

Background
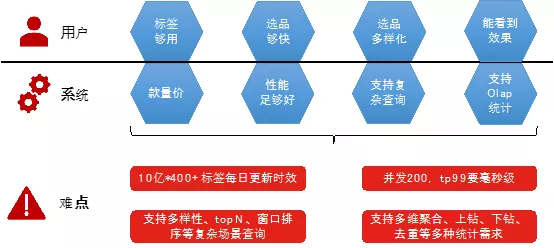
Solutions to R&D Obstacles

I. Specific Technical Solution
Here are the specific design solutions for the storage structure of ClickHouse and Elasticsearch:
2. Data push and verification for ClickHouse

3. Data push and verification of Elasticsearch.

II. Technical Solution Implementation Process

III. Test Conclusion
Future Perspectives






