



在刚刚过去的618大促中,京东视频抛弃了私有存储,将京东智联云对象存储作为京东视频的唯一存储。在整个618过程中,京东智联云对象存储提供了稳定的服务,助力618完美落幕。
618大促作为京东集团最重要的活动,对所有服务的可用性有极高的要求,京东视频作为京东的一级系统,对存储的故障更是零容忍,那么如何保障系统的高可用呢?下面我们就一起来探讨下京东智联云对象存储在高可用架构设计上的一些思考。

作为一个有状态的服务,影响服务可用性的因素有很多,一般来说会有以下几大类:
硬件/网络故障,该故障会导致部分数据无法读取或者写入,如果是中心节点故障甚至会导致整个服务无法使用;
误操作,人工的误操作可能会导致服务不可用甚至数据丢失/损坏,如果是对中心类的节点误操作可能导致整个服务无法使用;
程序Bug,存储系统也在不断更新迭代的过程中,每次更新迭代都可能会引入Bug,导致系统不可服务甚至数据丢失/损坏。
对象存储是一个复杂的系统,在设计和实现的过程中,我们遵循了以下原则,来保证对象存储的高可用:
所有数据都是三副本存储,数据跨越三个AZ,保证任何级别的硬件故障都不会导致服务不可用;
数据只读化,一个数据存储之后就不会再被修改,这也意味着只要数据在磁盘上,就不会影响到读,保证读的高可用;
使用多个集群共同组成一个服务,在多个集群上做写的高可用,确保写入不会中断;
蓝绿部署,灰度发布,确保任何操作都只会在一个集群上进行,避免了Bug/误操作等对写入的影响;
没有中心节点。
下面我们以对象存储的架构为例,详细探讨下在对象存储中,我们是如何实践以上原则的。

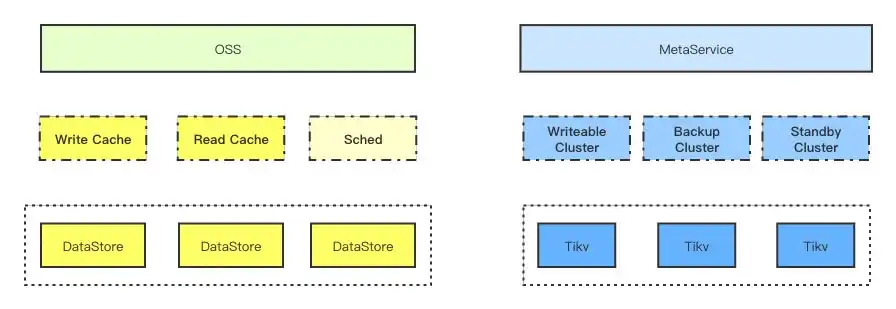
整体来说,对象存储包括业务层(绿色部分)、数据存储(黄色部分)、元数据存储(蓝色部分)三个部分组成,下面对这三个部分分别做更详细的介绍:

对象存储业务层主要做了一些认证鉴权限流等业务操作,从数据流的角度来看,他主要做了数据流的拆分和转发的工作,下图描述了一个基本的上传流程:
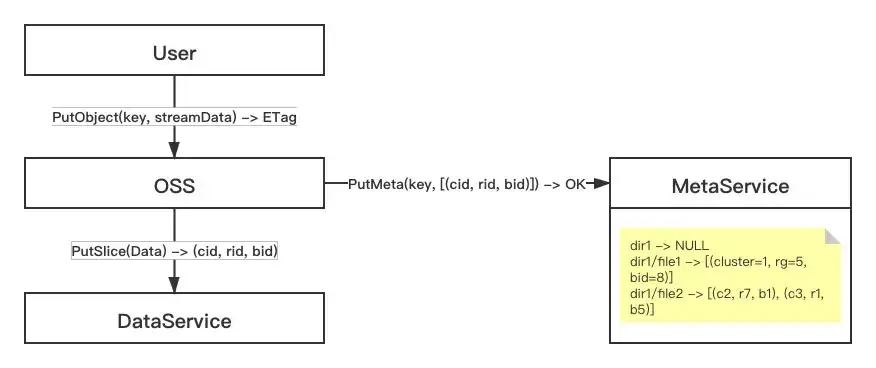
从上图中,我们可以看到,对象存储业务层上传的流程如下:
接收流式数据,拆分成一个个的Slice;
把每个Slice写入到后端数据存储,并且记录下数据存储返回的SliceId(clusterId, rgId, blobId);
把Key和所有SliceId存储在元数据存储中;
返回给客户成功。
从上面的描述可以看出,对象存储业务本身是一个无状态的服务,可以简单的通过多个节点来实现高可用,在现实中我们也是这么做的。

从上面的数据上传流程中可以看到,数据存储是一个Blob的系统,它的基本接口是用户写入一份数据,数据存储返回一个Id,这意味着可以实现以下两点:
写入到数据存储中的数据只会被读取和删除,永远不会被修改,也意味着任意时间只要从任何一个副本读到某个SliceId的数据,该数据一定是最新的数据;
任何一个Slice可以写入到任意一个集群的任意一个复制组,保证写入永远高可用;

首先,我们来看一下对象存储数据存储系统多集群部署多逻辑结构图:
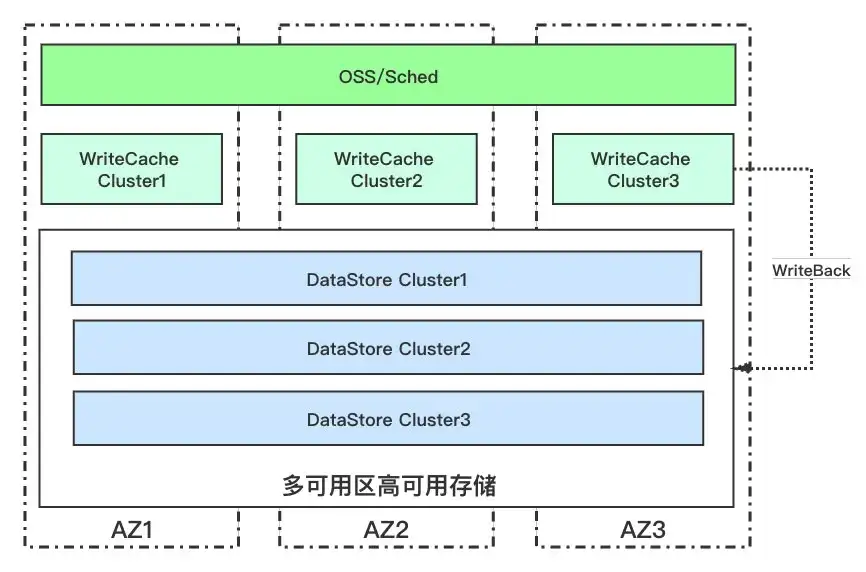
从上面的逻辑部署图可以看到,数据存储系统由两类存储系统组成,下面分别介绍一下:
集群类型
跨AZ部署
持久化
说明
DataStore
是
是
1. 标准存储/低频存储
2. 一般跨3AZ部署,多可用区高可用
3.读写都优先到本AZ
读写都优先到本AZ
否
是
1. 写缓存
2. 三副本,持久化存储
3. 单AZ部署,优先选择本AZ缓存集群
4. 数据会较为快速回写到DataStore

上图展示了一个Region标准的部署图,一般来说,一个Region由三个AZ组成,业务层会跨越三个AZ部署,存储集群、WriteCache和DataStore都会部署三个集群,做蓝绿部署,其中DataStore跨越三个AZ,而WriteCache每个AZ部署一套。

对象存储是一个Blob系统,数据写入到后端任意一个存储集群都可以,Sched负责调度一次写入写入到具体哪个集群。
流量调度会综合集群的容量/压力等信息,把请求调度到合适的集群,确保各个集群能最大化地被利用。

在对象存储数据存储中,每个区域会部署三套存储集群/缓存集群,这些集群做蓝绿部署,任何更新或者运维操作都只会在一个集群上进行,确保了任何的Bug或者人工误操作不会影响到对象存储的写入。
在部署上,对象存储数据存储除了部署跨越多个可用区的DataStore,还在每个AZ中部署了AZ内的WriteCache,确保了在跨AZ网络中断某个AZ形成了孤岛也不影响数据的写入。

在数据存储中,底层的数据存储有WriteCache,标准存储-DataStore,EC存储等多个系统,它们的基本架构都是一样的,都是基于ReplicateGroup/Raft/Log的系统,写入成功都只依赖于复制组中大部分节点响应成功。
下面我们来看看底层存储集群的架构:

和一个常见的分布式存储系统类似,对象存储底层存储集群也是由Client,DataNode,Master三个部分组成,下面分别对三个部分做一个介绍:
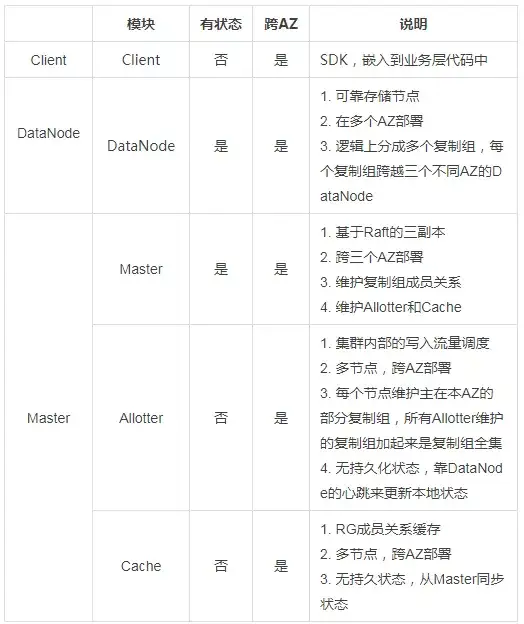
底层数据存储高可用的核心思路如下:
所有的数据/服务都是多副本的,并且跨越多个AZ,保证单磁盘/机器/交换机/机房故障都不会影响用户;
主干流程上不存在中心节点,常见的系统设计中,Master可能会是一个中心节点,少数几个Master故障可能导致整个集群不可用,在DataStore的设计中,我们把Master分成了多个系统,和主干流程相关的数据路由信息被拆分到Allotter中,并且多节点部署,Master本身不影响核心流程;
数据读取不依赖于复制组的存活,只要数据存在且能路由到就能访问;
数据不强制要求三副本,但是保证绝大部分数据都是三副本。
下面我们具体从读写的角度看看是如何实现高可用:

写入流程如下:
Client挑选一个可用的Allotter,从中分配一个可用RG;
Client访问Cache(有本地缓存),获取到该RG对应的Leader的地址;
Client向Leader发送写入请求;
Leader通过Raft把数据复制到所有副本,提交后响应客户端;
如果中间有任何失败,Client会重试1-5步骤。
读取的流程和写入基本类似,就不再重复说明。
数据写入路由依赖于Allotter和Cache,Allotter和Cache都是多节点有任意一个可用的节点就能提供服务,另外Client本身也能承担绝大部分Allotter/Cache的功能,保证写入路由高可用;
数据最终可以存储在任意一个RG中,一个集群中会有数十万到百万级别的RG,有任何一个可用的RG就可以成功地写入;
一个集群会包括数百台存储服务器,RG会随机地分散在这些服务器上,保证了只要有部分存储服务器可用,就一定会有可用的RG。

数据的路由会缓存在多个节点的Cache中以及Client内部,保证大量节点故障的时候仍然能找到数据的位置;
数据本身设计为不会被修改,因此数据的读取只依赖于数据所在节点进程的存储而不依赖于数据所在复制组的存活,只要能找到数据的位置(上一步描述了其高可用),就能读取到数据;
写入本身不是三副本强一致,但是Allotter在做写入流量调度时会优先选择主从复制delay少的复制组,保证了绝大部分数据实际上都是有三副本的;
进程快速启动,启动后能在数秒开始提供读服务;
每个复制组数据较少,磁盘故障理论上在20分钟以内能完成修复。
综上所述,数据不可访问的概率基本和数据丢失的概率一样低。

对象存储元数据管理系统核心是一个全局有序的KV系统,和数据存储相比,它会有以下几点不同:
数据会被覆盖,用户可以对一个Object做覆盖上传,该操作会修改元数据存储中该Key对应的Value;
数据量小,通常元数据存储大概只有数据千分之一以下。
对于元数据的的高可用,我们也采取了跨AZ多副本存储、多集群等机制,但是这些机制和数据存储又不完全一致,接下来我们来详细看看元数据的高可用方案:

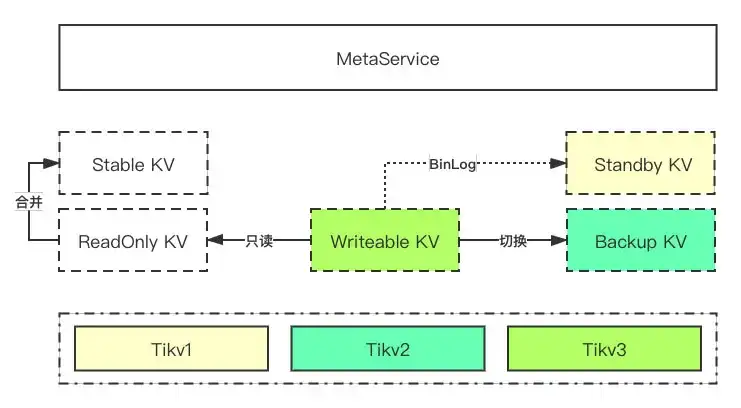
上图所示是对象存储元数据存储系统的核心架构,元数据存储系统底层使用了Tikv作为最终的存储系统,和数据存储一样,元数据存储在每个区域同样会部署三套跨越三个AZ的Tikv,多个Tikv集群之间做蓝绿部署,降低人为操作/升级引入Bug等因素对整个元数据存储系统等影响。
元数据管理系统采用了类似LSM Tree的架构,在多个集群上通过各种不同角色的组件构建了统一的元数据管理服务,各个组件的关系见下表描述:
组件
描述
Writeable KV
当前正在读写的集群,和LSM类似,删除在Writeable KV写入删标记
ReadOnly KV
只读集群,写入流量从Writeable切换到Backup之后,原来的Writeable就变成只读
Stable KV
每次写入流量切换会产生一个ReadOnly的KV,ReadOnly的KV过多会影响到读取和Scan的性能,在ReadOnly的KV到达一定数量后就会合并进Stable KV
Backup KV
Writeable集群的写备份,在Writeable KV对应的物理集群变成不可写入的时候,写入会切换到Backup,保证写入高可用
Standby KV
Writeable集群的读备份,Standby集群会通过类似Binlog的方式重做所有更新操作,保证Standby KV和Writeable KV的数据基本一致(有短暂延时),在Writeable集群不可读的时候会之间读Standby集群,Standby集群的数据会随着集群切换只读而丢弃

和数据高可用的思路类似,元数据高可用也是由两个部分组成:
存储集群做高可用;
多集群容灾,避免单集群故障对可用性的影响。
下面我们分别从读写两个方面来看看具体是怎么做的:

写入高可用由Tikv集群内部的高可用和多集群两个方面共同组成:
Tikv本身跨越3个AZ做三副本存储,单个故障域(磁盘/机器/交换机/机房) 故障不会影响集群可用性;
Writeable所在Tikv集群故障,写入可以快速切换到Backup,且Backup和Writeable所在物理Tikv集群不会是一个集群,确保写入不会中断。

对于已经只读的集群(Readonly, Stable),数据已经不会发生变化,读任意一个副本即可,只要数据存在就可以读到正确的数据,数据的可用性也可以简单的通过增加副本来提升;
对于读写集群中的数据,数据会准实时的通过Binlog来同步到Standby:
a) 数据本身是三副本,保证高可用;
b) 集群不可用的时候,可以直接读取Standby集群数据,做集群级别的容灾。

一般来说,三个AZ高可用的存储系统(例如对象存储数据,元数据系统),由于复制组可以跨越三个AZ,可以简单的容忍单个AZ的彻底故障。但是如果出现了AZ之间的网络故障,导致某个AZ和其它AZ失联,该AZ内部还能正常服务,这个时候就会形成一个孤岛。
对于对象存储来说,对象存储上层的很多业务,比如说数据库/主机等都是在一个AZ内部,也就是说如果某个AZ和其它AZ失联,该AZ内部还是会源源不断的产生数据,我们需要保证孤岛内部生成的数据能成功的写入对象存储,下面我们主要介绍对象存储在这种情况下的处理。
数据孤岛本质上需要解决两个问题:
孤岛形成的时候,需要把数据写入到孤岛内部;
孤岛结束后,需要把孤岛内外的数据做合并。
对象存储包括数据存储和元数据存储两个有状态的服务,下面分别介绍一下我们如何利用多集群来解决数据孤岛的问题:

在数据存储高可用的时候我们提到过,在每个AZ中,我们会部署一套可靠的写缓存服务,写缓存的数据最终会Writeback到跨AZ的存储集群。
由于数据存储可以选择任何一个集群写入,某个AZ形成数据孤岛后,该孤岛内部产生的数据都会写入到本AZ的写缓存,保证了数据写入的高可用。这部分数据最终会在AZ之间重新连接后写入到跨AZ的集群。
由于对象存储数据存储系统是一个不可修改的系统,这意味着孤岛内外不可能会对同一个ID做操作,孤岛结束后数据合并会变的很简单。
对象存储本身允许覆盖上传,这意味着元数据是一个允许修改的系统,这也让元数据存储的数据孤岛解决方案变的相对比较复杂。
和数据存储孤岛不同,元数据形成孤岛后,如果孤岛内外对同一个Object做修改,在一段时间内必然会导致孤岛内外看到的数据不一致,这些不一致最终会达成一致,也就是说元数据存储是一个最终一致的系统。
在对象存储中,我们通过多集群 + 多版本来解决数据孤岛问题。

对象存储支持修改,但是对象存储实际使用中修改相对较少;
一个Key在短时间内(1s)被并发修改的概率很低,我们认为在极端异常情况下毫秒级别的并发修改最终乱序是可以接受的;
极端情况下可能读到老的数据,甚至交替读到新老数据,但是最终会读到确定的一份数据。


上图是一个多版本的元数据管理系统的架构,和最初版本相比,多了一个IDService的服务,IDService本身是一个高可用的Id生成器,它会根据当前机器时间生成单调递增的ID,一个大致的Key的结构为timestampMS_自增ID_IDService集群ID。IDService会多节点部署,保证高可用。
基于IDService,我们实现了多版本的元数据管理系统,任何一次对元数据的修改都会通过IDService取得唯一的ID来作为Version,并且在Tikv中存储下所有Version的元数据。举个例子,两次的PutObjectMeta(Key, meta) + 一次Delete最终会在Tikv中存储下以下三条记录:
Key_version1 -> meta
Key_version2 -> meta
Key_version3 -> DELETED
由于IDService生成的是有序的,该Meta的所有版本中版本最大的记录就是Meta的最新记录,比如上面的例子,最新记录是删除记录,该Object已经被删除。

下图是一个孤岛故障切换的例子,在该例子中,AZ1形成了数据孤岛,AZ2和AZ3能正常互联。
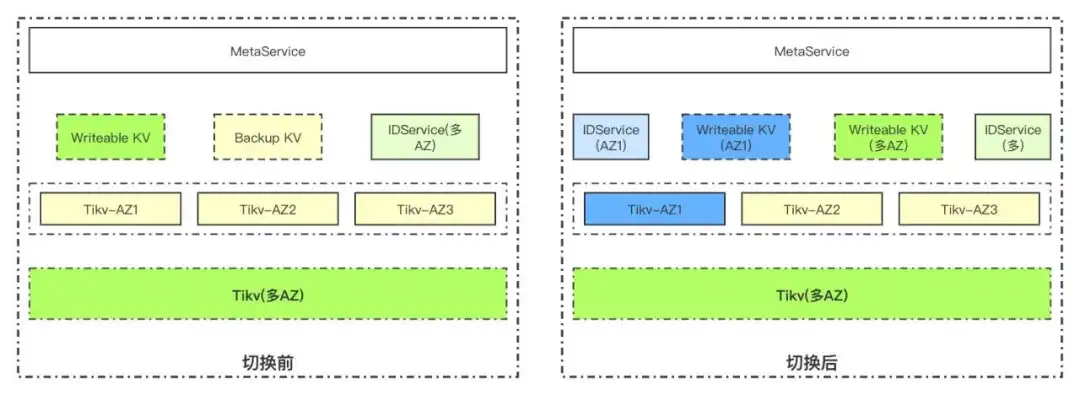
在上图可以看到,我们会在每个AZ部署独立的AZ内部独立的Tikv和IDService, 在AZ1形成数据孤岛后,整个Meta的服务会分成两个独立的部分:
全局的Meta服务(绿色部分),会使用跨AZ的Tikv和IDService,此时服务于AZ2和AZ3;
AZ1内部Meta(蓝色部分),会写入到AZ1内部的Tikv。
在Meta分裂成两个集群后,所有的写入都可以成功。

在AZ1恢复和AZ2,3互联后,所有的写入会切换到多AZ多集群,AZ1内部Tikv集群的数据需要合并到跨AZ集群。
由于Meta实现了多版本,多个IDService之间也保证能生成唯一的ID,也就是说Key_Version是唯一的,因此AZ1内部Tikv的数据可以直接合并到跨AZ集群即可。
基于以下原因,合并是有效的:
IDService根据机器时间生成自增ID。
多个IDService机器的时间偏移保证可控。
极端异常情况下可以接受段时间内乱序。
基于以上三点,可以保证直接合并的结果符合我们预期。







