



1. Spark SQL的自定义外接数据源的方式
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。而在真正开发过程当中,有时需要将自己定义的数据源来利用Spark sql进行上层接口的封装。针对这种情况,Spark Sql也有其扩展数据源的接口。
本节以https://www.cnblogs.com/QuestionsZhang/p/10430230.html当中的demo为例,来介绍它的自定义外接数据源的方式,并最终引出geomesa对于spark sql的扩展源码。
1.1 涉及到的API
BaseRelation提供了定义数据结构Schema的方法,类似tuples的数据结构。
TableScan,提供了扫描数据并生成RDD[ROW]的方法。
RelationProvider,拿到参数列表并返回一个BaseRelation。
1.2 代码实现
首先定义relation。
- package cn.zj.spark.sql.datasource
-
- import org.apache.hadoop.fs.Path
- import org.apache.spark.sql.{DataFrame, SQLContext, SaveMode}
- import org.apache.spark.sql.sources.{BaseRelation, CreatableRelationProvider, RelationProvider, SchemaRelationProvider}
- import org.apache.spark.sql.types.StructType
-
- /**
- * Created by rana on 29/9/16.
- */
- class DefaultSource extends RelationProvider with SchemaRelationProvider with CreatableRelationProvider {
- override def createRelation(sqlContext: SQLContext, parameters: Map[String, String]): BaseRelation = {
- createRelation(sqlContext, parameters, null)
- }
-
- override def createRelation(sqlContext: SQLContext, parameters: Map[String, String], schema: StructType): BaseRelation = {
- val path = parameters.get("path")
- path match {
- case Some(p) => new CustomDatasourceRelation(sqlContext, p, schema)
- case _ => throw new IllegalArgumentException("Path is required for custom-datasource format!!")
- }
- }
-
- override def createRelation(sqlContext: SQLContext, mode: SaveMode, parameters: Map[String, String],
- data: DataFrame): BaseRelation = {
- val path = parameters.getOrElse("path", "./output/") //can throw an exception/error, it's just for this tutorial
- val fsPath = new Path(path)
- val fs = fsPath.getFileSystem(sqlContext.sparkContext.hadoopConfiguration)
-
- mode match {
- case SaveMode.Append => sys.error("Append mode is not supported by " + this.getClass.getCanonicalName); sys.exit(1)
- case SaveMode.Overwrite => fs.delete(fsPath, true)
- case SaveMode.ErrorIfExists => sys.error("Given path: " + path + " already exists!!"); sys.exit(1)
- case SaveMode.Ignore => sys.exit()
- }
-
- val formatName = parameters.getOrElse("format", "customFormat")
- formatName match {
- case "customFormat" => saveAsCustomFormat(data, path, mode)
- case "json" => saveAsJson(data, path, mode)
- case _ => throw new IllegalArgumentException(formatName + " is not supported!!!")
- }
- createRelation(sqlContext, parameters, data.schema)
- }
-
- private def saveAsJson(data : DataFrame, path : String, mode: SaveMode): Unit = {
- /**
- * Here, I am using the dataframe's Api for storing it as json.
- * you can have your own apis and ways for saving!!
- */
- data.write.mode(mode).json(path)
- }
-
- private def saveAsCustomFormat(data : DataFrame, path : String, mode: SaveMode): Unit = {
- /**
- * Here, I am going to save this as simple text file which has values separated by "|".
- * But you can have your own way to store without any restriction.
- */
- val customFormatRDD = data.rdd.map(row => {
- row.toSeq.map(value => value.toString).mkString("|")
- })
- customFormatRDD.saveAsTextFile(path)
- }
- }
然后定义Schema以及读取数据代码。
- package cn.zj.spark.sql.datasource
-
- import org.apache.spark.rdd.RDD
- import org.apache.spark.sql.{Row, SQLContext}
- import org.apache.spark.sql.sources._
- import org.apache.spark.sql.types._
-
-
- /**
- * Created by rana on 29/9/16.
- */
- class CustomDatasourceRelation(override val sqlContext : SQLContext, path : String, userSchema : StructType)
- extends BaseRelation with TableScan with PrunedScan with PrunedFilteredScan with Serializable {
-
- override def schema: StructType = {
- if (userSchema != null) {
- userSchema
- } else {
- StructType(
- StructField("id", IntegerType, false) ::
- StructField("name", StringType, true) ::
- StructField("gender", StringType, true) ::
- StructField("salary", LongType, true) ::
- StructField("expenses", LongType, true) :: Nil
- )
- }
- }
-
- override def buildScan(): RDD[Row] = {
- println("TableScan: buildScan called...")
-
- val schemaFields = schema.fields
- // Reading the file's content
- val rdd = sqlContext.sparkContext.wholeTextFiles(path).map(f => f._2)
-
- val rows = rdd.map(fileContent => {
- val lines = fileContent.split("\n")
- val data = lines.map(line => line.split(",").map(word => word.trim).toSeq)
- val tmp = data.map(words => words.zipWithIndex.map{
- case (value, index) =>
- val colName = schemaFields(index).name
- Util.castTo(if (colName.equalsIgnoreCase("gender")) {if(value.toInt == 1) "Male" else "Female"} else value,
- schemaFields(index).dataType)
- })
-
- tmp.map(s => Row.fromSeq(s))
- })
-
- rows.flatMap(e => e)
- }
-
- override def buildScan(requiredColumns: Array[String]): RDD[Row] = {
- println("PrunedScan: buildScan called...")
-
- val schemaFields = schema.fields
- // Reading the file's content
- val rdd = sqlContext.sparkContext.wholeTextFiles(path).map(f => f._2)
-
- val rows = rdd.map(fileContent => {
- val lines = fileContent.split("\n")
- val data = lines.map(line => line.split(",").map(word => word.trim).toSeq)
- val tmp = data.map(words => words.zipWithIndex.map{
- case (value, index) =>
- val colName = schemaFields(index).name
- val castedValue = Util.castTo(if (colName.equalsIgnoreCase("gender")) {if(value.toInt == 1) "Male" else "Female"} else value,
- schemaFields(index).dataType)
- if (requiredColumns.contains(colName)) Some(castedValue) else None
- })
-
- tmp.map(s => Row.fromSeq(s.filter(_.isDefined).map(value => value.get)))
- })
-
- rows.flatMap(e => e)
- }
-
- override def buildScan(requiredColumns: Array[String], filters: Array[Filter]): RDD[Row] = {
- println("PrunedFilterScan: buildScan called...")
-
- println("Filters: ")
- filters.foreach(f => println(f.toString))
-
- var customFilters: Map[String, List[CustomFilter]] = Map[String, List[CustomFilter]]()
- filters.foreach( f => f match {
- case EqualTo(attr, value) =>
- println("EqualTo filter is used!!" + "Attribute: " + attr + " Value: " + value)
-
- /**
- * as we are implementing only one filter for now, you can think that this below line doesn't mak emuch sense
- * because any attribute can be equal to one value at a time. so what's the purpose of storing the same filter
- * again if there are.
- * but it will be useful when we have more than one filter on the same attribute. Take the below condition
- * for example:
- * attr > 5 && attr < 10
- * so for such cases, it's better to keep a list.
- * you can add some more filters in this code and try them. Here, we are implementing only equalTo filter
- * for understanding of this concept.
- */
- customFilters = customFilters ++ Map(attr -> {
- customFilters.getOrElse(attr, List[CustomFilter]()) :+ new CustomFilter(attr, value, "equalTo")
- })
- case _ => println("filter: " + f.toString + " is not implemented by us!!")
- })
-
- val schemaFields = schema.fields
- // Reading the file's content
- val rdd = sqlContext.sparkContext.wholeTextFiles(path).map(f => f._2)
-
- val rows = rdd.map(file => {
- val lines = file.split("\n")
- val data = lines.map(line => line.split(",").map(word => word.trim).toSeq)
-
- val filteredData = data.map(s => if (customFilters.nonEmpty) {
- var includeInResultSet = true
- s.zipWithIndex.foreach {
- case (value, index) =>
- val attr = schemaFields(index).name
- val filtersList = customFilters.getOrElse(attr, List())
- if (filtersList.nonEmpty) {
- if (CustomFilter.applyFilters(filtersList, value, schema)) {
- } else {
- includeInResultSet = false
- }
- }
- }
- if (includeInResultSet) s else Seq()
- } else s)
-
- val tmp = filteredData.filter(_.nonEmpty).map(s => s.zipWithIndex.map {
- case (value, index) =>
- val colName = schemaFields(index).name
- val castedValue = Util.castTo(if (colName.equalsIgnoreCase("gender")) {
- if (value.toInt == 1) "Male" else "Female"
- } else value,
- schemaFields(index).dataType)
- if (requiredColumns.contains(colName)) Some(castedValue) else None
- })
-
- tmp.map(s => Row.fromSeq(s.filter(_.isDefined).map(value => value.get)))
- })
-
- rows.flatMap(e => e)
- }
- }
类型转换类
- package cn.zj.spark.sql.datasource
-
- import org.apache.spark.sql.types.{DataType, IntegerType, LongType, StringType}
-
- /**
- * Created by rana on 30/9/16.
- */
- object Util {
- def castTo(value : String, dataType : DataType) = {
- dataType match {
- case _ : IntegerType => value.toInt
- case _ : LongType => value.toLong
- case _ : StringType => value
- }
- }
- }
1.3 依赖的pom文件配置
- <properties>
- <maven.compiler.source>1.8</maven.compiler.source>
- <maven.compiler.target>1.8</maven.compiler.target>
- <scala.version>2.11.8</scala.version>
- <spark.version>2.2.0</spark.version>
- <!--<hadoop.version>2.6.0-cdh5.7.0</hadoop.version>-->
- <!--<hbase.version>1.2.0-cdh5.7.0</hbase.version>-->
- <encoding>UTF-8</encoding>
- </properties>
-
-
- <dependencies>
- <!-- 导入spark的依赖 -->
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-core_2.11</artifactId>
- <version>${spark.version}</version>
- </dependency>
- <!-- 导入spark的依赖 -->
- <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-sql_2.11</artifactId>
- <version>2.2.0</version>
- </dependency>
-
- </dependencies>
1.4 测试代码以及测试文件数据
- package cn.zj.spark.sql.datasource
-
- import org.apache.spark.SparkConf
- import org.apache.spark.sql.SparkSession
-
- /**
- * Created by rana on 29/9/16.
- */
- object app extends App {
- println("Application started...")
-
- val conf = new SparkConf().setAppName("spark-custom-datasource")
- val spark = SparkSession.builder().config(conf).master("local").getOrCreate()
-
- val df = spark.sqlContext.read.format("cn.zj.spark.sql.datasource").load("1229practice/data/")
-
-
- df.createOrReplaceTempView("test")
- spark.sql("select * from test where salary = 50000").show()
-
- println("Application Ended...")
- 10002, Alice Heady, 0, 20000, 8000
- 10003, Jenny Brown, 0, 30000, 120000
- 10004, Bob Hayden, 1, 40000, 16000
- 10005, Cindy Heady, 0, 50000, 20000
- 10006, Doug Brown, 1, 60000, 24000
- 10007, Carolina Hayden, 0, 70000, 280000
2. 基本架构
Geomesa在Spark SQL的基础上,利用其注册优化器的机制,将自己已有的基本功能作为外部数据源,注册进Spark SQL的Session当中。而其中主要实现位于GeomesaSparkSQL类当中,基本流程如下:
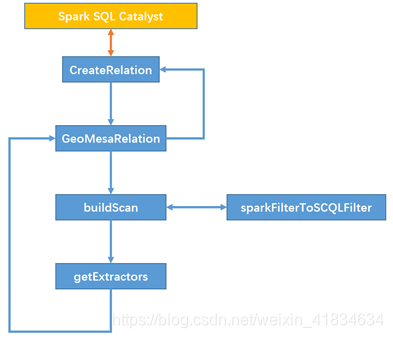
3. 各部分的功能及其主要参数
| 名称 | 功能 | 参数名 | 数据 |
|---|---|---|---|
| createRelation | 创建一个Relation对象,传给Spark SQL,作为Relation层 | parameter | Geomesa.feature(sftName) |
| Hbase.zookeepers(zk集群的ip和host) | |||
| Hbase.catalog(catalogName) | |||
| Schema | 表中全量的字段(未作投影) | ||
| GeomesaRelation | 构建Relation对象的内部信息 | 同上 | 同上 |
| buildScan | 构建查询数据的结构 | requiredColumns | 需要进行投影的字段,或者说此处真正需要返回给上层的字段 |
| Filters | Spark SQL原生的过滤条件对象 | ||
| filts | Opengis的过滤条件对象 | ||
| getExtracutors | 进行最终的投影 | RequiredColumns | 同上 |
| Schema | 全量的字段 | ||
| SparkFilterToCQLFilter | 将Spark的过滤条件对象转化为CQL的过滤条件对象 | Filters | Spark SQL原生的过滤条件对象 |
4. 源码分析
4.1 createRelation
在这个方法当中,需要通过DataStoreFinder来获取相应的geomesa datastore,例如HBaseDataStore。局部变量有两个,前面的sqlContext是Spark sql自身的上下文对象,parameters里面则封装了geomesa相关的配置参数,例如geomesa hbase所需要的catalog、sftname以及zookeeper的host和post。
- override def createRelation(sqlContext: SQLContext, parameters: Map[String, String]): BaseRelation = {
- SQLTypes.init(sqlContext)
-
- // TODO: Need different ways to retrieve sft
- // GEOMESA-1643 Add method to lookup SFT to RDD Provider
- // Below the details of the Converter RDD Provider and Providers which are backed by GT DSes are leaking through
- val ds = DataStoreFinder.getDataStore(parameters)
- val sft = if (ds != null) {
- try { ds.getSchema(parameters(GEOMESA_SQL_FEATURE)) } finally {
- ds.dispose()
- }
- } else {
- if (parameters.contains(GEOMESA_SQL_FEATURE) && parameters.contains("geomesa.sft")) {
- SimpleFeatureTypes.createType(parameters(GEOMESA_SQL_FEATURE), parameters("geomesa.sft"))
- } else {
- SftArgResolver.getArg(SftArgs(parameters(GEOMESA_SQL_FEATURE), parameters(GEOMESA_SQL_FEATURE))) match {
- case Right(s) => s
- case Left(e) => throw new IllegalArgumentException("Could not resolve simple feature type", e)
- }
- }
- }
- logger.trace(s"Creating GeoMesa Relation with sft : $sft")
-
- val schema = sft2StructType(sft)
- GeoMesaRelation(sqlContext, sft, schema, parameters)
- }
首先第一行中的SQLTypes.init方法引入了很多geomesa自己实现的类以及udf。接着就是对于datastore的初始化,此处程序对于传入的参数进行了判断,如果没有获取到ds,就会根据别的参数来获取对应的sft。最后就是构建全体变量的schema以及创建GeomesaRelation。
4.2 GeomesaRelation
在这个内部类当中,传入了很多查询参数,其中比较重要的为filt参数,这个参数是经过上层优化以后下推到此的opengis的Filter对象,初始化为INClUDE,即为无查询条件的全量搜索。
- case class GeoMesaRelation(sqlContext: SQLContext,
- sft: SimpleFeatureType,
- schema: StructType,
- params: Map[String, String],
- filt: org.opengis.filter.Filter = org.opengis.filter.Filter.INCLUDE,
- props: Option[Seq[String]] = None,
- var partitionHints : Seq[Int] = null,
- var indexRDD: RDD[GeoCQEngineDataStore] = null,
- var partitionedRDD: RDD[(Int, Iterable[SimpleFeature])] = null,
- var indexPartRDD: RDD[(Int, GeoCQEngineDataStore)] = null)
- extends BaseRelation with PrunedFilteredScan {
-
- val cache: Boolean = Try(params("cache").toBoolean).getOrElse(false)
- val indexId: Boolean = Try(params("indexId").toBoolean).getOrElse(false)
- val indexGeom: Boolean = Try(params("indexGeom").toBoolean).getOrElse(false)
- val numPartitions: Int = Try(params("partitions").toInt).getOrElse(sqlContext.sparkContext.defaultParallelism)
- val spatiallyPartition: Boolean = Try(params("spatial").toBoolean).getOrElse(false)
- val partitionStrategy: String = Try(params("strategy").toString).getOrElse("EQUAL")
- var partitionEnvelopes: List[Envelope] = null
- val providedBounds: String = Try(params("bounds").toString).getOrElse(null)
- val coverPartition: Boolean = Try(params("cover").toBoolean).getOrElse(false)
- // Control partitioning strategies that require a sample of the data
- val sampleSize: Int = Try(params("sampleSize").toInt).getOrElse(100)
- val thresholdMultiplier: Double = Try(params("threshold").toDouble).getOrElse(0.3)
-
- val initialQuery: String = Try(params("query").toString).getOrElse("INCLUDE")
- val geometryOrdinal: Int = sft.indexOf(sft.getGeometryDescriptor.getLocalName)
除此以外,在初始化这个类时,将存在于params当中的参数进行了抽取。例如是否有缓存,索引下标,是否进行空间分片以及分片策略等等。其中比较重要的是geometryOrdinal参数,现阶段geomesa spark sql是不支持没有空间字段的表的查询的,在查询过程当中会报错: Counld not Found SpatialRDDProvider,就是由于此处的geometryOrdinal参数为null。
4.3 buildScan
这个方法是GeomesaRelation类当中构建查询的方法。此时可以看到,spark sql已经将需要的列下推至此,还有geomesa spark sql的过滤条件以及opengis的过滤条件。在这个方法当中,首先将Spark SQL的原生过滤器转化成了CQL的过滤器,并将二者利用and拼接在一起。
接着将需要的列信息当中的__fid__字段去掉。然后调用GeoMesaSpark rdd来进行查询,最后将查询结果当中对应列的信息抽取出来,返回给上层的Spark SQL优化器。
- def buildScan(requiredColumns: Array[String],
- filters: Array[org.apache.spark.sql.sources.Filter],
- filt: org.opengis.filter.Filter,
- ctx: SparkContext,
- schema: StructType,
- params: Map[String, String]): RDD[Row] = {
- logger.debug(
- s"""Building scan, filt = $filt,
- |filters = ${filters.mkString(",")},
- |requiredColumns = ${requiredColumns.mkString(",")}""".stripMargin)
- val compiledCQL = filters.flatMap(SparkUtils.sparkFilterToCQLFilter).foldLeft[org.opengis.filter.Filter](filt) { (l, r) => ff.and(l, r) }
- val requiredAttributes = requiredColumns.filterNot(_ == "__fid__")
- val rdd = GeoMesaSpark(params).rdd(
- new Configuration(ctx.hadoopConfiguration), ctx, params,
- new Query(params(GEOMESA_SQL_FEATURE), compiledCQL, requiredAttributes))
-
- val extractors = SparkUtils.getExtractors(requiredColumns, schema)
- val result = rdd.map(SparkUtils.sf2row(schema, _, extractors))
- result.asInstanceOf[RDD[Row]]
- }
4.4 getExtractor
这个类用来将查询到的SimpleFeature对象根据投影的列信息来进行提取。在此处可以看到一个隐患,就是当程序对requiredColumns进行map操作时,程序根据col的索引来对数据进行提取,从数据结构上来说,这样的查询方式的时间复杂度为O(0),相对来说效率比较高,但是由于有__fid__字段的存在,在一些情况下可能会出现类型不匹配的问题。
- def getExtractors(requiredColumns: Array[String], schema: StructType): Array[SimpleFeature => AnyRef] = {
- val requiredAttributes = requiredColumns.filterNot(_ == "__fid__")
-
- type EXTRACTOR = SimpleFeature => AnyRef
- val IdExtractor: SimpleFeature => AnyRef = sf => sf.getID
-
- requiredColumns.map {
- case "__fid__" => IdExtractor
- case col =>
- val index = requiredAttributes.indexOf(col)
- val schemaIndex = schema.fieldIndex(col)
- val fieldType = schema.fields(schemaIndex).dataType
- if (fieldType == TimestampType) {
- sf: SimpleFeature => {
- val attr = sf.getAttribute(index)
- if (attr == null) { null } else {
- new Timestamp(attr.asInstanceOf[Date].getTime)
- }
- }
- } else {
- sf: SimpleFeature => sf.getAttribute(index)
- }
- }
- }
4.5 sparkFilterToCQLFilter
最后这个sparkFilterToCQLFilter方法是将spark sql自生的Filter转化为opengis的Filter的一个工具。
- def sparkFilterToCQLFilter(filt: org.apache.spark.sql.sources.Filter): Option[org.opengis.filter.Filter] = filt match {
- case GreaterThanOrEqual(attribute, v) => Some(ff.greaterOrEqual(ff.property(attribute), ff.literal(v)))
- case GreaterThan(attr, v) => Some(ff.greater(ff.property(attr), ff.literal(v)))
- case LessThanOrEqual(attr, v) => Some(ff.lessOrEqual(ff.property(attr), ff.literal(v)))
- case LessThan(attr, v) => Some(ff.less(ff.property(attr), ff.literal(v)))
- case EqualTo(attr, v) if attr == "__fid__" => Some(ff.id(ff.featureId(v.toString)))
- case EqualTo(attr, v) => Some(ff.equals(ff.property(attr), ff.literal(v)))
- case In(attr, values) if attr == "__fid__" => Some(ff.id(values.map(v => ff.featureId(v.toString)).toSet))
- case In(attr, values) =>
- Some(values.map(v => ff.equals(ff.property(attr), ff.literal(v))).reduce[org.opengis.filter.Filter]( (l,r) => ff.or(l,r)))
- case And(left, right) => Some(ff.and(sparkFilterToCQLFilter(left).get, sparkFilterToCQLFilter(right).get)) // TODO: can these be null
- case Or(left, right) => Some(ff.or(sparkFilterToCQLFilter(left).get, sparkFilterToCQLFilter(right).get))
- case Not(f) => Some(ff.not(sparkFilterToCQLFilter(f).get))
- case StringStartsWith(a, v) => Some(ff.like(ff.property(a), s"$v%"))
- case StringEndsWith(a, v) => Some(ff.like(ff.property(a), s"%$v"))
- case StringContains(a, v) => Some(ff.like(ff.property(a), s"%$v%"))
- case IsNull(attr) => None
- case IsNotNull(attr) => None
- }






