



技术背景
Taro Native是京东自研的跨平台移动应用开发框架,支持鸿蒙、iOS、Android三端应用开发,实现一次开发、多端部署。 随着秒送业务功能持续扩展,在华为鸿蒙低端机型上出现严重滑动卡顿,影响用户体验。该页面单张卡片包含100+个元素(图片、文本、容器等),渲染耗时显著,其他端亦存在体验下降。本次优化重点针对鸿蒙端,通过性能分析与调优提升用户体验。
性能分析
页面构成
- 外层容器:
WaterFlow实现瀑布流列表 - 单元项:每个
FlowItem承载一张商家卡片 - 卡片构建:TML 模板 → CAPI 创建 Node Tree → 挂载至 ArkTS 侧
NodeContent
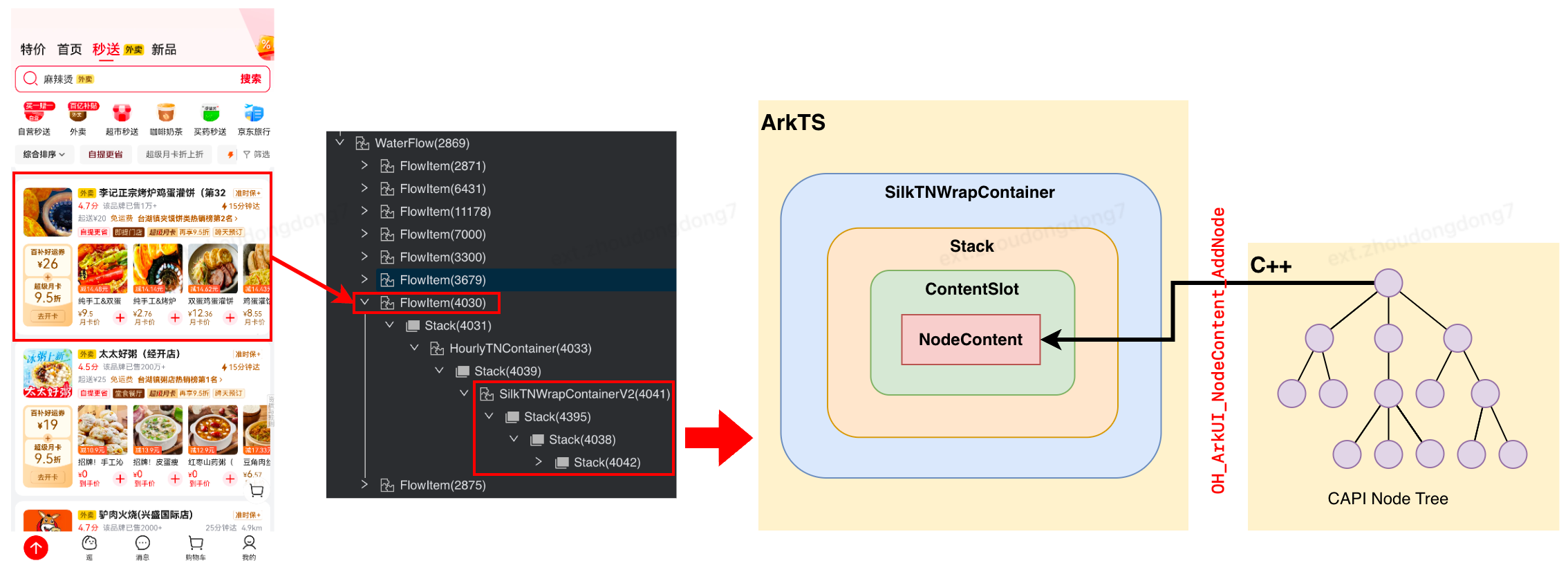
卡片渲染流程
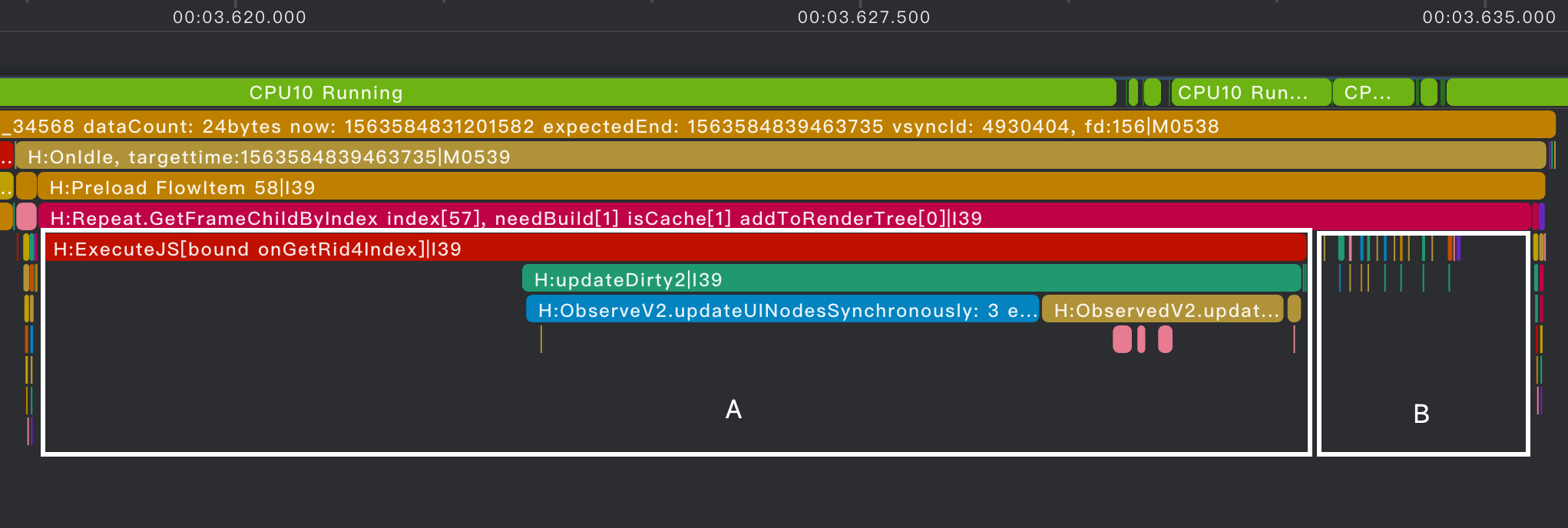
- 页面滑动时,WaterFlow预加载H:Preload FlowItem,调用Repeat.GetFrameChildByIndex获取可复用组件并更新数据,投递解析任务到element线程。
- element线程对TML业务代码进行解析并生成Virtual Dom、CSS Info、yoga渲染树,投递测量布局任务到render线程。
- render线程基于yoga布局引擎对渲染树进行测量布局,同时生成节点创建、属性设置等命令,投递命令集合到主线程。
- 主线程分析命令,调用CAPI接口创建节点、设置属性、更新布局,并将根节点挂载到ArkUI的ContentNode。
- 主线程OnVsync时触发Node Tree的系统测量、布局后,发送给render_service渲染上屏。
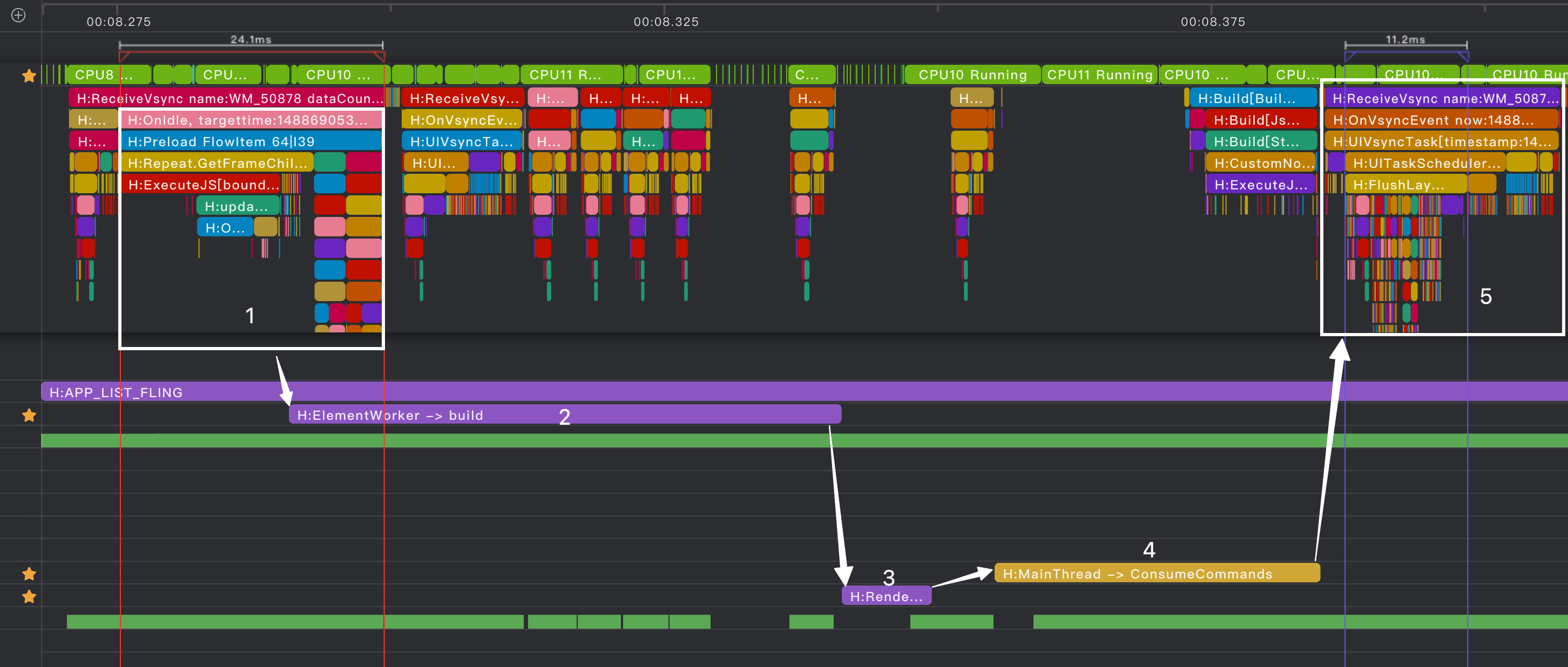
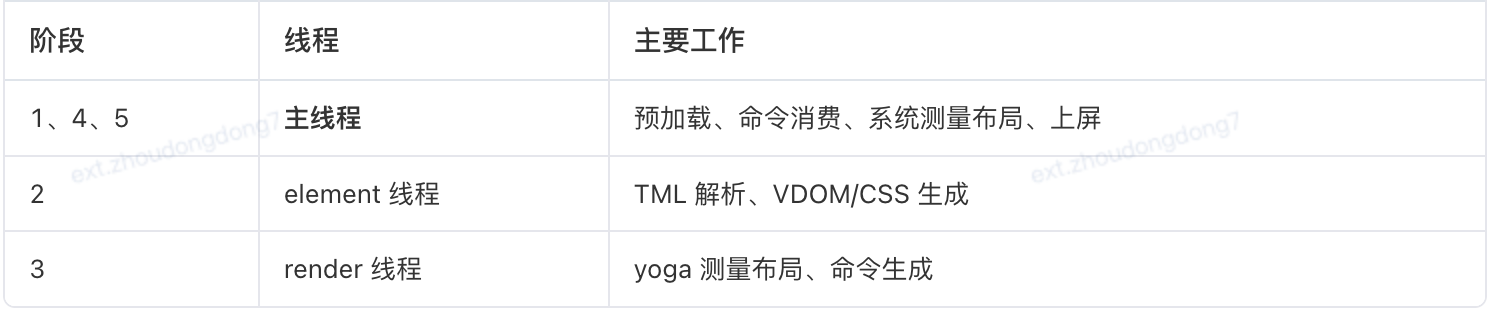
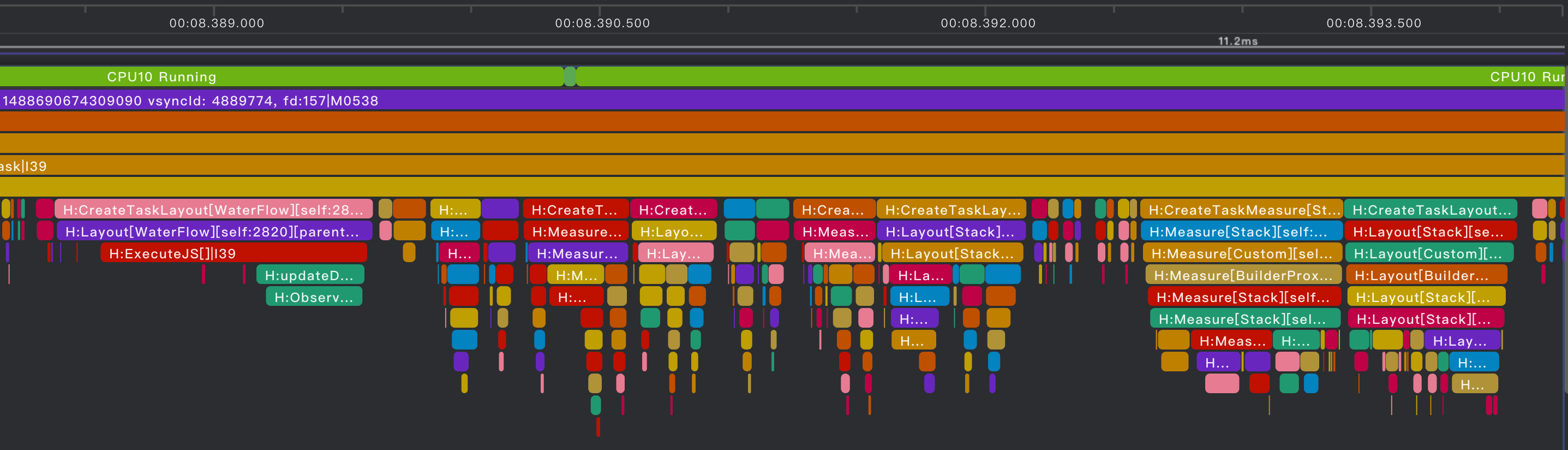
从上面流程中可以观察到,滑动卡顿的根源在于 主线程过载,应聚焦阶段 1、4、5 进行深入优化。
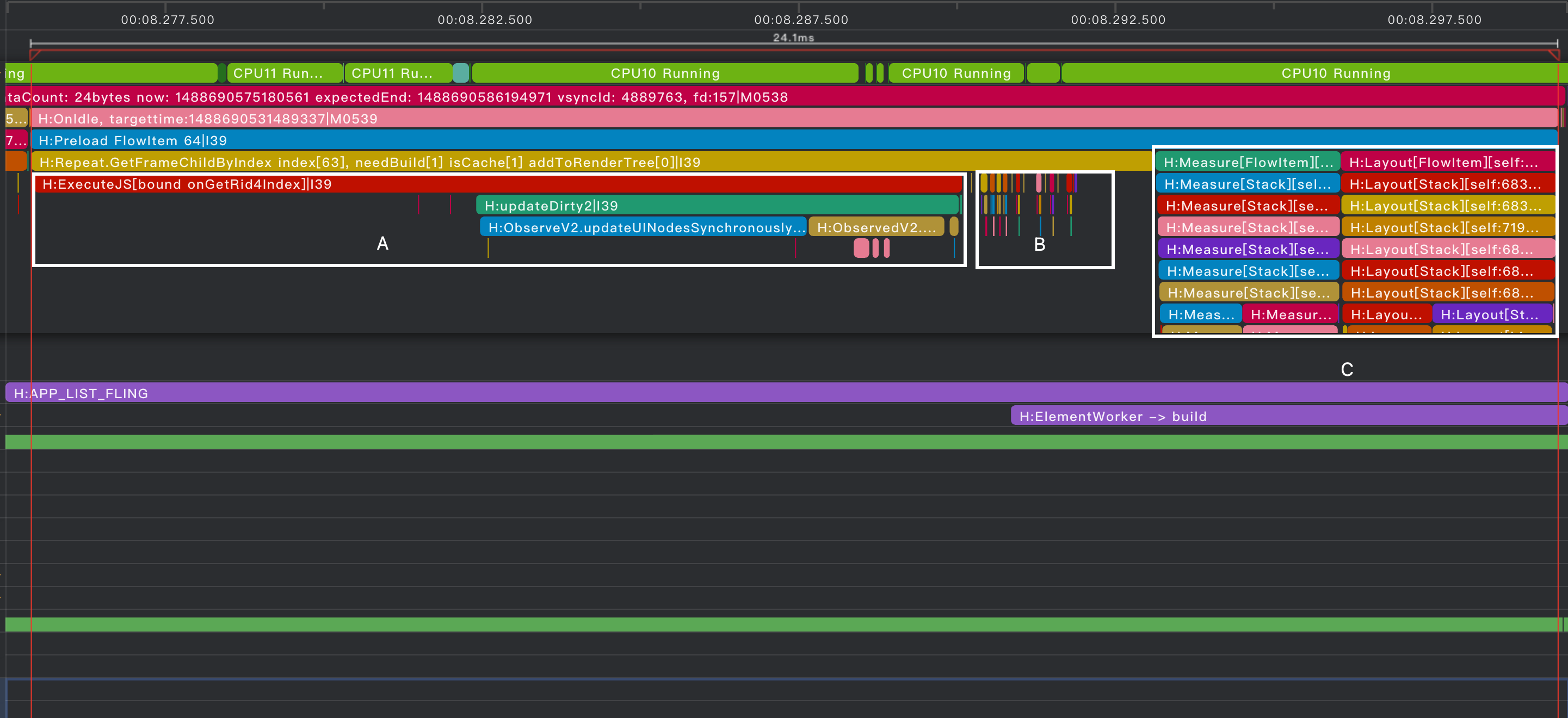
瓶颈定位
阶段1:FlowItem预加载耗时24ms,各区分别耗时A 15ms、B 3ms、C 6ms
A区 Repeat组件从复用池获取可复用组件更新数据,导致组件内部状态变更并触发依赖变更。
B区 图片组件创建图片并加载图片内容。
C区 卡片内所有节点进行测量布局。
阶段4:命令消费主要集中在Image / Text节点的创建和属性设置
阶段5:卡片节点中存在大量Stack / Image / Text节点,递归测量布局开销巨大
核心问题归纳:
1.冗余测量布局:FlowItem 预加载时已进行一次旧内容测量render 线程完成 yoga 测量后,系统在 OnVSync 再次全量测量。
2.Repeat复用:复用链路分散在多阶段,单次耗时虽不长,但累积效应明显需结合鸿蒙系统源码进一步拆解。
方案一:节点树静态布局&拦截系统测量布局
设计思路
利用 render 线程已完成的 yoga 测量结果,直接作为最终布局依据,跳过主线程 OnVSync 阶段的重复测量。
关键技术点
- CustomNode 自定义
OnMeasure/OnLayout,拦截系统对 CAPI Node Tree 的递归测量 - 使用
NODE_LAYOUT_RECT一次性设置四边位置与尺寸
实施步骤
1. 替换布局属性设置方式
设置Node Tree所有节点top、left、width、height时,由NODE_WIDTH、NODE_HEIGHT、NODE_POSITION改成NODE_LAYOUT_RECT
ArkUI_NumberValue number[] = {0.0, 0.0,0.0, 0.0};
ArkUI_AttributeItem item = {number, 4};
number[0].i32 = (int32_t)std::floor(vp2PX(left));
number[1].i32 = (int32_t)std::floor(vp2PX(top));
number[2].i32 = (int32_t)std::floor(vp2PX(width));
number[3].i32 = (int32_t)std::floor(vp2PX(height));
ArkUI_NativeNodeAPI_1::Instance().setAttribute(nodeHandle, NODE_LAYOUT_RECT, &item);2. 根节点升级为 CustomNode 并注册拦截
CAPI创建Node Tree的根节点StackNode替换成CustomNode,注册自定义测量布局函数,拦截系统对NodeTree的递归测量布局
// 注册自定义事件监听接口
void CustomNode::EnableLayoutInterception() {
ArkUI_NativeNodeAPI_1::Instance().addNodeCustomEventReceiver(nodeHandle, OnStaticCustomEvent);
ArkUI_NativeNodeAPI_1::Instance().registerNodeCustomEvent(nodeHandle, ARKUI_NODE_CUSTOM_EVENT_ON_MEASURE, 0, this);
ArkUI_NativeNodeAPI_1::Instance().registerNodeCustomEvent(nodeHandle, ARKUI_NODE_CUSTOM_EVENT_ON_LAYOUT, 0, this);
}
// 移除自定义事件监听接口
void CustomNode::DisableLayoutInterception() {
ArkUI_NativeNodeAPI_1::Instance().removeNodeCustomEventReceiver(nodeHandle, OnStaticCustomEvent);
ArkUI_NativeNodeAPI_1::Instance().unregisterNodeCustomEvent(nodeHandle, ARKUI_NODE_CUSTOM_EVENT_ON_MEASURE);
ArkUI_NativeNodeAPI_1::Instance().unregisterNodeCustomEvent(nodeHandle, ARKUI_NODE_CUSTOM_EVENT_ON_LAYOUT);
}
// 系统测量布局事件处理
void CustomNode::OnStaticCustomEvent(ArkUI_NodeCustomEvent *event) {
auto customNode = (CustomNode *) OH_ArkUI_NodeCustomEvent_GetUserData(event);
auto type = OH_ArkUI_NodeCustomEvent_GetEventType(event);
switch (type) {
case ARKUI_NODE_CUSTOM_EVENT_ON_MEASURE:
customNode->OnMeasure(event);
break;
case ARKUI_NODE_CUSTOM_EVENT_ON_LAYOUT:
customNode->OnLayout(event);
break;
default:
break;
}
}
// 自定义测量
void CustomNode::OnMeasure(ArkUI_NodeCustomEvent *event) {
const ArkUI_AttributeItem *item = ArkUI_NativeNodeAPI_1::Instance().getAttribute(nodeHandle, NODE_LAYOUT_RECT);
ArkUI_NativeNodeAPI_1::Instance().setMeasuredSize(nodeHandle, item->value[2].i32, item->value[3].i32);
}
// 自定义布局
void CustomNode::OnLayout(ArkUI_NodeCustomEvent *event) { }优化机制:CustomNode自定义测量布局函数,拦截了系统对CAPI创建NodeTree的递归测量布局;设置节点的NODE_LAYOUT_RECT可以直接用于后续的绘制渲染。
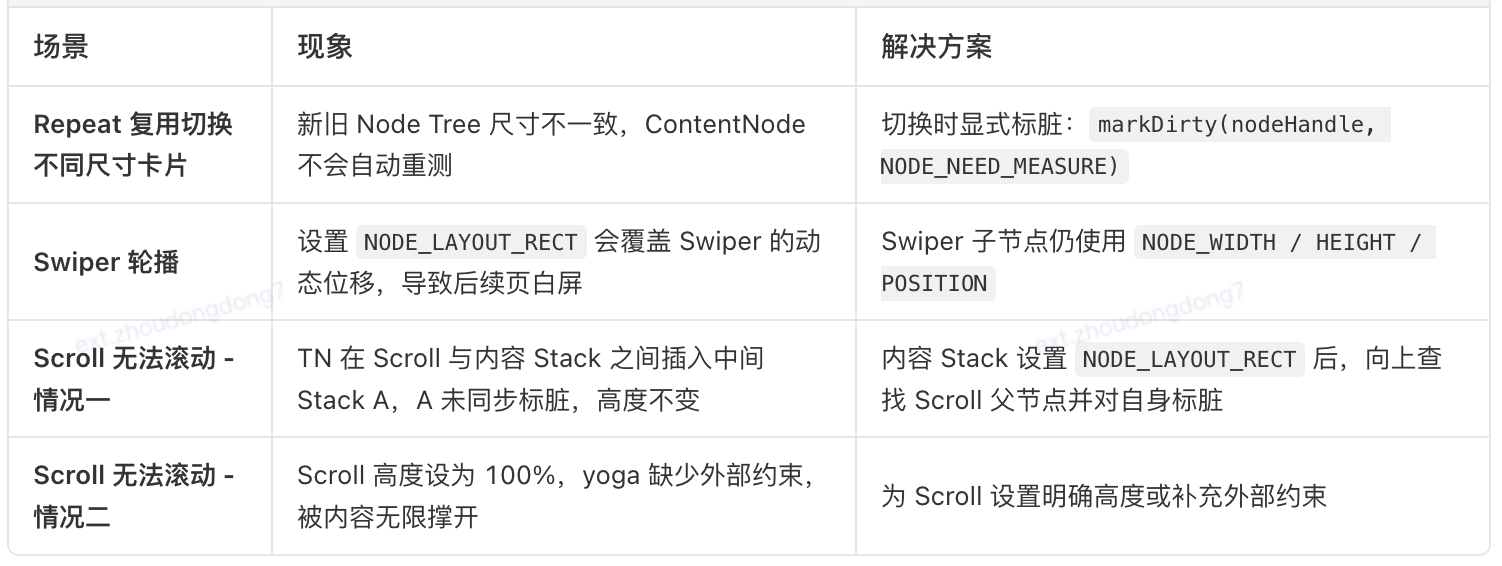
边界场景与应对
优化效果
- 预加载阶段 C 区(文本测量布局)显著缩短
- 鸿蒙低端机平均帧率:43 fps → 57 fps,提升 ≈32.5%
方案二:复用字体测量布局缓存
原文本测量布局瓶颈分析
经过方案一优化后,系统仍会在主线程执行文本测量布局。我们梳理了文本节点的创建与属性设置流程,发现文本测量依赖于 ArkGraphics 2D 自研文本引擎〔1〕,用于处理复杂文本显示场景。该测量过程目前分布在两个阶段:

优化策略:文本测量前置化与结果缓存
将文本测量完全前移至 render 线程,并在该阶段缓存 ArkUI_StyledString 结果;主线程仅消费缓存值,不再重复测量。
实施步骤
1. Render 线程测量并缓存 StyledString
TextStyledString measureTextWithStyledString1(MeasureInfo measureInfo) {
// 1.创建 TextStyle:设置FontSize、FontHeight、FontWeight、Overflow、FontFamilies、FontStyle、Color、Decoration
OH_Drawing_TextStyle* textStyle = OH_Drawing_CreateTextStyle();
// 2.创建 TypographyStyle:设置MaxLines、ellipsis overflow、TEXT_ALIGN
OH_Drawing_TypographyStyle* typographyStyle = OH_Drawing_CreateTypographyStyle();
// 创建 StyledString
OH_Drawing_FontCollection* fontCollection = GetFontCollection();
ArkUI_StyledString* styledString = OH_ArkUI_StyledString_Create(typographyStyle, fontCollection);
// 添加文本
OH_ArkUI_StyledString_PushTextStyle(styledString, textStyle);
OH_ArkUI_StyledString_AddText(styledString, measureInfo.text.c_str());
OH_ArkUI_StyledString_PopTextStyle(styledString);
// TextStyle 在添加文本后不再需要,直接销毁
OH_Drawing_DestroyTextStyle(textStyle);
// 创建 Typography 并布局
OH_Drawing_Typography* typography = OH_ArkUI_StyledString_CreateTypography(styledString);
OH_Drawing_TypographyLayout(typography, vp2Px(measureInfo.maxWidth));
// 获取测量结果
size_t lineCount = OH_Drawing_TypographyGetLineCount(typography);
double height = px2Vp(OH_Drawing_TypographyGetHeight(typography));
double width = px2Vp(ceil(OH_Drawing_TypographyGetLongestLine(typography)));
// 返回字体styledString
return TextStyledString(typographyStyle, typography, styledString);
}2. 主线程直接应用缓存
if (cachedStyledString_.IsValid()) {
ArkUI_NativeNodeAPI_1::Instance().resetAttribute(nodeHandle, NODE_TEXT_CONTENT_WITH_STYLED_STRING);
ArkUI_AttributeItem content = { .object = static_cast<void*>(cachedStyledString_.GetStyledString()) };
ArkUI_NativeNodeAPI_1::Instance().setAttribute(nodeHandle, NODE_TEXT_CONTENT_WITH_STYLED_STRING, &content);
}收益评估
- 主线程耗时降低:≈ 4 ms+
- 线程负载均衡:减轻主线程压力,提升帧稳定性
- 一致性保障:同一文本仅测量一次,避免多线程结果差异
总结与沉淀
方法论沉淀
本次实践形成了一套适用于 类 RN 架构 的通用提速范式——《类 RN 静态布局直渲提速》:
- 前置测量:在 render 线程完成布局计算
- 结果直通:通过
NODE_LAYOUT_RECT将尺寸与位置一次性注入节点 - 拦截去重:借助 CustomNode 拦截系统重复测量
- 资源复用:对文本等资源建立跨线程缓存
该方法可横向迁移至其他产品的同构框架,显著提升低端设备渲染性能。
致谢
特别感谢 华为 2012 鸿蒙突击队 在本次问题联合攻关中的深度支持与协同分析。






