



★ 赛题介绍 ★
AliExpress是阿里巴巴海外购物网站,其网站的海外用户可以在AliExpress挑选购买自己心意的商品。对于AliExpress来说,目前某些国家A的用户群体比较成熟,沉淀了大量的该国用户的行为数据。但是还有一些待成熟国家B的用户在AliExpress上的行为比较稀疏。
对于这些国家B用户的推荐算法如果单纯不加区分的使用全网用户的行为数据,可能会忽略这些国家用户的一些独特的用户特点。而如果只使用国家B的用户的行为数据,由于数据过于稀疏,不具备统计意义,会难以训练出正确的模型。
赛题难点是:怎样利用已成熟国家A的稠密用户数据和待成熟国家B的稀疏用户数据,训练出的正确模型对于国家B的用户有很大价值。
赛题数据给出若干日内来自成熟国家的部分用户的行为数据,以及来自待成熟国家的A部分用户的行为数据,以及待成熟国家的B部分用户的行为数据去除每个用户的最后一条购买数据,让参赛人预测B部分用户的最后一条行为数据。
赛题评价指标:赛题旨在通过海量数据挖掘用户下一个可能交互商品,选手们可以提交预测的TOP30商品列表,排序越靠前命中得分越高。
赛题具体使用MRR(Mean Reciprocal Rank)对选手提交的表格中的每个用户计算用户得分:
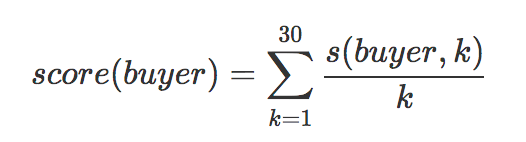
其中, 如果选手对该buyer的预测结果predict k命中该buyer的最后一条购买数据则s(buyer,k)=1 s(buyer,k)=1; 否则s(buyer,k)=0 s(buyer,k)=0. 而选手得分为所有这些score(buyer)的平均值。
★ 赛题数据 ★
初赛数据
● 商品属性表
数据中涉及2840536个商品,对于其中大部分商品,都会给出该商品的类目id、店铺id以及加密价格,其中价格的加密函数f(x)为一个单调增函数。
● 训练数据
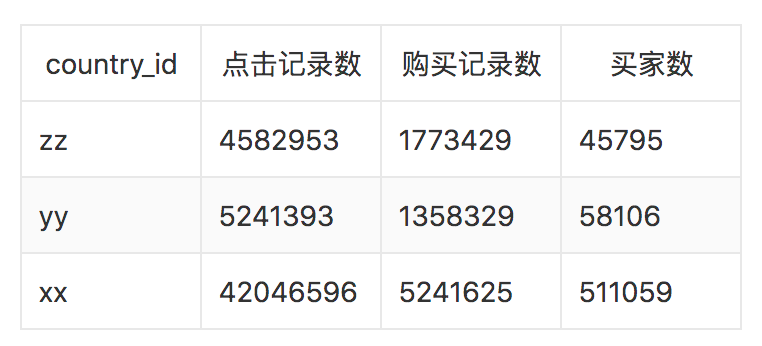
给出xx国的用户的购买数据和yy国的部分用户的购买数据。
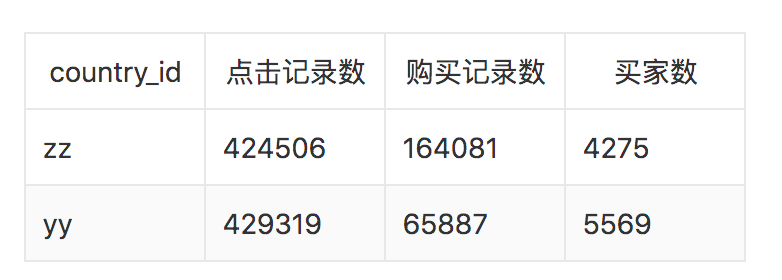
● 测试数据
给出yy国的B部分用户的购买数据除掉最后一条。数据的整体统计信息如下:
商品属性表、训练数据、测试数据对应的文件:item_attr, train和test。无论是训练数据还是测试数据,都具有如下的格式:

其中各字段含义如下:
1. buyer_country_id: 买家国家id, 有'xx'和'yy'两种取值;
2. buyer_admin_id: 买家id;
3. item_id: 商品id;
4. create_order_time: 订单创建时间;
5. irank: 每个买家对应的所有记录按照时间顺序的逆排序;
初赛数据集特点:
1)每个用户有至少7条购买数据;
2)测试数据中每个用户的最后一条购买数据所对应的商品一定在训练数据中出现过;
3)少量用户在两个国家有购买记录,评测中忽略这部分记录;
复赛数据
在给出若干日内来自某成熟国家xx的部分用户的点击购买数据,以及来自某待成熟国家yy和待成熟国家zz的A部分用户的点击购买数据,以及国家yy和zz的B部分用户的截止最后一条购买数据之前的所有点击购买数据,让参赛人预测B部分用户的最后一条购买数据。
● 商品属性表
点击购买数据中涉及9136277个商品,对于其中大多数商品,我们都会给出该商品的类目id、店铺id以及加密价格,其中价格的加密函数f(x)为一个单调增函数。
● 训练数据
给出xx国的用户的点击、购买数据和yy国、zz国的A部分用户的点击、购买数据。
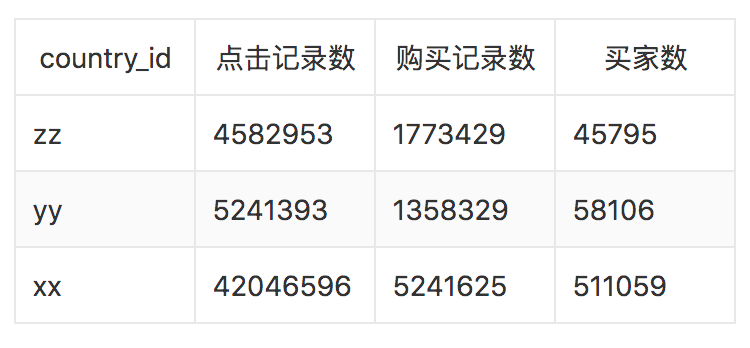
● 测试数据
给出yy国、zz国的B部分用户的最后一条购买数据之前的点击购买数据。
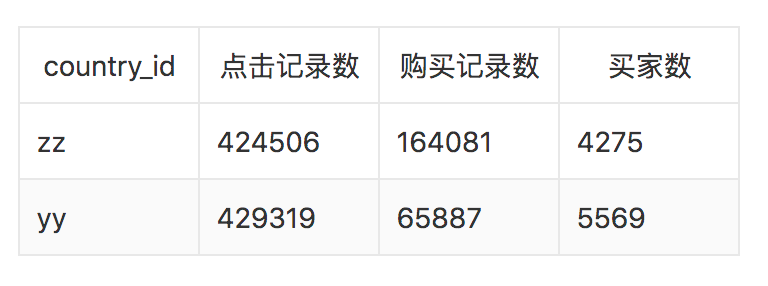
无论是训练数据还是测试数据,都具有如下的格式:

其中各字段含义如下:
1. buyer_country_id: 买家国家id, 只有'xx','yy','zz'三种取值2. buyer_admin_id: 买家id
3. item_id: 商品id
4. log_time: 商品详情页访问时间
5. irank: 每个买家对应的所有记录按照时间顺序的逆排序
6. buy_flag: 当日是否购买
复赛数据集特点:
1)每个用户有若干条点击数据和至少1条购买数据 (但测试数据中该条购买记录可能未给出到选手;
2)每个用户的最后一条数据的buy_flag一定为1 (但测试数据中该条数据未给出到选手;
3)测试数据中每个用户的最后一条点击数据(也是购买数据)所对应的商品一定在训练数据中出现过;
4)可能存在少量跨国买家.
★ 赛题分析 ★
赛题分析是深入理解赛题的最有效的方法,也是构建有效特征和模型的先驱条件。
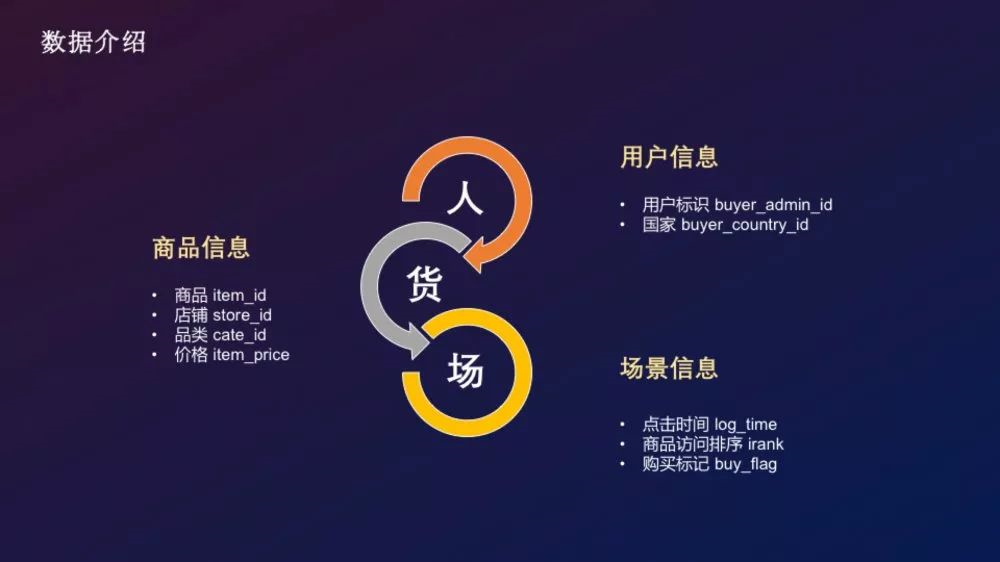
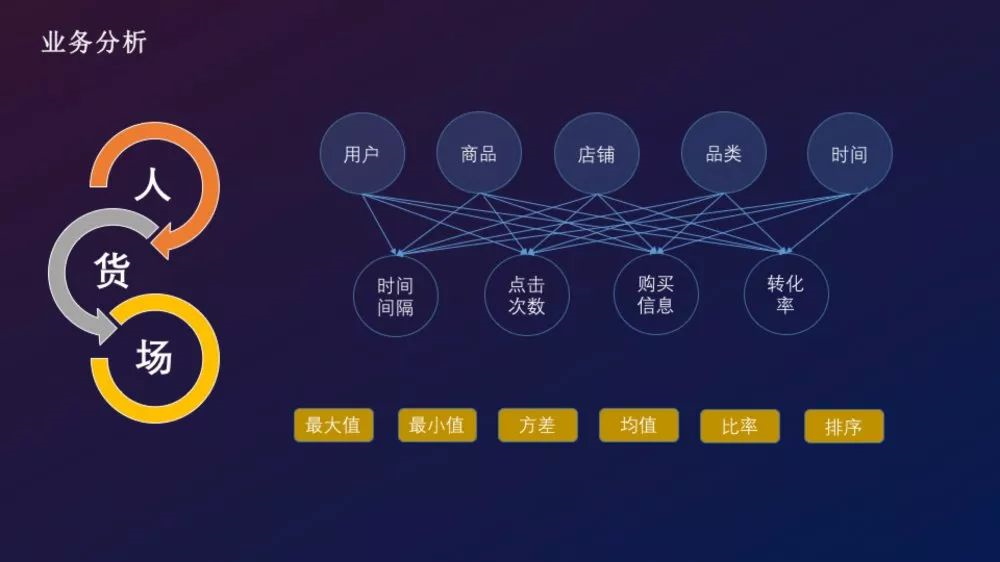
根据零售行业的人货场概念,赛题提供了关于用户行为日志的常见字段可分为如下部分:
- 用户:用户标识、用户国籍
- 商品:商品标识、店铺、品类、价格
- 场景:点击时间、访问排序、购买标记
通过对赛题数据进行探索和分析,我们发现可以根据预测商品是否在历史交互过分成两种不同分布的用户:
- 历史交互用户(68%):即预测商品用户曾经已交互过,在召回-排序阶段:
召回:可通过buy_flag=1,将交互商品全量召回
排序:基于用户商品交互信息,解决排序问题,预测精度高 - 冷启动用户(32%):即预测商品用户从未交互过,在召回-排序阶段:
召回:基于商品关联信息召回,召回难度大
排序:基于用户最近交互商品与关联信息进行排序,预测精度较低
方案思路:面对两种不同分布的用户,我们因地制宜基于不同样本和特征分别建立两个排序模型,然后再通过用户判断模型对两个排序的结果进行优化。
★ 特征工程 ★
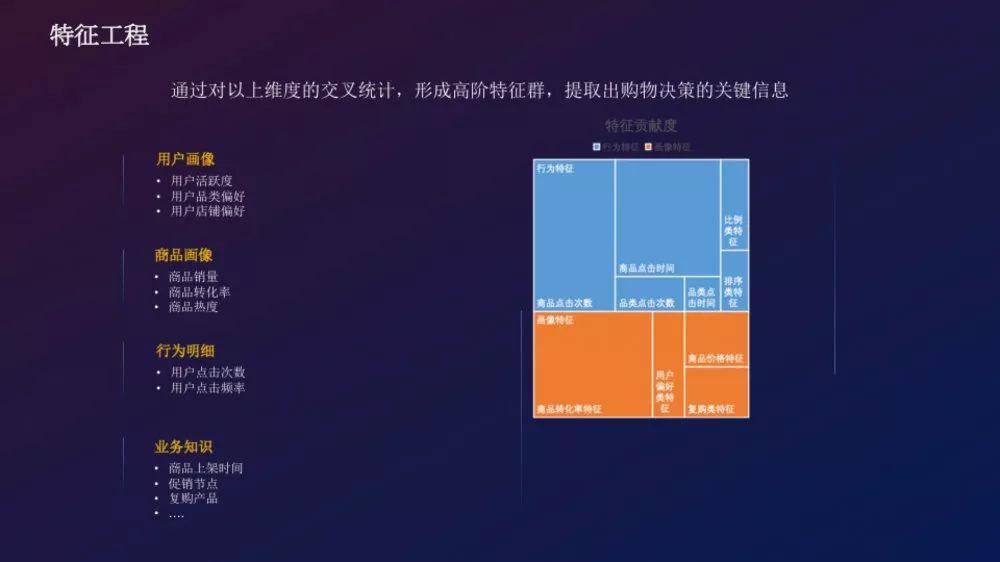
赛题所给的字段相对简单,主要可分为:用户-商品-场景,我们通过对不同类型因素进行交叉复合,并使用基础统计手段进行计算,构造出高阶特征,提取出购物决策的相关信息:
通过对以上维度的交叉统计,形成高阶特征群,提取出购物决策的关键信息,下图给出了所提取特征的贡献度:
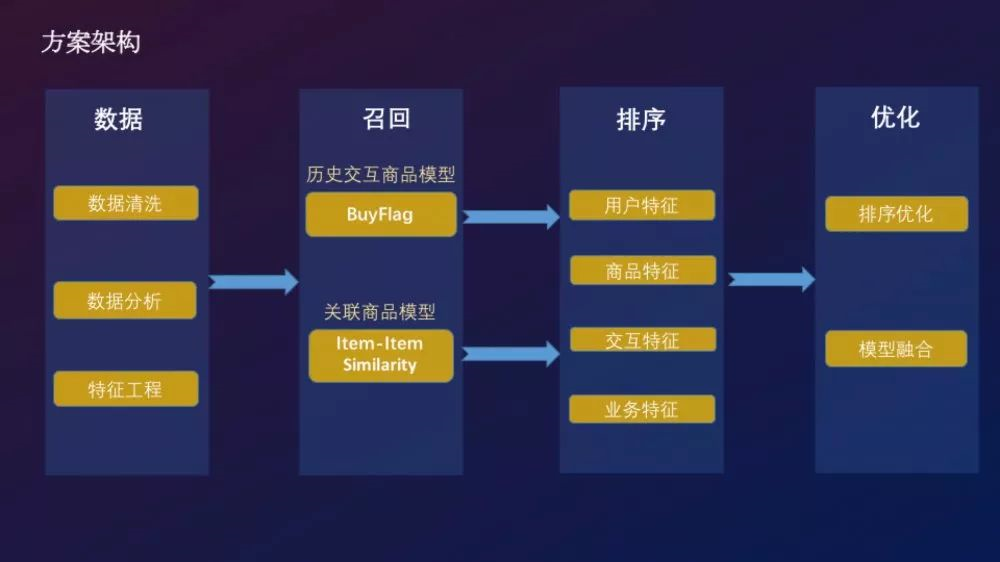
★ 构建模型 ★
根据上述的分析我们构建了两个模型:
- 历史交互商品模型
- 关联商品模型
历史交互商品模型
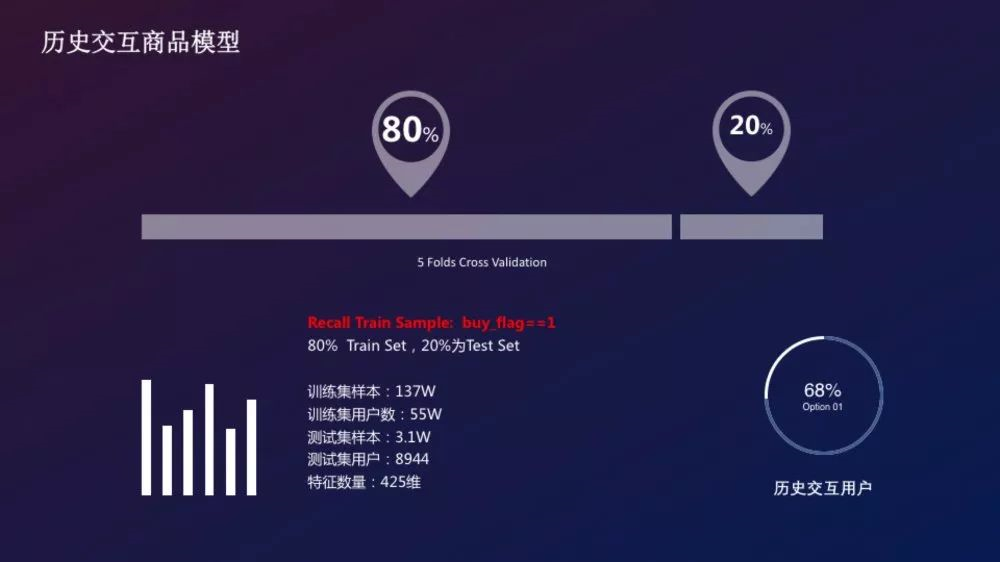
- 样本构造:提取buy_flag=1的user-item作为样本,用户最后交互的设为正样本,其他为负样本
- 模型信息:这里使用的LightGBM模型;
- 样本信息:
- 训练集样本数:137W
- 训练集用户数:55W
- 测试集样本数:3.1W
- 测试集用户数:8944
- 特征数量:425
- Model:LightGBM
- loss function:AUC
- 模型效果:
AUC: 0.9493
MRR: 0.8922 - Recall Rate 样本召回率:
- Top1 item:81%
- Top3 item:92.5%
- Top10 item:99%

这个时候线上达到0.6085的成绩,排名第五,当然目前仅是考虑到了历史有过交互的商品,接下来将建立关联商品模型。
关联商品模型
那么我们如何找到用户未来可能交互的商品?比较好的方法是挖掘关联商品,根据用户历史交互商品,找到这些商品的关联品。
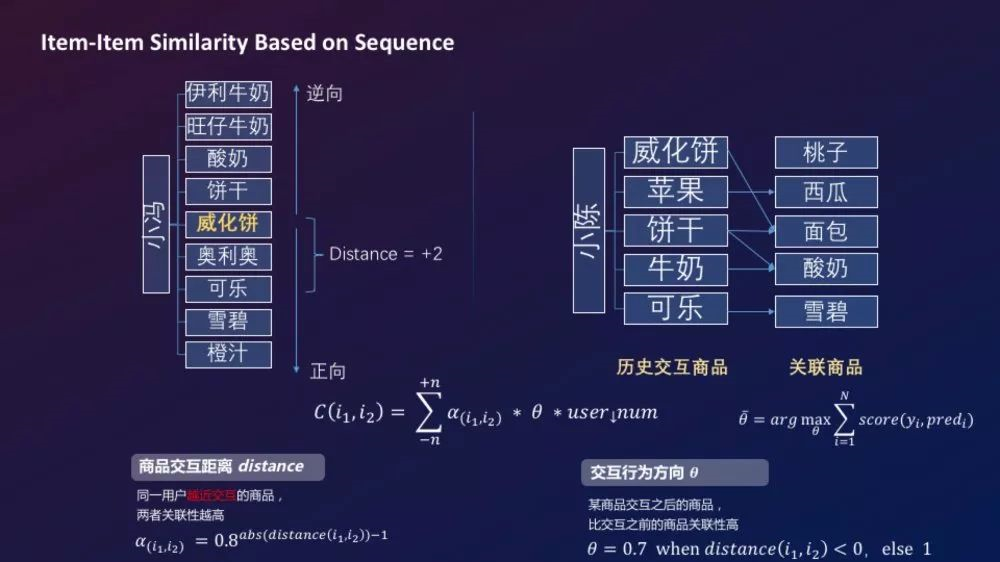
- Item-Item similarity Based on Sequnence
商品相似性:基于用户行为序列计算,假设用户越近交互的两个商品相似性越高,并且考虑先后次序,通过线性搜索得到如下相似度计算公式: - 样本构造:对用户最近5个交互商品的关联商品(加上时间衰减权重),选取每个用户TOP50关联商品,之前得到的关联度中间结果直接作为特征训练排序模型
- 模型信息:
- 训练集样本数:940W
- 训练集用户数:18W
- 测试集样本数:47W
- 测试集用户数:8944
- 特征数量:222
- Model:LightGBM
- loss function:AUC
- 模型效果:
AUC: 0.9736
MRR: 0.0554 - Rcall Rate:
- Top1 item:3.1%
- Top3 item:6.3%
- Top30 item:15%

经过关联商品模型来解决冷启动的问题,我们的成绩也由0.6085提高到0.6187,排名提升到第一。
★ 模型融合/优化 ★
排序优化
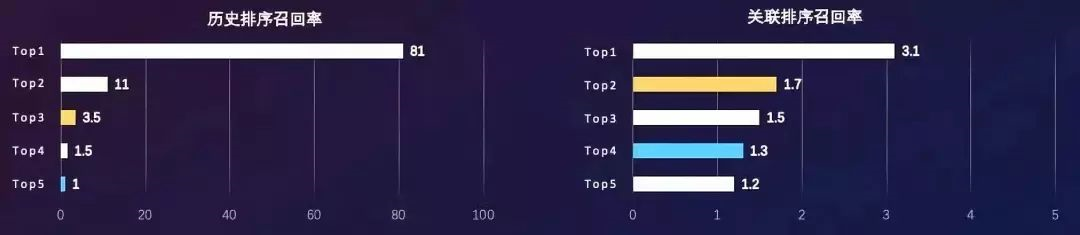
如图所示,历史商品模型排序第4的商品召回率仅有1.5,而关联模型排序第一位召回率为3.1。
为了优化排序结果,优化两部分模型的结果,通过用户判别模型(预测用户是否为冷启动用户),对概率大于0.95的高置信度用户直接截取掉历史TOP3后,与商品与关联模型的结果进行拼接,得到最终的Top30商品排序。

模型融合
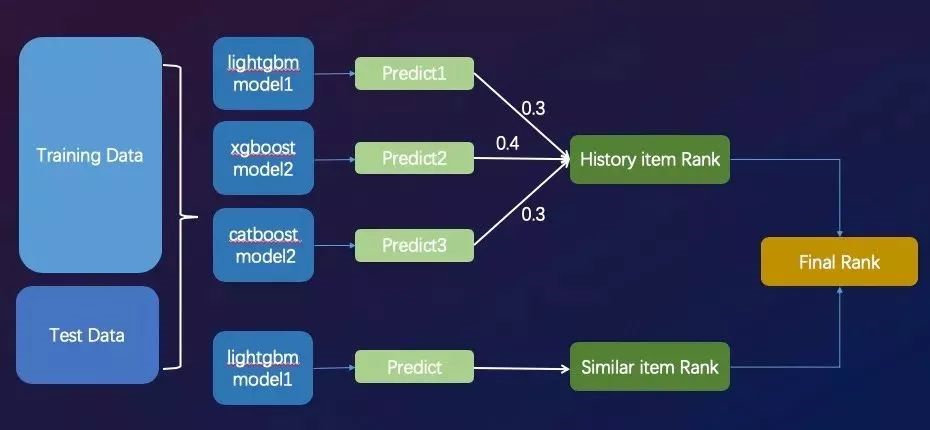
- Enseblem
对于历史交互商品模型,训练了LightGBM、Xgboost、CatBoost三个模型,通过对预测结果简单加权进行融合。
- Stacking
此外,在每个模型训练过程中通过简单Stacking将其他4折的预测结果作为特征反喂模型,进一步拟合结果。
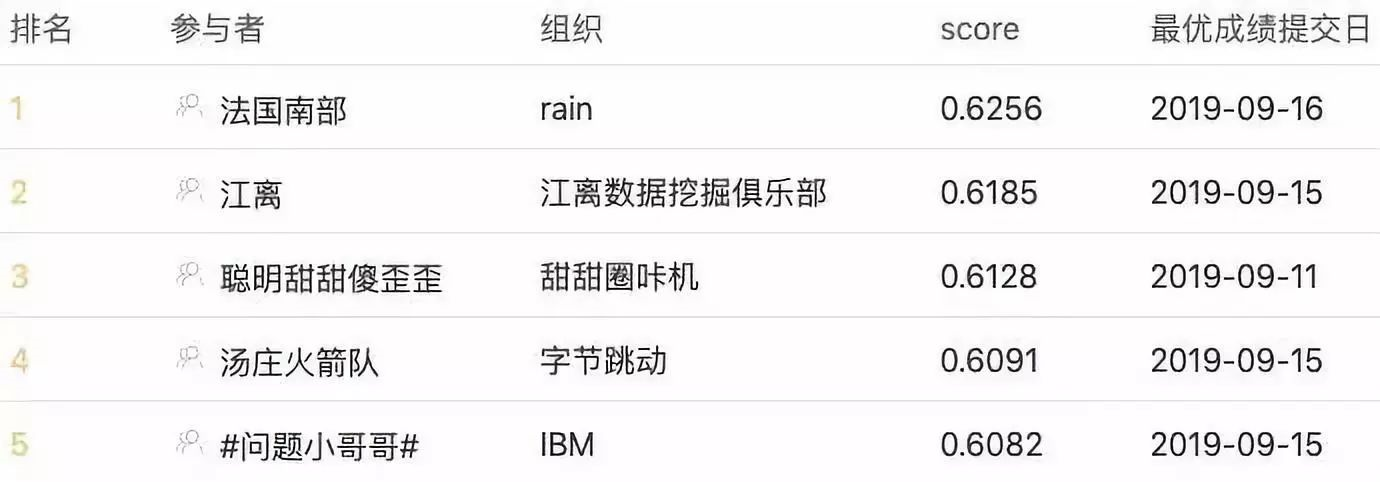
通过排序优化和stacking后,我们将分数从0.6198提升到0.6256,进一步拉开了与其他队伍的差距。
★ 比赛总结 ★
在本次比赛前期,我花费了大量精力进行数据探索和分析,基于对数据和业务的了解才确立了最终的方案和优化路线。当对数据之间的联系了然于心后,开始进行细致的特征工程以提取各种信息,在也是历史交互模型得分提升的关键。
此后,为了提高召回率,尝试了Embedding、协同过滤等方法,但是由于数据量和category字段少的限制,都没取得太好的效果,开始基于业务理解,尝试建立关联度计算公式,通过不断搜索参数,取得了不错的召回率,由此建立关联商品模型,此时成绩也上升到第一名。
最后阶段,我们开始提高模型的精度和稳定性,一是建立了用户判别模型对排序进行了优化,二是对模型进行了融合以及stacking,得到了0.6256分数,进一步扩大了领先优势。
取胜关键 = 充分理解业务 + 完备的特征工程 + 合理建模方法 + 细致结果优化 + 坚持就是胜利!





