Home Page
Column
Online Course
Developer Tools
Home Page
Column
Online Course
Developer Tools
更多
Follow the community
User Center
Developer Center
>
Column
>
Details
Slimming practice of basic data cache in distribution
Self-justification Tech
2021-05-17
IP归属:未知
73570 browse
Computer Programming
## I. Background In the actual operation process of modern logistics, a large amount of data related to operation-related information will be generated, such as information data related to merchants, fleets, sites, sorting centers, customers, etc., which directly support the entire business flow of logistics and play a very important role. For this type of data, we need to provide the basic capabilities of adding, deleting, modifying, and saving. Currently, the basic data of JD Logistics is the overall responsibility of the middle-end distribution team. Among the conventional capabilities of basic data, the data access is the most basic and important capability. In order to improve the overall data reading capability, Redis technology has been widely used in basic data scenarios. This article focuses on the recent slimming practices of data Redis by the distribution team. ## II. Solution: In this optimization, we have selected the basic information of merchants and two systems of C background for the pilot optimization of Redis data. From the results, we have achieved very significant results and saved a lot of cost in terms of hardware resources. The Redis usage before and after optimization is compared in the following data: **The Redis data volume of the merchant’s basic data has been reduced from 45G to 8G;** **The Redis data volume of C background has been reduced from 132G to 7G;** The results reflect the significant optimization effect. Below, we will reveal how it did so step by step. First, the current merchant basic data uses @Caceh annotation component as the caching method, which will put the values found from the db into the local Redis and jimdb. As the earlier versions of this component did not have jimDB default expiration time and did not explicitly declare it when using annotations, a large number of early keys had no expiration time, resulting in a large number of zombie keys So if we can find these zombie keys and optimize them, then we can reduce the Redis as a whole. But how can we find these keys? #### 2.1 Keys Command Many people might think of the simple keys command, which traverses all keys in turn to determine whether there is an expiration time. However, Redis is executed in a single thread, and the keys command will be executed in a blocking way. If the complexity of the traversal implementation is O(n), the more keys in the library, the longer the blocking time will be. Usually, our data volume will be more than tens of gigabytes, which is obviously unacceptable. #### 2.2 Scan Command Redis 2.8 provides the scan command, which has the following advantages over the keys command: - Although the time complexity of the scan command is also O(N), it is performed in stages and will not block the thread. - The scan command provides a limit parameter similar to that in sql, which can control the maximum number of results returned each time. Of course, it has some disadvantages: - The returned data may be duplicated, the reasons are described in the extension at the end of this article. - The scan command only ensures that all existing keys will be traversed before the command is executed. The data added or deleted during the command execution may or may not be returned. #### 2.3 Basic Syntax This seems to be a good choice for now, so let’s look at the basic syntax of the command: SCAN cursor [MATCH pattern] [COUNT count] - cursor: Cursor - pattern: Matching pattern - count: Specify how many elements to return from the dataset, the default value is 10 #### 2.4 Practice First of all, it feels like incremental iteration based on the cursor. Let’s look at the actual operation: 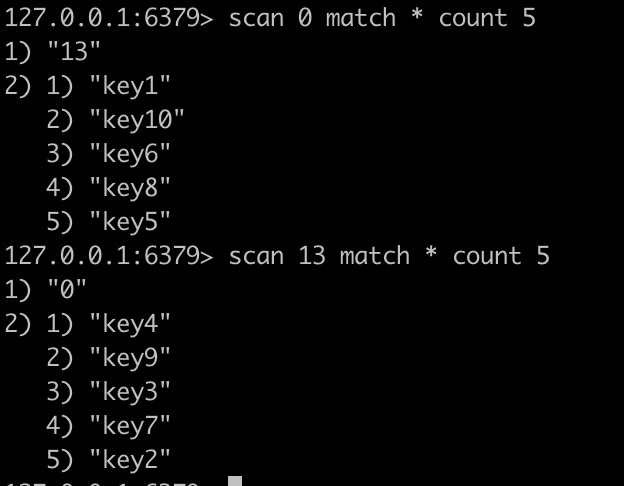 We just need to set the prefix of the matched key, loops through and traverse it to delete the key. This can be triggered by Controller or by calling the jsf APIs, using cloud Redis-API, as shown in the demo below: 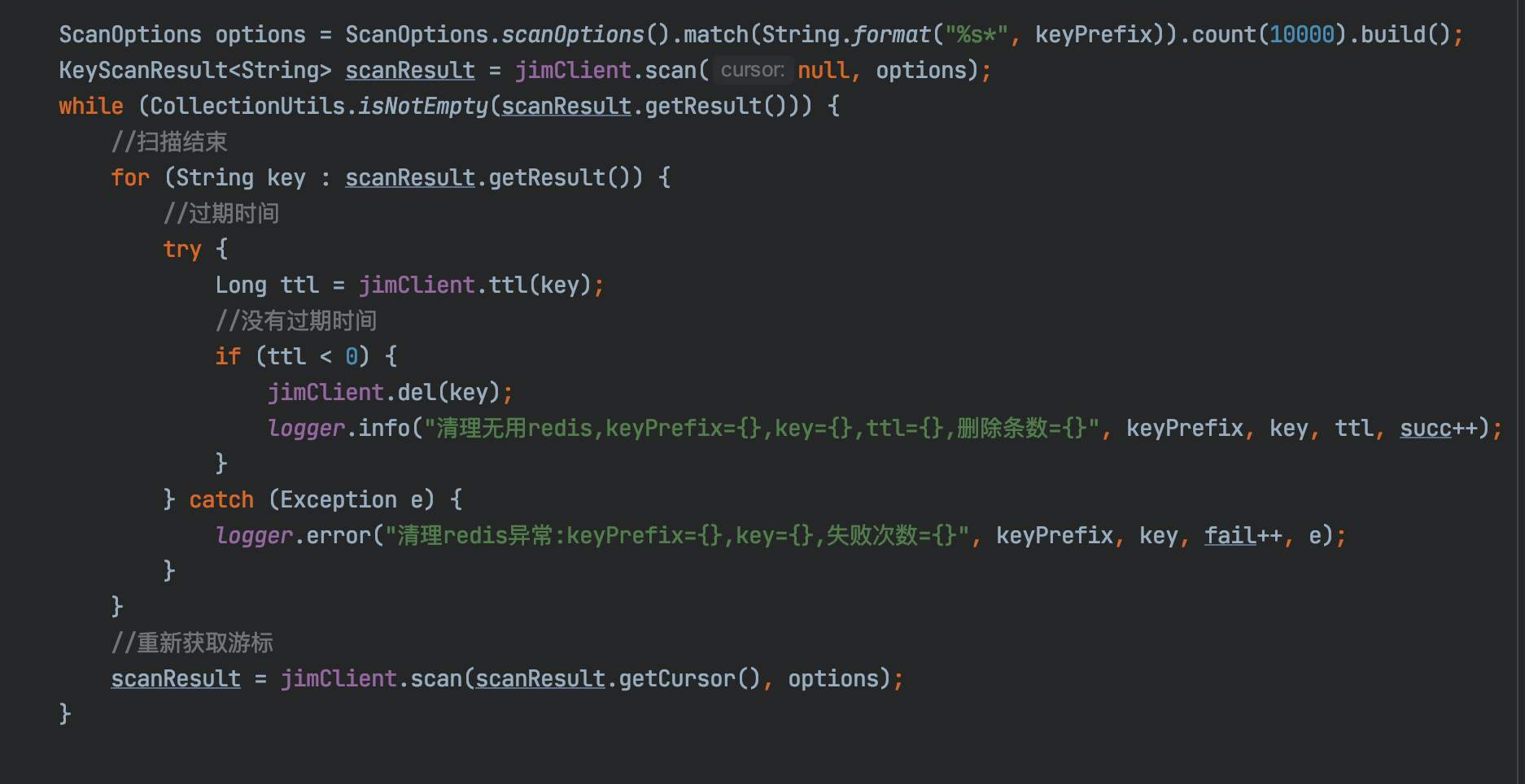 OK. We make it. Execute the randomkey command on the administration terminal to view it. There are still a lot of useless keys out there, and there seem to be a lot of keys overlooked there. What’s going on here? Now it’s time for our favorite mistake part. #### 2.5 Instructions for Avoiding Mistakes It is found that by adding days, the result set returned is empty, but the cursor is not over! In fact, it is not difficult to find that the scan command is different from the conditional paging query in the database. Mysql queries data according to the conditions, and the scan command traverses the results according to the number of dictionary slots, and then matches the qualified data and returns it to the client. Therefore, it is very likely that there is no qualified data in the iterative scanning for many times. We modify the code to use the scanresult.isfinished () method to determine if the iteration has been completed. 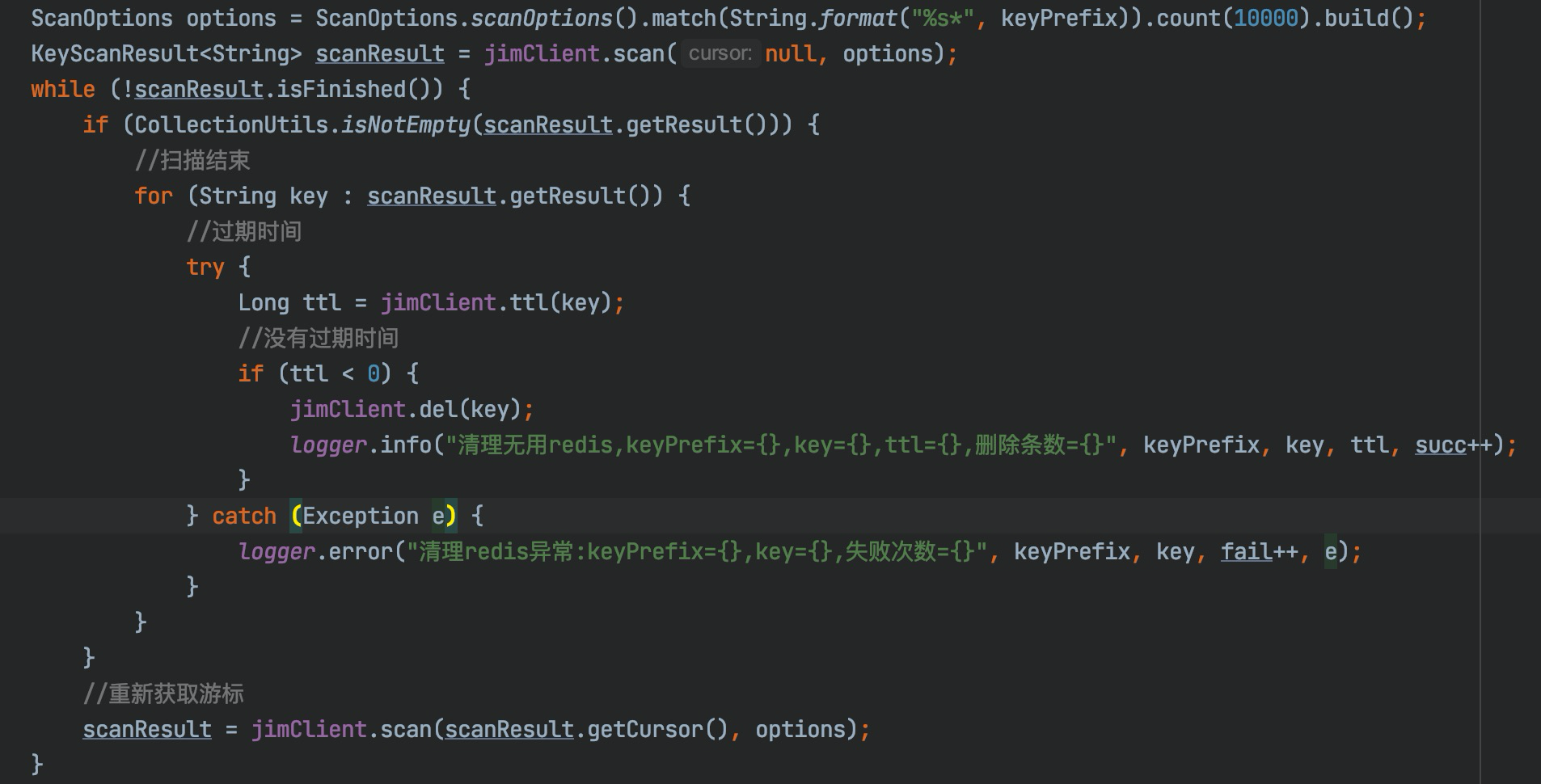 So far the program runs normally. After that, different matching characters are passed to clear the Redis. ## III. Expansion of Knowledge Here we will discuss the problem of duplicate data: Why the traversed data may be duplicated? #### 3.1 Duplicate Data First, let’s look at the traversal order of the scan command: 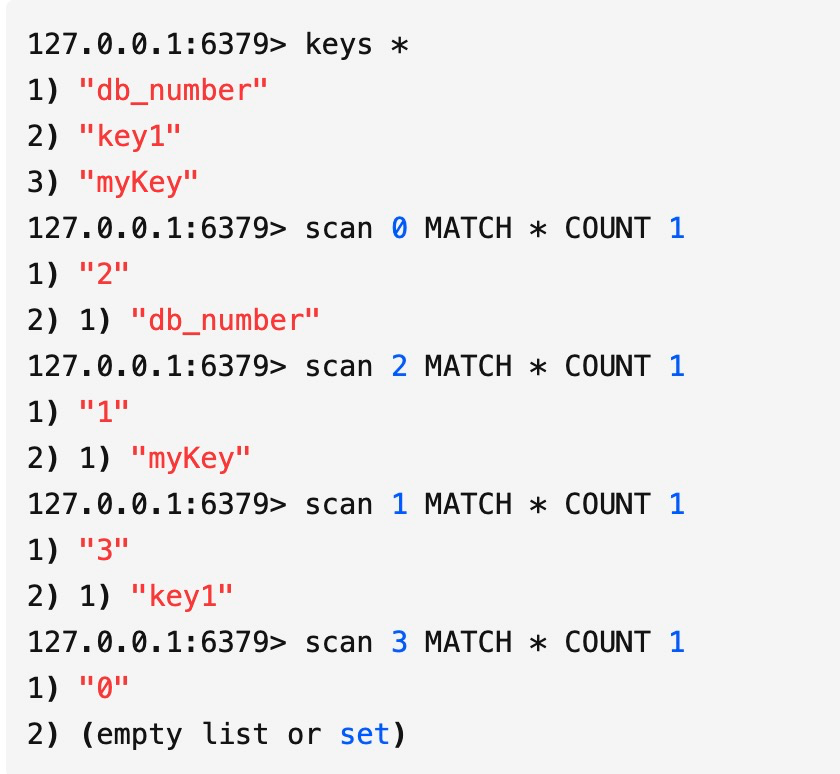 There are three keys in Redis. When we check with scan command, we find that the traversal order is 0->2->1->3. Why not 0->1->2->3? As we all know, due to hash conflicts in HashMap, when the load factor exceeds a certain threshold, the Resize operation will be performed for the sake of the performance of the linked list. The same is true for Redis, where the underlying dictionary table will be dynamically transformed, and this scanning sequence is also designed to deal with these complex scenarios. **3.1.1 Several states of dictionary table and problems with sequential scan** - The capacity of dictionary table has not been expanded The field tablesize remains the same, and there is no problem with sequential scans - The capacity of dictionary table has been expanded 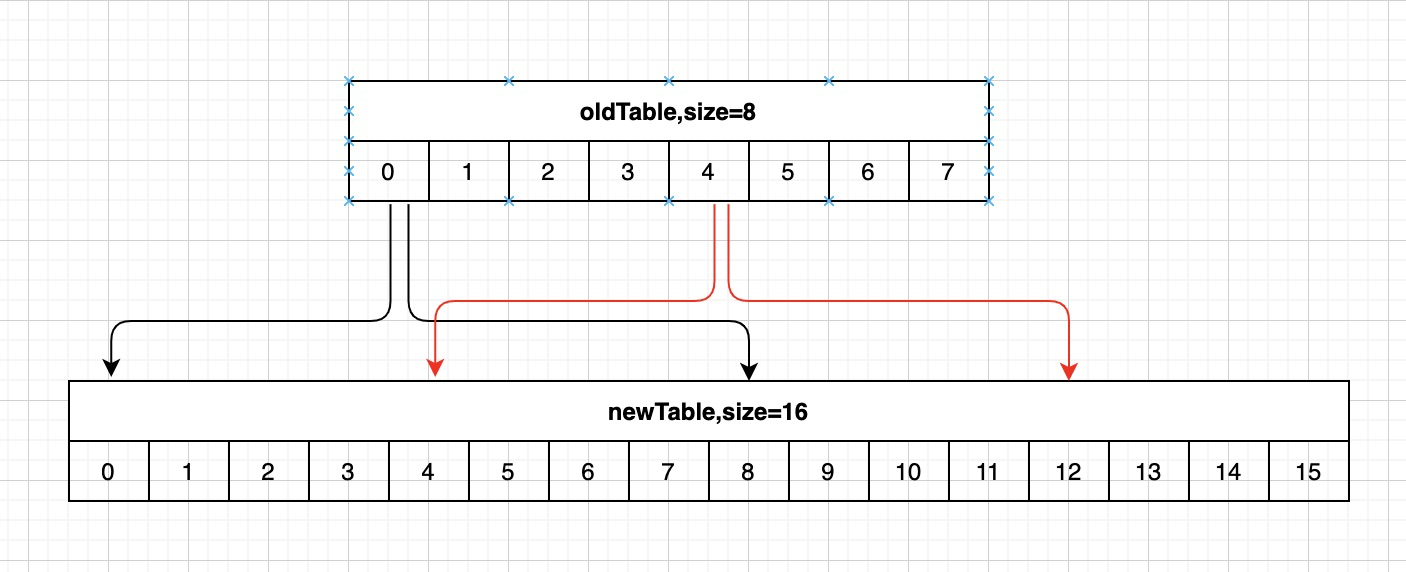 If the dictionary tablesize changes from 8 to 16 and bucket 3 has been accessed before, now the data in buckets 0 to 3 has been rehashed to buckets 8 to 11. If you continue to access buckets 4 to 15 in sequence, then these elements will be traversed repeatedly. - The capacity of dictionary table has been reduced 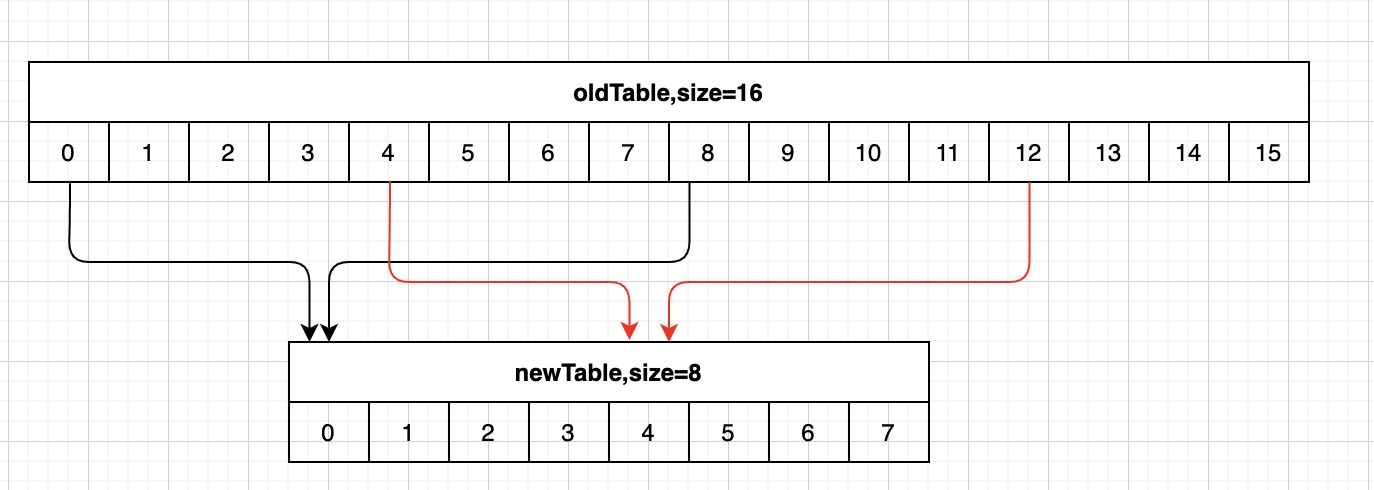 If the dictionary tablesize is reduced from 16 to 8 and bucket 3 has also been accessed, now the elements in buckets 8 to 11 are rehash to bucket 0. If the data is accessed in sequence, the traversal will stop in bucket 7. In this case, the data is missing. - The dictionary table is rehashing Rehashing is such a status where you may either repeat the scan, or you may miss the data. **3.1.2 Algorithm idea of reverse binary iterator** We convert Redis scanned cursors and sequentially scanned cursors to binary for comparison: 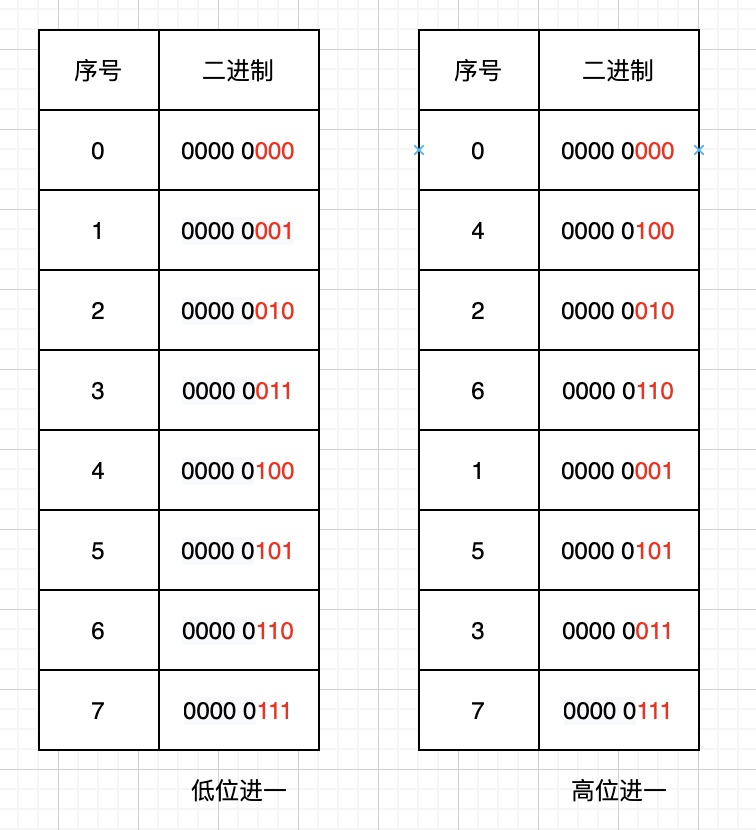 High-order access is based on the dictionary sizemask (mask), in which the significant bits are increased by 1. For example, let’s look how the Scan works: 1. The dictionary tablesize is 8, and the cursor scans from 0; 2. After the cursor returned to the client is 6, the capacity of dictionary tablesize is expanded to twice the previous size, and the Rehash is completed; 3. The client sends the command scan 6; 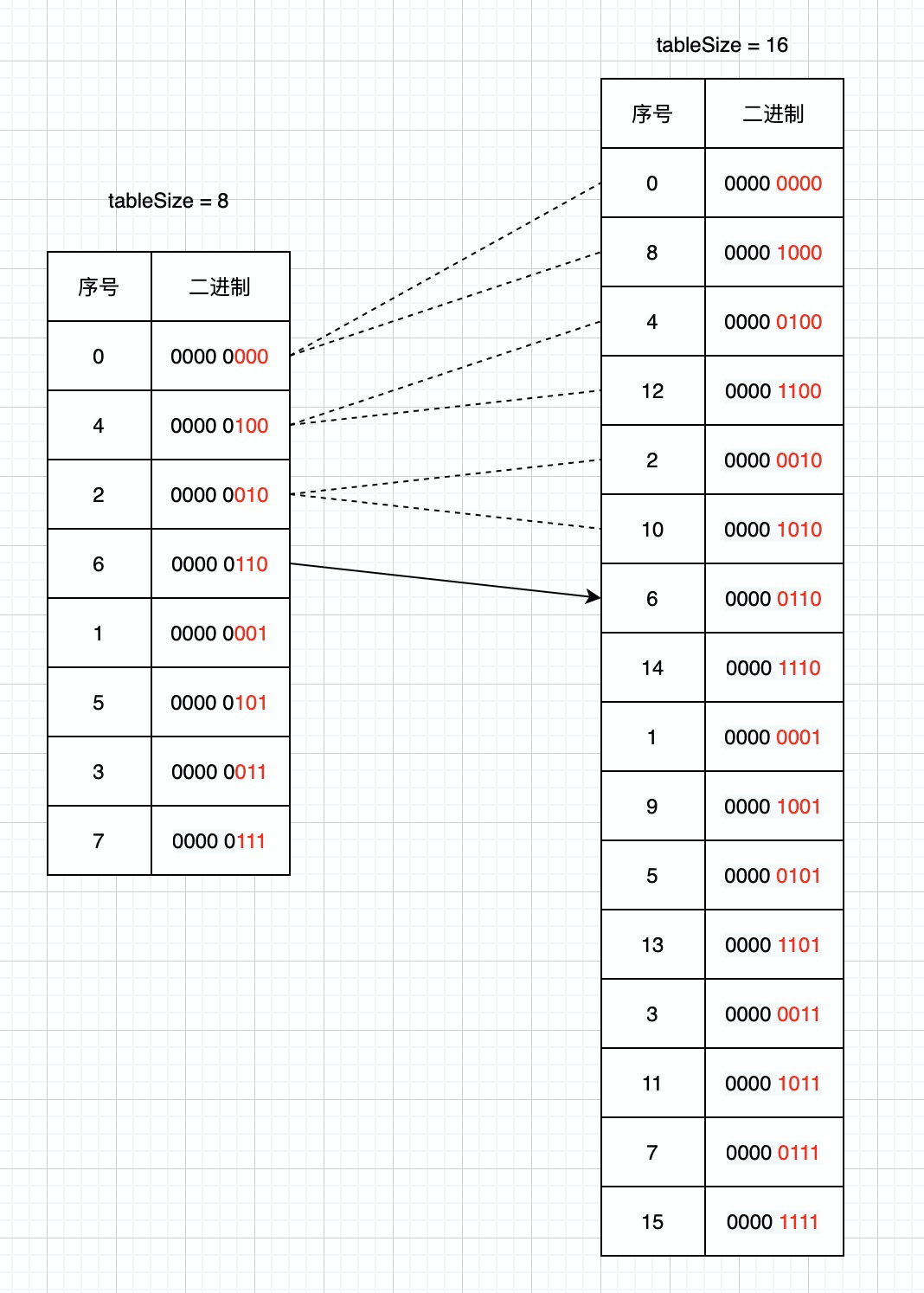 Then the scan command will take out all the linked lists in bucket 6 and return them to the client, and add one to the binary high order of the current cursor to calculate the starting cursor of the next iteration. In the figure above, we can see that the data in slots 8, 12, and 10 has been migrated from slots 0, 4, and 2 after capacity expansion. The data in these slots has already been traversed, so this traversal order can avoid repeated scanning. The same is true for dictionary expansion, but duplicate data occurs precisely in this case: Take the above figure as an example, and then look at the scanning method of Scan during capacity reduction: 1. The dictionary tablesize is 16 initially, and the cursor scan starts from 0. 2. After the cursor returned to the client is 14, the capacity of dictionary tablesize is reduced to half of the previous size, and the Rehash is completed; 3. The client sends the command scan 14; Then the capacity of the dictionary table has been reduced, and the data previously in buckets 6 and 14 has been rehashed into bucket 6 of the new table, and bucket 14 is gone. Then what should we do? Let’s look for answers in the source code: 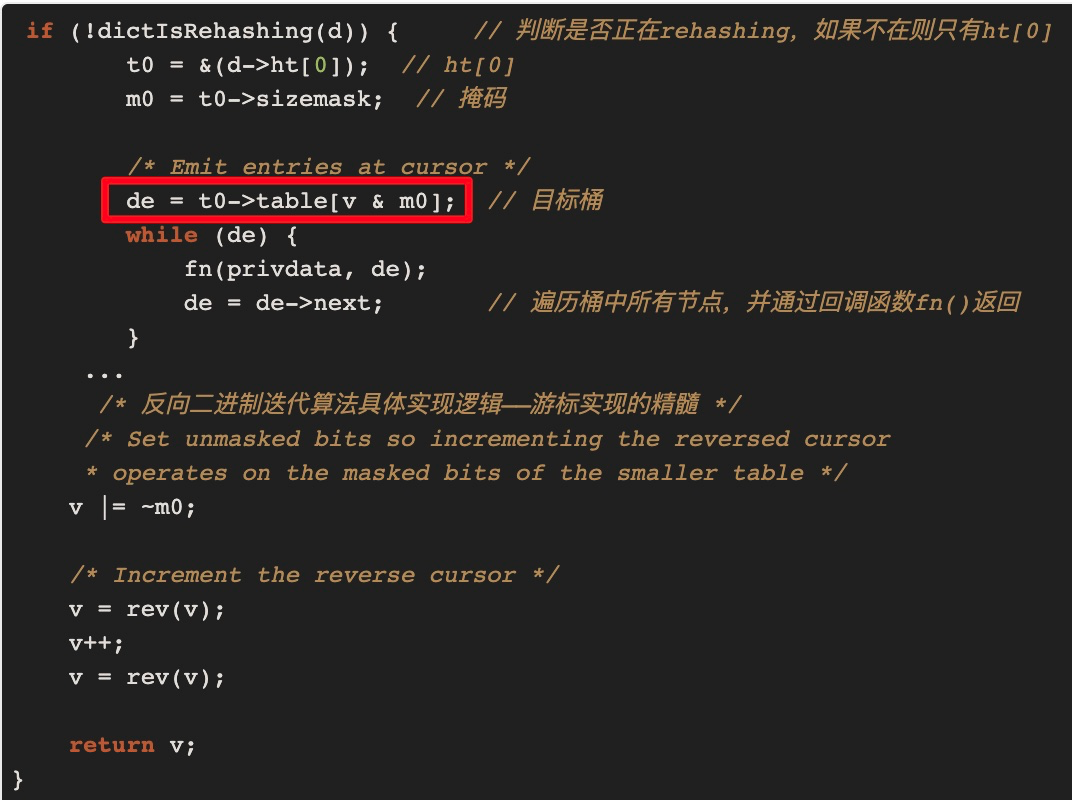 That is, we always look for the target bucket through the calculation using sizemask (mask) of the current hashtaba. v=14 refers to 000 1110 in binary. The mask of the current dictionary table has changed from 15 to 7 (that is, binary 0000 0111), and the value of v&m0 is 6, which means that bucket 6 shall also be scanned on the new table. However, after capacity reduction, the data in buckets 6 and 14 of the old table has been migrated to bucket 6 of the new table. Therefore, duplicate data appears in the scan result, which is the data in bucket 6 that has been scanned before capacity reduction. **Conclusion: In the case of capacity reduction of the dictionary, the data in the high-order bucket will be merged into the low-order bucket (6, 14) -> 6. One shall ensure that no data is omitted in the scan command. Therefore, in order to get the data in bucket 14 before capacity reduction, bucket 6 needs to be rescanned, and duplicate data appears. This is also difficult for Redis. After all, you can’t have it both ways. ** ## Summary Through this capacity reduction practice of Redis, we find that although it is a small tool, it does bring remarkable effects, saving resources and reducing costs. In addition, we also learned the clever design idea about the underlayer of the command and gained a lot during troubleshooting. ------------ ###### Programmer Language Specifications Tech-JDL ###### Author: Zhang Zhongliang, Distribution Platform Team, Middle-end Technology Department ------------
Self-justification Tech
number of articles
196
reading volume
771724
Self-justification Tech
number of articles
196
reading volume
771724
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号


 Self-justification Tech
Self-justification Tech 2021-05-17
2021-05-17 73570 browse
73570 browse






