OLAP Platform Construction Practice of ClickHouse in Industrial Internet Scenario
JDT Developer
2022-01-12
IP归属:未知
111 browse
I. Background
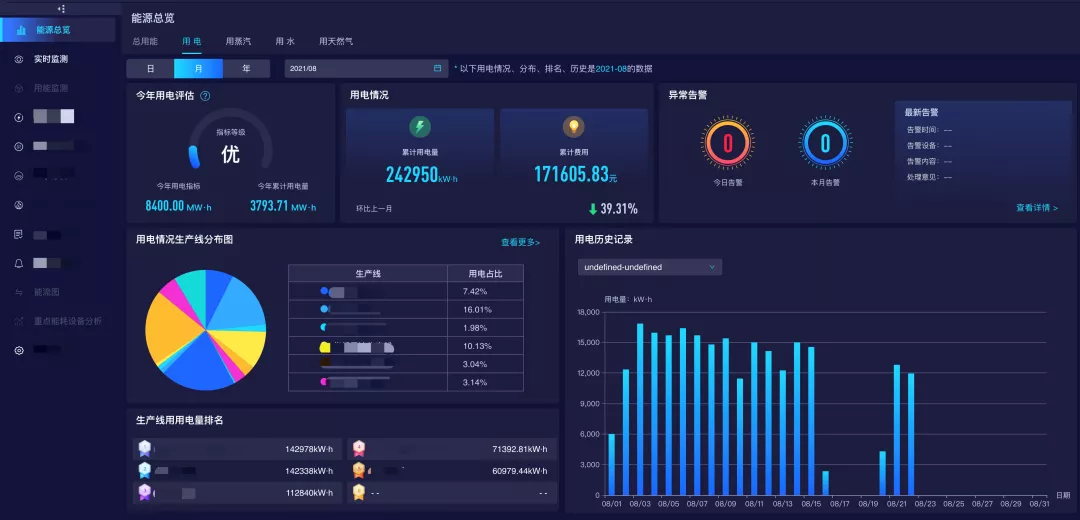
JD Industry BG (“JD Industry”) is a new independent business group established in 2021, engaging in four major business segments including industrial products, industrial services, and industrial interconnection. Industrial interconnection business mainly aims to build industrial Internet platforms where real-time on-site industrial data will be imported for analysis and data intelligence. Currently, it supports the businesses such as the state grid management platform, integrated energy, carbon neutral trading and electricity trading. The application of JD Cloud’s ClickHouse in integrated energy of JD Industry will be highlighted in the article. The data in the industrial Internet scenario mainly has the following three features: I. Large volume There may be hundreds of devices in micro customers and hundreds of thousands of instrumentation devices for large customers. The reporting frequency of these devices ranges from 1 to 60 per minute, so the volume of reported data is very large. II. High requirements for real-time queryMost customers often use visualization screen real-time applications as real-time dashboards, and keep monitoring them, making real-time applications the most frequently used applications.
Example of a Real-Time Application Dashboard
III. High requirements for data consistency
The underlying environment may change frequently, resulting in unpredictable dirty data. However, mistakes are not allowed by customers. In the case of device disorder, there have been instances where the wrongful deployment of devices resulted in misalignment of reported data in a long period; in the case of new fields, new fields may be added if a customer updates the devices globally; in the case of unit conversion, such as converting t/h into kg/h, the value may be magnified 1,000 times instantly.
II. Technical Architecture
Industrial Internet platform has also experienced the evolution of the following technical architecture due to the evolution of business architecture.
Architecture 1.0 Storage-aggregation separation
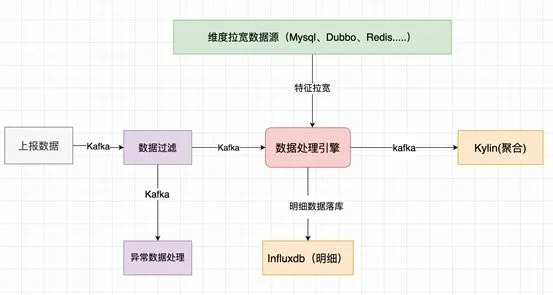
Generation I architecture The overall architecture of the Generation I is shown below, which is comprised of the following important components: data filtering, data processing engine, Influxdb and Kylin.
Data filtering
1. The Policy Factory filters dirty data by global general rules + enterprise-specific personalization rules. 2. Process for handling abnormal data. Changes in the environment ahead may lead to misjudgment, in this case, abnormal data shall be forwarded and stored temporarily.
Data processing engine
1. Widening of dimensions and features Such as the device dimensions, organizational structure dimensions, and alarm rules used for OLAP and algorithm model 2. Data differential- Dimensions such as traffic and electricity are convenient for complex query instantaneous status and complex aggregation- Anti-intermediate data loss
3. Warning and alarm
- Monitor whether non-dirty data triggers alert rules set by the enterprise- Trigger the alarm processing process
Influxdb
Entering detailed time series data into database
Kylin
Query aggregated data
Business performance and feelings
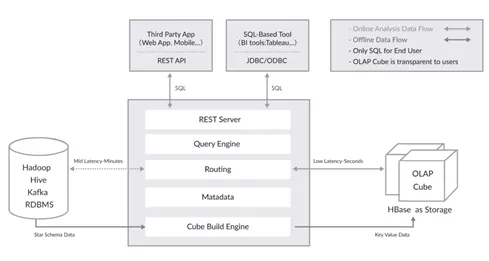
Actual Business Performance of Kylin 1. Dependent hadoop environments should be built in advance, resulting in heavy operation and maintenance workload.2. The combinational relationships of cube, dimension, measures, etc. should be preset in advance and cannot be changed after launch.3. It is merely a query engine based on predictive computing that cannot store data, so it is impossible to query detailed historical data.
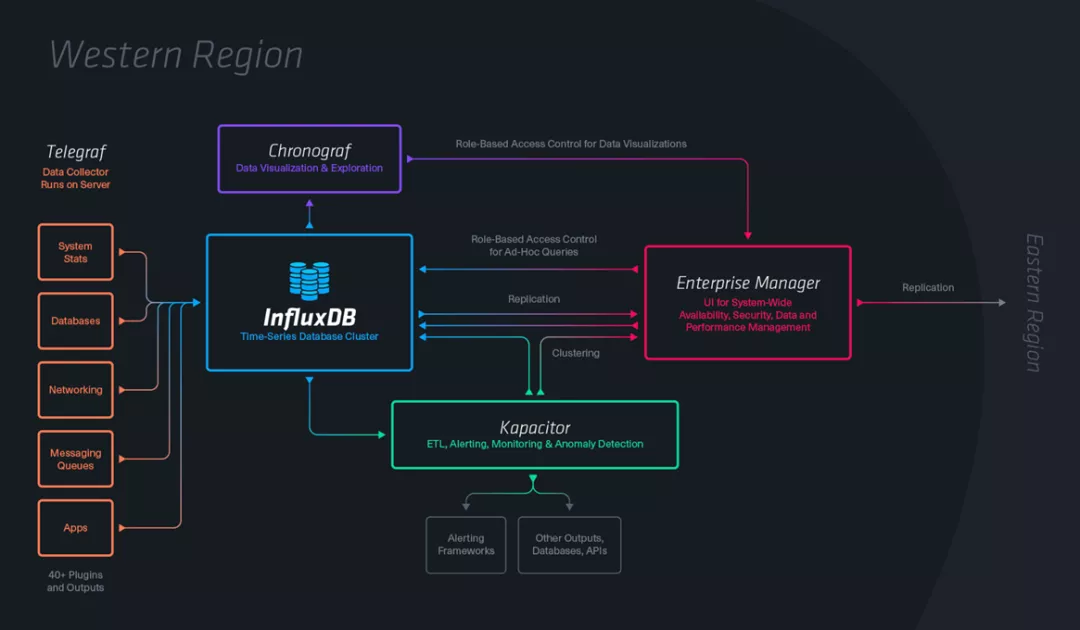
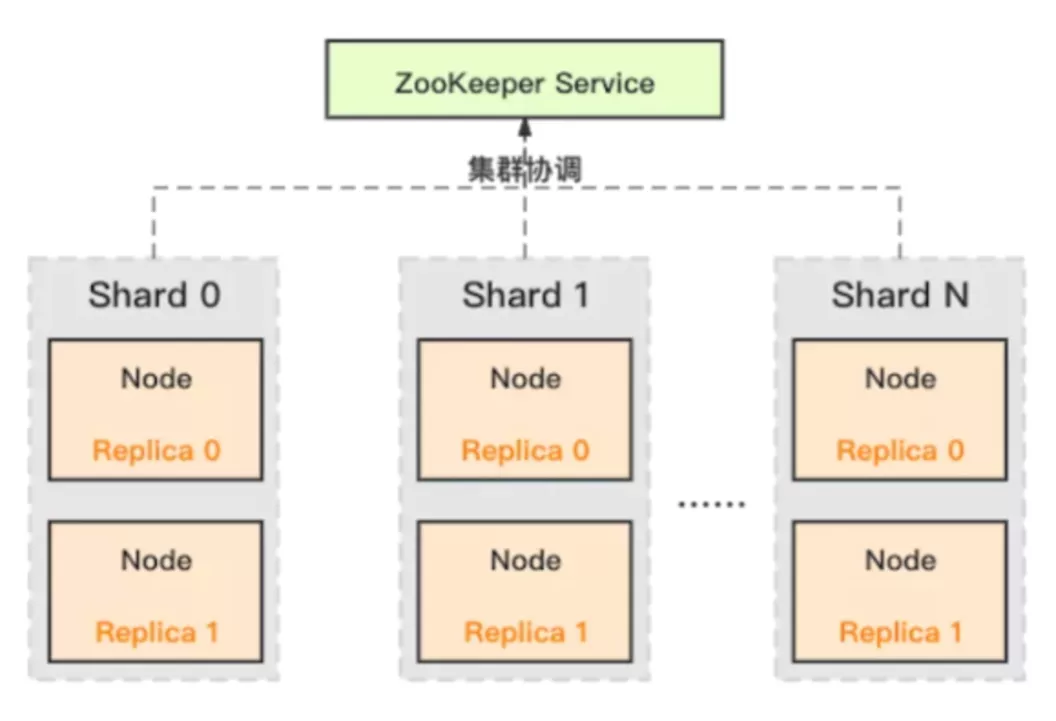
Influxdb Architecture
Actual Business Performance of Influxdb
1. At that time, the distributed version was not open sourced, and operation and maintenance was rarely known by people then; 2. It is hard to find supporting tools and documentation, and get started. And the concepts of tag, series, fields, etc. were not easy to understand...; 3. The aggregation query performance was poor, and the detailed query had not ever been improved; 4. It hasn’t been endorsed by core applications of large manufacturers.
Comprehensive Feelings
1. Heavy operation and maintenance workload: Two sets of databases should be operated and maintained, in addition, Kylin often crashed in the test environment with average performance2. Difficult to use: One had to distinguish between querying detailed and aggregated data3. Data inconsistency: The data should often be changed in IoT and industrial scenarios4. The architecture could basically meet the requirements, but its demerits outweighed merits, therefore, a better architecture solution was needed
Architecture 2.0 ClickHouse that merged the two into one
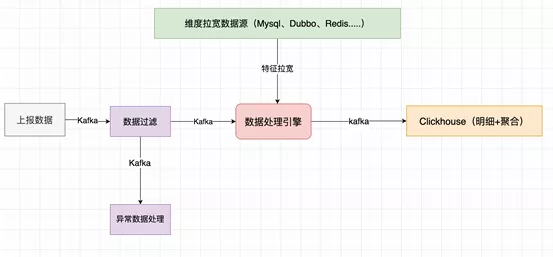
The Generation II architecture aimed to address the three pain points of the first generation: I. The operation and maintenance workload was heavy, and two sets of storage frameworks were required; II. It was difficult to use and the data sources should be distinguished during querying; III. It was difficult to maintain the consistency of data. The Generation II architecture employed the practice recommended officially by ClickHouse: Kafka engine table + objectification process + local table + distributed table
Merits and Demerits of Generation II Architecture Merits: 1. It addressed all the pain points and required only one set of solution. 2. It has outstanding performance. It supports stable and high-throughput data writing, which can meet the basic storage requirements for middle-end construction. It features ultra-high data compression rate which helps save disk storage. In addition, with reasonable index settings, the data query speed is extremely fast. Demerits:1. Huge data volume; 2. The QPS was not high enough for toC.
Business Performance
ClickHouse Architecture
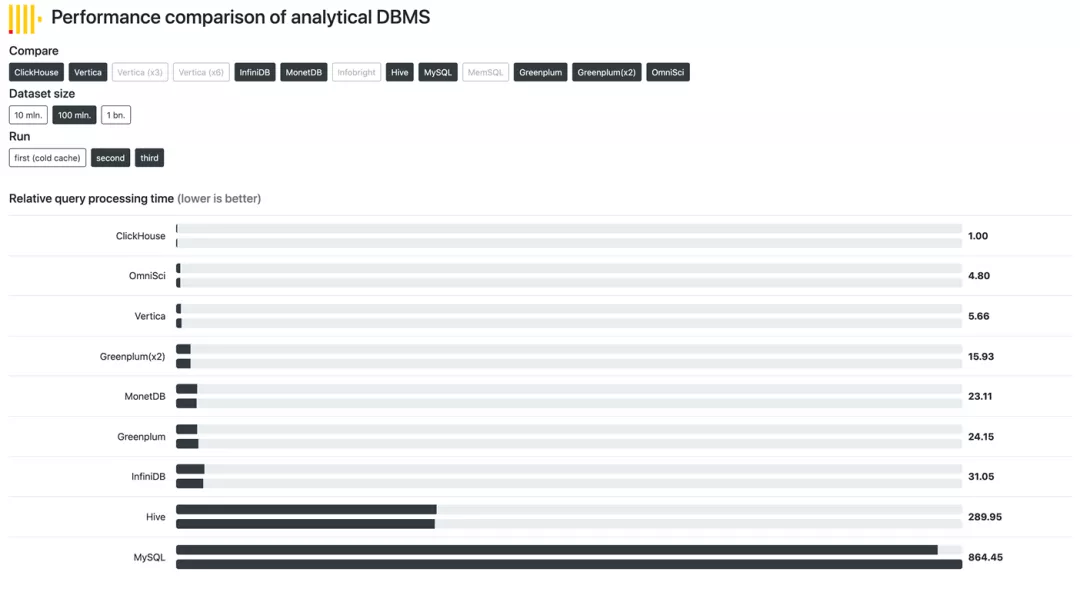
Performance Comparison of ClickHouse
Practical Feeling I. The architecture is clear and concise. It adopts the simplest multi-primary shard structure, and only depends on several zks, enabling the setting up of any operation and maintenance in merely half a day. II. It is a one-stop solution that can not only store data, but also query data, with favorable performance optimization of the query internally by default. III. It is easy to use with user friendly SQL, basic mysql skills are adequate for using ClickHouse freely. In summary, ClickHouse is an excellent package for storing and querying data, and is a great choice for scenario of querying aggregated data that involves a lot of actions, such as “group by” and sorting. It also provides adequate support for DBMS. In addition, it operates the same as mysql, greatly simplifying the operation and maintenance, as well as R&D.
I. High data throughput for instantaneous queryThe data is basically partitioned by day. If switched to “year”, the data of 365 partitions will be aggregated instantaneously for the API, and the API will be delayed for 5~10s. II. High QPS for instantaneous queryThere are a surprising number of large-screen application components. Roughly, more than a dozen SQLs will be submitted to ClickHouse in an instant when the large screen of the home page is refreshed. In the case of query by year that spans 365 partitions, the workload will increase sharply. It is advisable to perform a maximum of 100 query operations per second.
In view of the above, people began to consider trying to build a real-time data warehouse in the next-generation architecture: separating production from consumption
Architecture 3.0 ClickHouse + real-time data warehouse
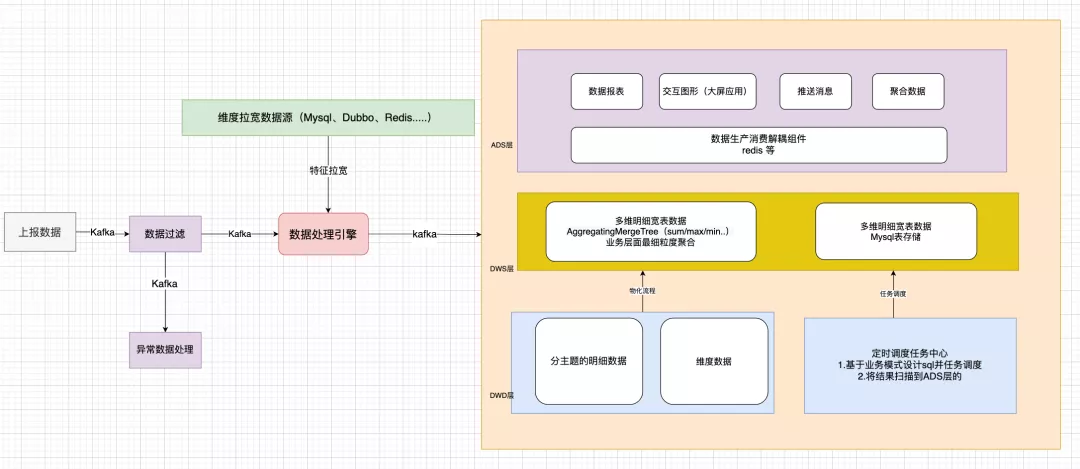
The Generation III architecture is as follows:
DWD detailed data layer:
1. Detailed big and wide table data by topic. The big and wide table is decoupled and split in business. 2. Dimensional data. It is recommended to widen the dimensions in advance to avoid “join”; spare fields can be reserved for mapping in business. DWS data aggregation layer:1. Aggregation of objectification processAggregatingMergeTreeOrientation: Oriented to scenarios where detailed data is not frequently modifiedMerits: Simple and fast implementation, smooth performance, and obvious query optimizationDemerits: It takes time for evaluation and modification in case of change in detailed data
2. Fixed-time task scheduling
Online/offline scheduling of script or visual tasksOrientation: Oriented to scenarios where detailed data is frequently modified, strong data consistency is requiredMerits: Data consistency can be guaranteedDemerits: Pre-construction work is required, including analysis and extraction of business data models. ADS data application layer:1. Data production and consumption decoupling layer: It employs Redis, and is designed according to QPS 5W+2. Data application: It employs the data in Redis directly without accessing the lower-level data warehouse.
III. Summary of ClickHouse Practice
Applicable Scenarios of ClickHouse I. It is applicable to OLAP scenario for complex query of aggregated data and does not support the OLTP scenario. It is typically characterized by the use of a large number of “group by” and “order by” operations.
II. It needs to support stable mass data writing.
ClickHouse can generally support data writing of hundreds of MB per second, and this figure would be greater for optimized version. III. It does not require frequent queries.It can be used without login. It is advisable to perform a maximum of 100 query operations per second. However, this speed can be greatly increased after optimization according to the above real-time data warehouse solution. It is most suitable for scenario of internal use by internal operation personnel. IV. It is an excellent solution in scenario where you need detailed query beside OLAP aggregation. V. In addition, it does not require advanced DBMS capabilities such as transactional function, nor frequently complex inter-table operations such as join.
Practice in Applicable Scenarios of ClickHouse
I. It employs the officially advised big and wide table process, i.e. Kafka engine table + objectification process + local table + distributed table. It solves problems by means of advanced ETL process of “dimension widening + big and wide table + reasonable objectification”, instead of complex inter-table join. A large number of different table engines of the mergeTree family are used, such as in data deduplication, data aggregation and other special scenarios. II. All database solutions are part of the data warehouse solution, which should be taken into account from the perspective of the data warehouse.
There’s no absolute “silver bullet” that can solve all data problems. All we could do is to use databases with reasonable collocation, maximize strengths and circumvent weaknesses, and give full play to their functions.