

The retrieval of address keywords is especially important in scenarios related to maps or geographic information. For example, if we open Baidu Map APP and want to search a location such as “China Agricultural University, No. 17, Qinghua East Road, Haidian District, Beijing”, we would often enter the keyword “China Agricultural University” instead of the detailed address information including the street. Behind the address keyword search, we need a database that can support both full-text search and fuzzy query to match this requirement, so as to quickly improve the efficiency of address search.
PostgreSQL, known as “the world’s most advanced open source database”, boasts powerful text search capability, which not only supports full text search, but also fuzzy query and regular query. In addition, its built-in expression index and Gin index features, plus the rich plug-in ecology make it greatly outperform others in terms of address keyword search.
A PostgreSQL-based logistics address keyword retrieval method was introduced in the paper to illustrate how to use PostgreSQL to improve the retrieval efficiency of logistics address keywords.
I. Application Background
In the scenario of address retrieval, the keywords will be segmented after the user enters the address keywords, and then matched with the address corpus database through the full-text index technology to obtain the normalized address information, and then the address will be located on this basis. Generally, the address retrieval statement will be divided into several keywords after address word segmentation, and then the keywords are matched with the historical address corpus database, and then the retrieved results will be returned to the retrieval statement.
It usually takes several seconds to tens of seconds from entering keyword for query to returning results due to different keyword segmentation and matching methods.
The retrieving the entries in a database is a very basic and common feature, which can be realized in many ways, including:
1. Professional independent search engines such as Elasticsearch or Lucene
2. Retrieval function of the database
Professional systems such as Elasticsearch can provide relatively flexible retrieval functions, however, they are often associated with high operation and maintenance costs. Therefore, the technical solution to realizing most retrieval scenarios in Chinese quickly and efficiently with the built-in features of PostgresSQL will be discussed here.
II. Technical Solution
Based on the characteristics of PostgreSQL index and word segmentation model, we constructed about 100 million rows of address data with the scope of Beijing for performance testing, which turned out that PostgreSQL could significantly improve efficiency in logistics keyword retrieval scenarios by comparison and analysis. The test results are as follows:
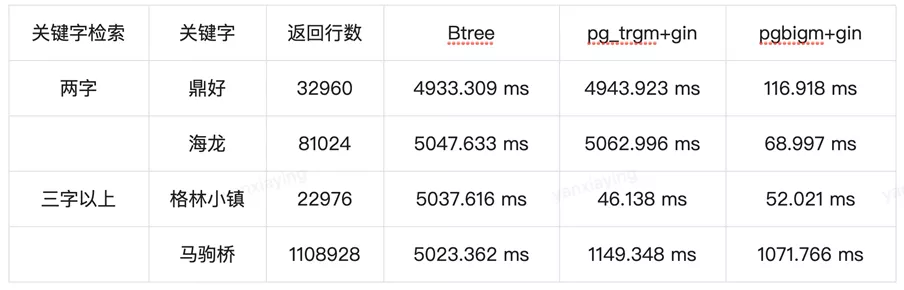
As can be seen from the above results, both pg_trgm+gin and pgbigm+gin greatly outperform commonly used Btree when performing fuzzy queries. Meanwhile, since the TOKEN generated by pg_trgm has three characters, the corresponding TOKEN can be matched only if there are more than three characters. In the case that there are less than 3 characters, one or two characters in the front or in the rear will be fuzzy searched, so the retrieval performance is obviously downgraded. In comparison, pgbigm (based on binary Tri-Gram) is more efficient in processing single-character and double characters. As the logistics keywords are more than three characters, the pg_trgm+gin solution is used for keyword retrieval, so as to ensure the response time at the millisecond level.
In addition, text address data often share the characteristics of natural language. jieba word segmentation is a powerful word segmentation database, its word segmentation is more in line with the characteristics of business attributes. Its main functions include: supporting different modes of word segmentation, custom dictionaries, keyword extraction, and part-of-speech tagging. pg_jieba, based on the algorithm of jieba word segmentation, builds a PostgreSQL Chinese word segmentation plugin, which also performs well in terms of word segmentation.
III. Conclusion
In summary, PostgreSQL supports rich indexes, has powerful full-text retrieval capabilities and a variety of plug-in ecosystems, and supports text queries in different scenarios. With this tool, users do not need to synchronize data to search engines for query. The use of PostgreSQL can greatly simplify the user’s architecture and reduce development costs, while ensuring absolute real-time data query.
JD Cloud PostgreSQL is a powerful cloud relational database built on the basis of the open-sourced PostgreSQL, which supports a variety of data types and geographic information expansion, and has powerful parallel computing capabilities. It supports a complete set of solutions for backup, monitoring, migration, etc.






