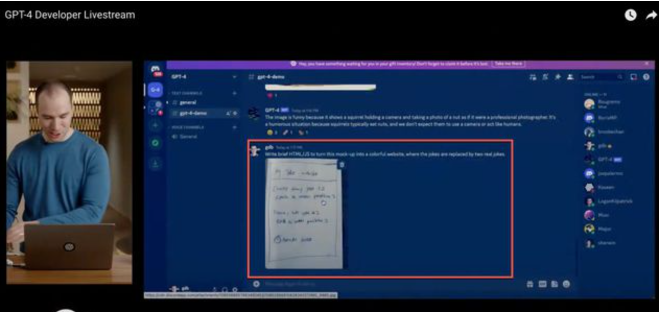 ## LLM的局限 虽然我们看到ChatGPT的技术强大,但是也要审慎看待它的局限,它本质上是个基于历史数据的`经验主义`的模仿人类的文字输出函数。 例如,ChatGPT完全做不了4位数的乘法运算,它大概率会根据`6乘`和`7等于`这2块关键信息,得到答案是`以2结尾`,根据`4`和`乘以3`这2块关键信息,得到答案是`以1开头`,而中间的随机性完全收敛不到正确的答案,不管是ChatGPT和GPT4都是一样的情况: 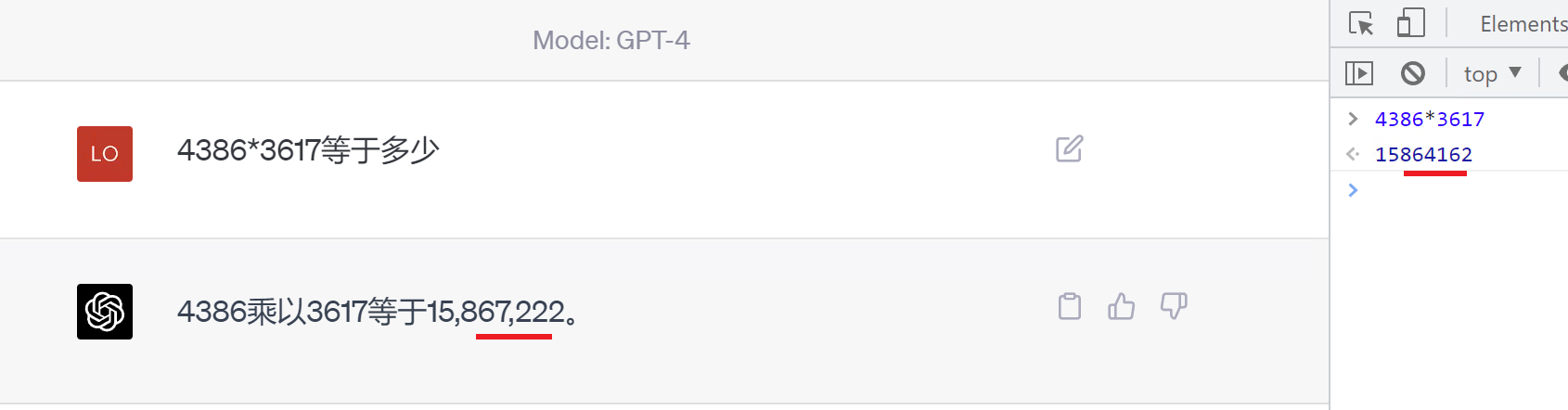 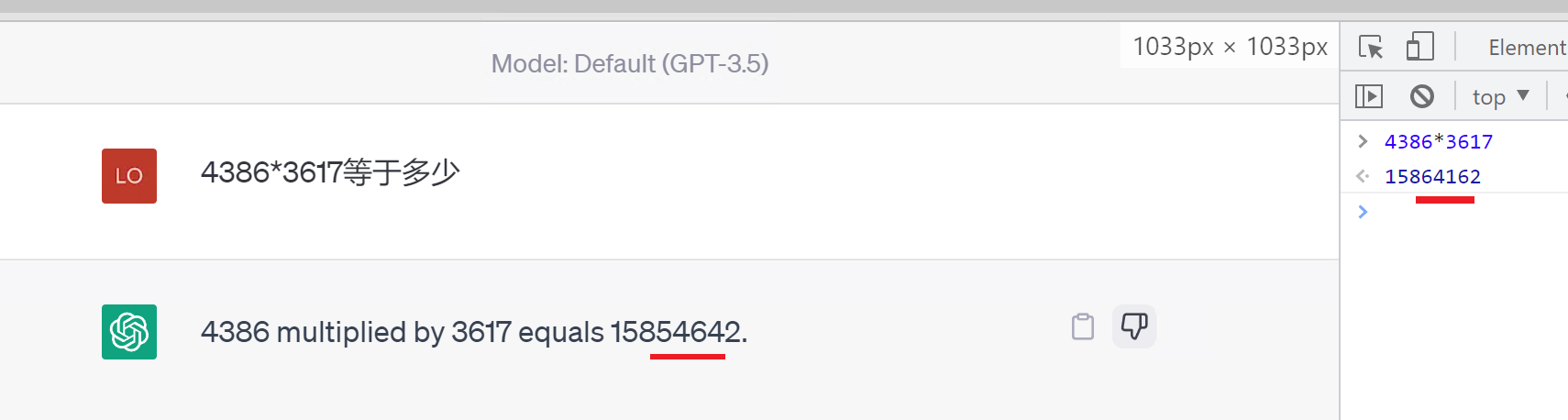 再比如问它特别小众、普通人也容易错的专业领域知识,它也会根据大部分普通人的错误答案输出错误答案: 比如在[V8 Promise源码全面解读,其实你对Promise一无所知](https://mp.weixin.qq.com/s/pgyoCoNi6RxEEumMZNFtpQ)文章中一个很奇葩的题目,下面的代码会打印什么? ``` Promise.resolve().then(() => { console.log(0); return Promise.resolve(4) }).then(res => { console.log(res); }) Promise.resolve().then(() => { console.log(1); }).then(() => { console.log(2); }).then(() => { console.log(3); }).then(() => { console.log(5); }).then(() => { console.log(6); }) ``` 大部分人都会回答:0、1、4、2、3、5、6 GPT3.5的回答:0、1、4、2、3、5、6 GPT4的回答:0、1、2、3、4、5、6 只有GPT-4的回答正确,但是即使它的回答正确,它的具体分析也是错误,因为它可能在某个场景学习过类似答案,但是它并不“理解”,后面的分析内容也是大部分人容易错的分析 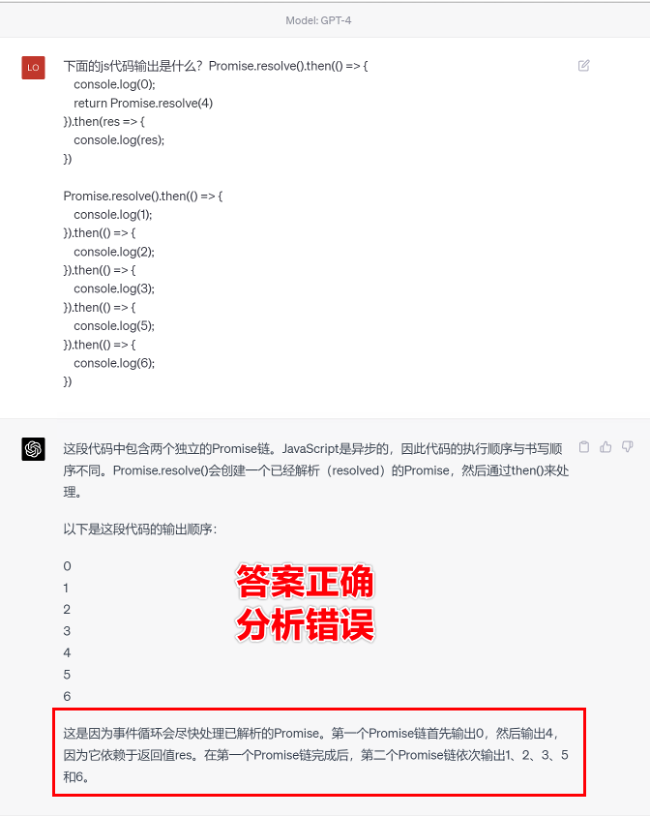 # 结尾 最后用流浪地球2中周喆直的台词做个结尾。 对于AI的到来,我们战略上不要高估它,AI本身有它的局限性,保持乐观,前端没那么容易死;战术重视和关注它的发展,尝试在我们的工作生活中应用,技术变革的浪潮不会随个人的意志变化。  通宵赶稿,码字不易,看到这里同学帮忙点个赞吧 Thanks♪(・ω・)ノ [视频回放](https://pc-elive.jd.com/#/B020BF0BDDF7434F4B39D10E6808D9A8/0)和[PPT附件](https://3.cn/109Ve-uya) 彩蛋:文章封面图是上图用SD+PS生成的 😁 
上一篇:你也能成为“黑客”高手-趣谈Linux Shell编程语言
下一篇:Serverless冷扩机器在压测中被击穿问题
相关文章
京东商城背后AI技术揭秘(一)——基于关键词自动生成摘要
NLP带来的“科幻感”超乎你的想象 - ACL2020论文解读(一)
京东商城背后AI技术揭秘(二)——基于商品要素的多模态商品摘要
jd****
文章数
3
阅读量
3895
作者其他文章
01
ChatGPT重磅更新,函数调用实战讲解,gpt3.5-16k模型,资费降低等
6月13日OpenAI最新博客突然发布了ChatGPT最新能力更新。重点如下:一、新功能:函数调用可以理解为将ChatGPT官网网页端的插件模式,移植到了OpenAI-API上,每个函数相当于原来ChatGPT-Plugin。第三方可以基于这套能力自行实现公司/团队内部的插件平台。如何使用函数调用以官网的天气查询为例子How_to_call_functions_with_chat_models,一
01
ChatGPT的原理与前端领域实践
一、ChatGPT 简介ChatGPT的火爆ChatGPT作为一个web应用,自22年12月发布,仅仅不到3个月的时间,月活用户就累积到1亿。在此之前,最快记录的保持着TikTok也需要9个月才打到月活1亿(PS:temu的月活目前还在千万级)ChatGPT的反爬https://chat.openai.com 因为各种政策&倾向性问题,ChatGPT目前在中国无法访问。而它又是如此火爆,所以就有大
01
ChatGPT七月小改款,支持个性化指令,HiBox插件同步更新支持!
一、ChatGPT-0720更新又在深夜,正要打开ChatGPT官网测试下pdf对话功能,发现ChatGPT又有更新。本次更新总结有2点:对于Plus用户,GPT-4的使用限额从25条/3h提升至50条(整整提升1倍~ $20的订阅费又更超值了)新增 Custom instructions (个性化指令),简单可以理解为个人角色和期望回答定义Why instructions?Custom inst
jd****
文章数
3
阅读量
3895
作者其他文章
01
ChatGPT重磅更新,函数调用实战讲解,gpt3.5-16k模型,资费降低等
01
ChatGPT七月小改款,支持个性化指令,HiBox插件同步更新支持!
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号










