在我们完成联邦建模任务并且成功将最终训练好的模型存储在相应的存储模块后,发起方A端就可以发起推理任务,在与B端的配合下展开预测,根据双方的特征值,得到预测结果,而这个结果正是我们联合建模的最终目的。与训练不同,由于具有实时调用场景,往往对推理服务的性能有很高的要求,并且要求推理服务能在不影响线上实时调用的基础上,实现无感知的服务升级。企业间的推理预测,往往涉及对账问题,于是对端监控变得极为重要,这能保证在推理完成后,合作方之间能够根据监控信息做到有帐可查,并能排查推理失败等异常情况。通信服务:端与端之间需要通信,所以我们需要一个代理,对外暴露gRPC接口跟HTTP接口,路由的转发以及外部系统的所有请求都委托给这一个代理,同时也可以根据业务的特点,决定负载均衡的方式,比如在接入代理之前部署Nginx来实现反向代理。推理服务:当一个新的推理请求过来时,它可以将所有推理相关的接口注册到如ZooKeeper的注册中心,外部系统可以通过服务发现获取接口地址加以调用;从远程存储系统中存储模型到本地,根据请求信息从本地存储系统中选择模型并加载模型;匹配到需要参与预测的用户信息,开展预测任务。模型管理服务:完成模型持久化存储,分组等,保存训练好的模型信息。
注册中心:为了保证服务的高可用,引入如ZooKeeper的注册服务,当服务启动的时候,会将服务信息注册,当向网关服务发起推理请求的时候,网关服务会从注册服务中拉取到可用的服务,通过指定的负载均衡策略完成服务调用。存储服务:我们还需要将每次预测的结果存储起来以满足一些业务的需求,同时也需要将模型存储起来,持久化模型到本地可以保证在推理中某些组件发生问题时快速恢复过来,以及不需要每次发起推理请求时都从分布式存储系统中加载模型,从而保证安全也提高了效率。在此基础上,整个推理的流程大致可以分为以下几个步骤: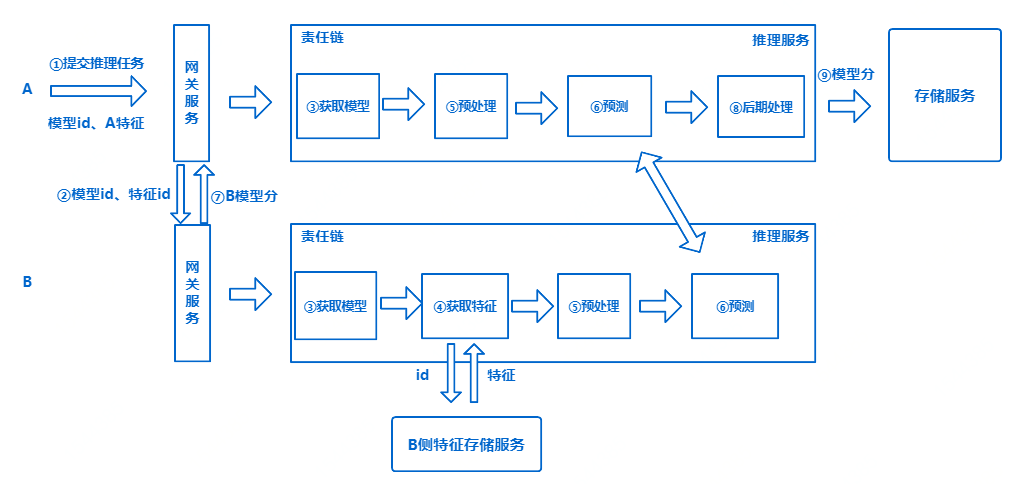
提交训练任务:当我们向网关服务提交一个推理任务之后,网关服务会将请求路由到推理服务。
获取模型:如果是第一次加载该模型,则会将其从分布式存储系统持久化到本地的存储系统系统中,如果已经被加载过,则直接从本地存储系统中读取。预处理&预测:在A,B都加载完模型后,B端根据Featureid从本侧外部系统中获取相应的特征信息,双方都需要对本地特征进行预处理,然后开始预测,并将结果通过通信服务传给A端。后期处理:A端将B端的结果进行整合,在本地进行规则映射等后期处理,并将最终的结果保存。综上所述,整个推理流程都比较简单,但是当我们以工程的角度去看的时候是远远不够的,不管考虑到系统的耦合性还是稳定性,例如,当业务需求是要将整个推理从联邦系统中抽出来单独部署的时候,当我们要查询不同模型不同版本预测的历史结果的时候,又或者需要满足高可用进行集群部署的时候等等。因此为了应对复杂的业务需求,对系统的各个组件,我们亦需在灵活与便捷之间寻找一个平衡点。由于在实际生产中有着复杂的业务需求以及不可预测的问题,因此需要我们根据实际情况完善架构,例如添加相应的服务治理功能,以及线程池的规划等等。了解更多数科技术最佳实践&创新成果,请关注“京东数科技术说”微信公众号 
















