



后端研发的 AI 突围
作为一名后端研发,开始AI之路已经2年,从Chat QA,到AI Agent的开发,在到Multi-Agent,AI-Native。
今年Q2开始结合保险业务场景,开始全面AI落地。我们的AI Agent的能力已跨过L1(Chatbot),在L2(Reasoner)全面爆发。
我内心是焦虑的,大模型发展的得太快,尤其是在Cursor、JoyCode等产品出来后。我想不止是后端研发,所有的业务研发都会焦虑,因为现在风口不在卷微服务、微前端的架构,全都开始卷AI了。 除了AI Infra外,模型开发也一样焦虑吧,单一的Agent也已是过去式。
我的解药是把微服务架构应用到AI上,什么Agent、Planning、RAG、Evaluation、MCP、LLM、Prompt、Memory、MultiModal都安排起来。
保险Eva的RAG架构经历了三个阶段,从基础RAG到Deepsearch,在到混合式检索架构(Graph RAG + DeepSearch + 持续的反思与验证 )
RAG架构
历史:
首先我们回顾下什么是RAG?RAG(Retrieval-Augmented Generation - 检索增强生成 )是一种构建基于大模型(LLM)应用的创新技术,通过利用外部知识源为LLM提供相关上下文,从而减少幻觉现象,提高生成内容的准确性和可靠性。最早要追溯到2020年,是由Facebook AI Research(Meta AI)提出的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》
基础 RAG 架构,朴素的知识管理员
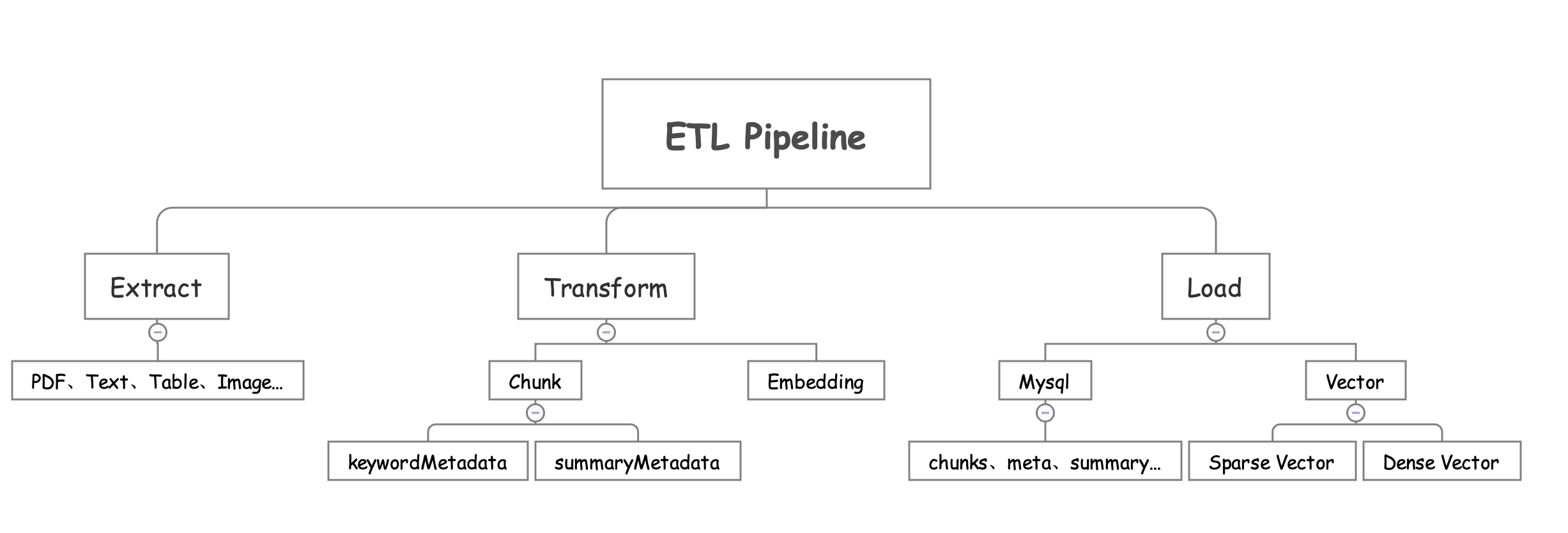
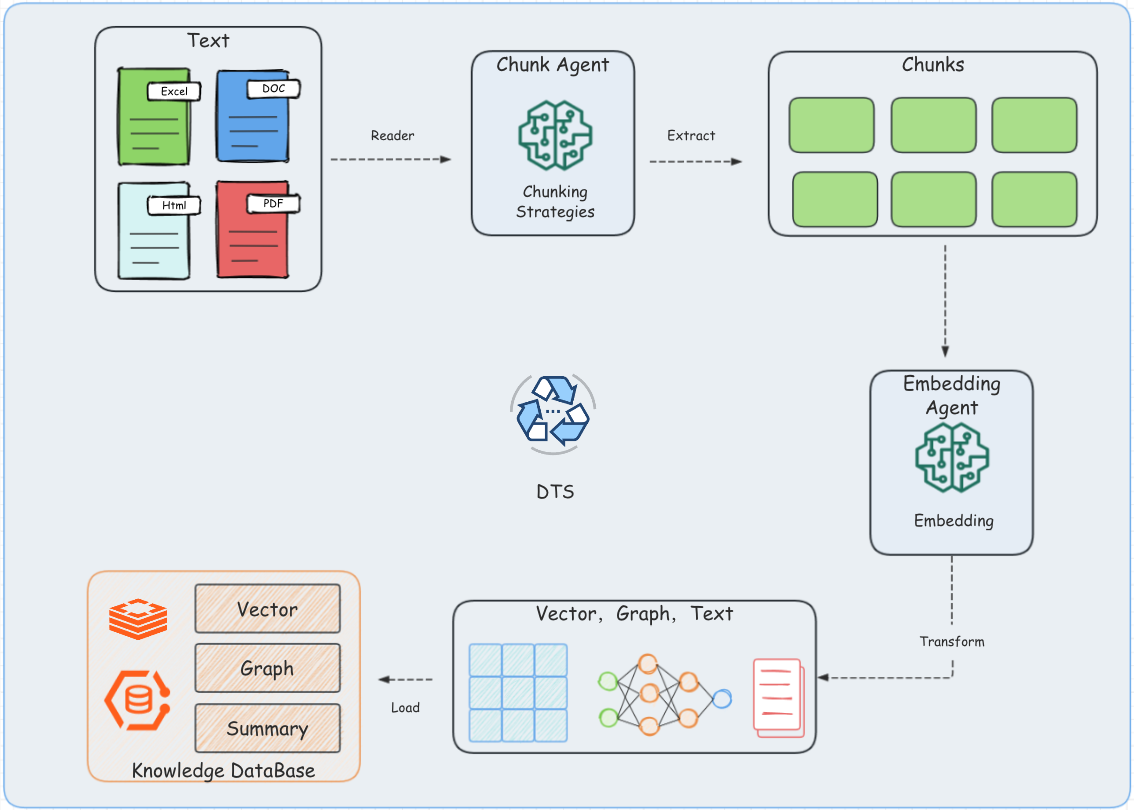
基础 RAG 是所有RAG范式的基础,包括DeepResearch、Agentic RAG、Graph RAG都是在基础RAG上进化出来的。所以我们先熟悉下基础RAG的架构,它包含两个核心组件:生成组件(ETL Pipeline)和检索组件(Retrieval)引入下图为例:
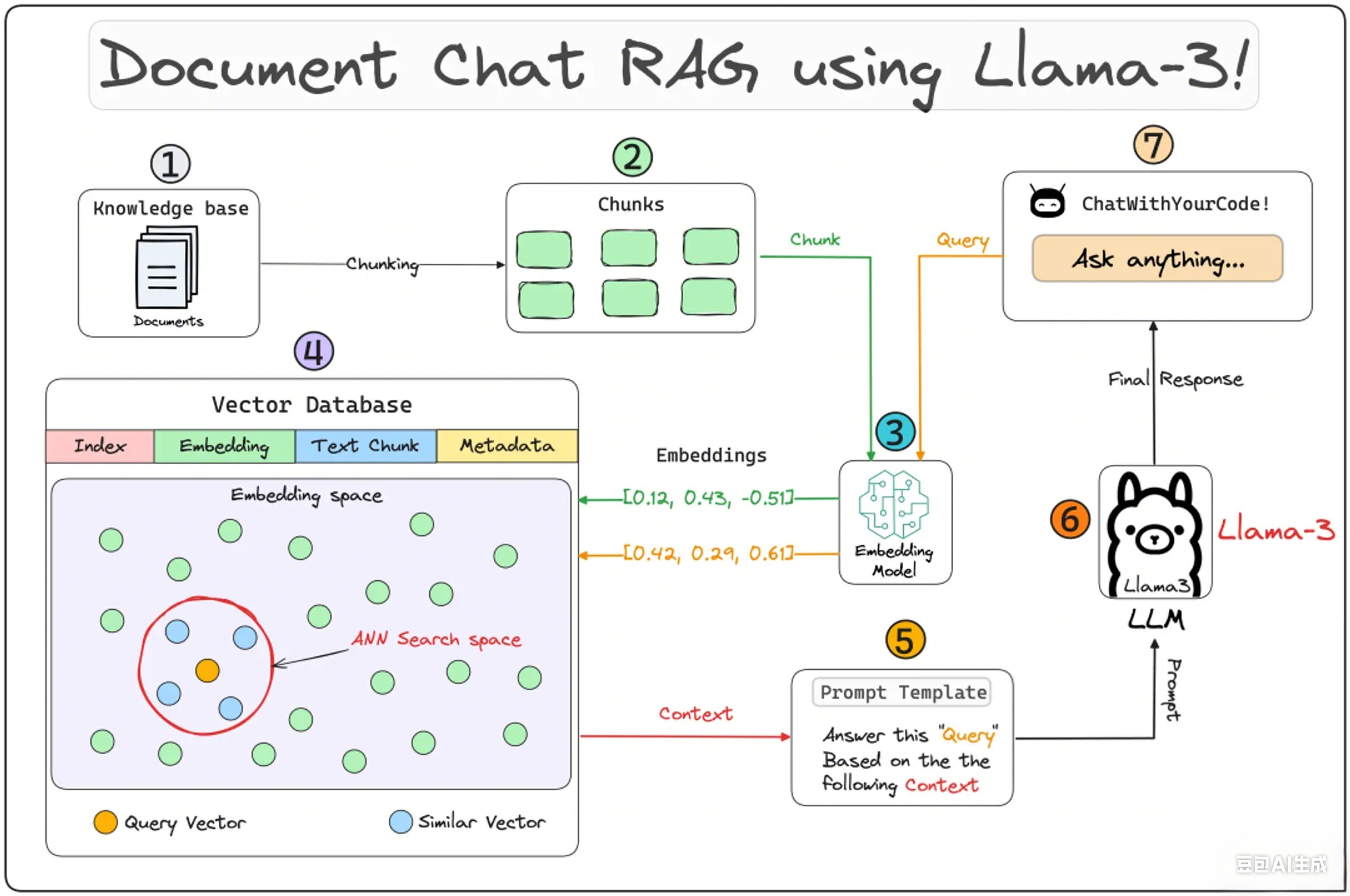
①,②,③,④步骤都是生成组件,它的核心就是文件提取、转换、加载,我们来一步步分析。
- 文件提取(Extract):核心文件读取器,常用的有doc、pdf、excel、图片等文件,需要关注对中文支持和Execl单元格的处理。
- 文件转换(Transform):文件转换的核心有两个
chunk和embedding。
chunk阶段尤为关键是所有RAG范式的核心,就像切蛋糕一样,切之前就已分配好:
常用的分块策略有五种:固定大小分块,语义分块、递归分块,基于文档结构分块,基于大模型分块。

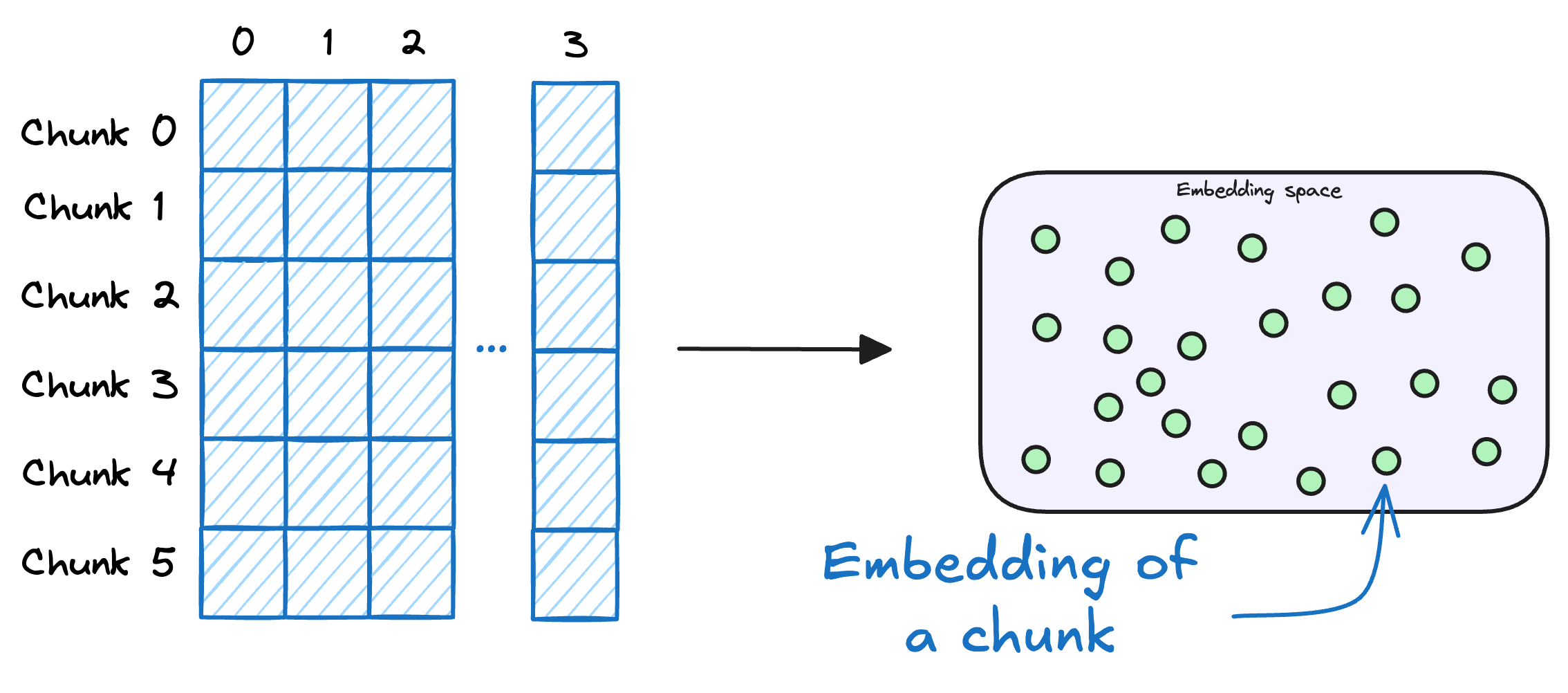
embedding:向量化,向量是为了满足相似性查找的需求,比如表达“今天天气如何?”这类的询问方式有很多,这时我们需要将文本向量化,存入到向量库中:
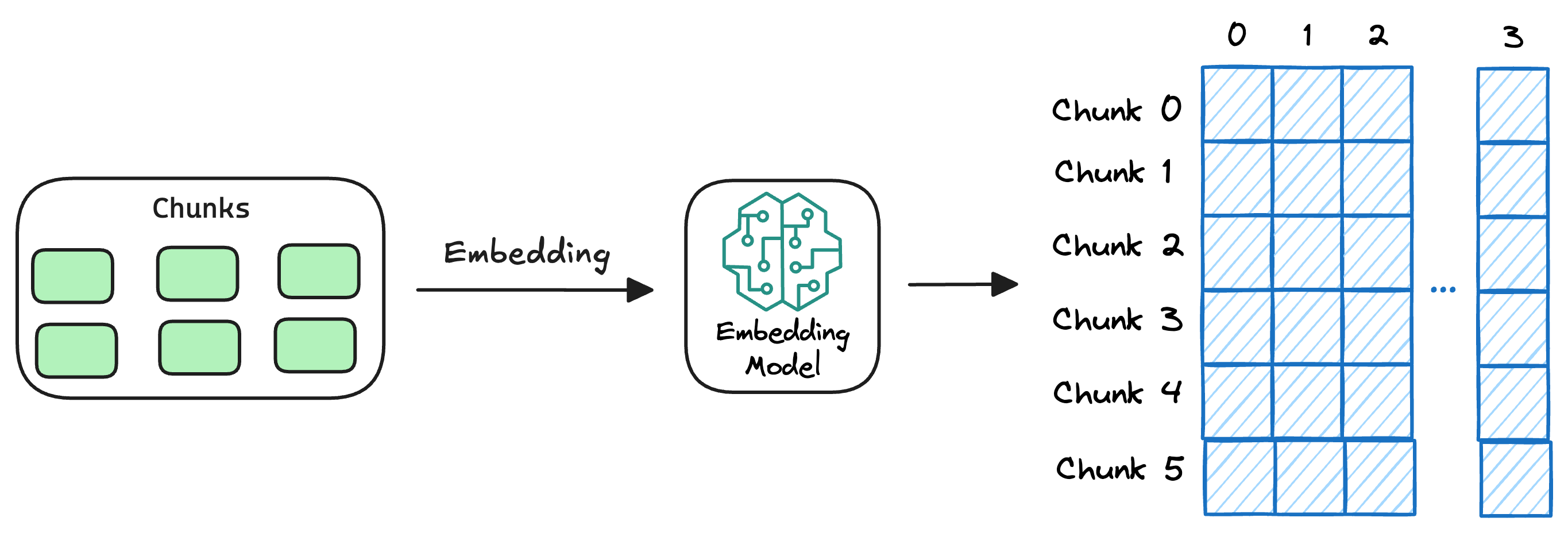
数据加载(Load):数据存储,我们用的Elasticsearch8+(ES)进行混合存储,当然也可以其他向量库和关系型数据库来存储。
⑦,③,④,⑤,⑥步骤是检索组件,它分为预处理、检索、后处理
预处理核心是Query:要不要做Query的扩充?扩充多少?带不带原始Query?需不需要对Query转译?预处理偏向于业务处理,根据需求来,相当于基础RAG的一扩展特性,Agentic RAG范式沿用了这一特性。
检索的核心是算法:基础的检索算法“稀疏算法和稠密算法”
| 稀疏算法可以利用LLM提取关键词,embedding维度设为整个表中所有的关键词的维度,维度上的值是关键词在当前文本块中的TF-IDF值。当用户查询时,系统会将其转化为一个类似的TF-IDF向量,通过计算用户查询向量和所有文本块向量之间的cosine,找到得分最高或最相似的向量块。 | 稠密算法常用的是BM25,用户输入查询时,系统会使用LLM将查询转化为一个embedding向量,然后在向量数据库中进行cosine计算,找到最相似的向量块。 |
1. 第③步中用相同的嵌入文本块模型,向量化用户的查询
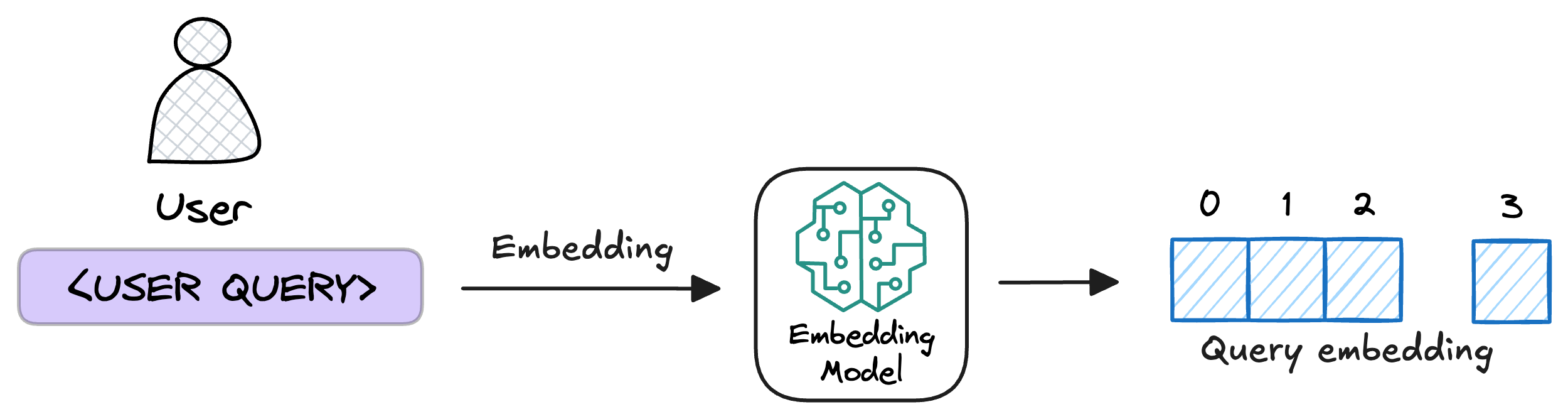
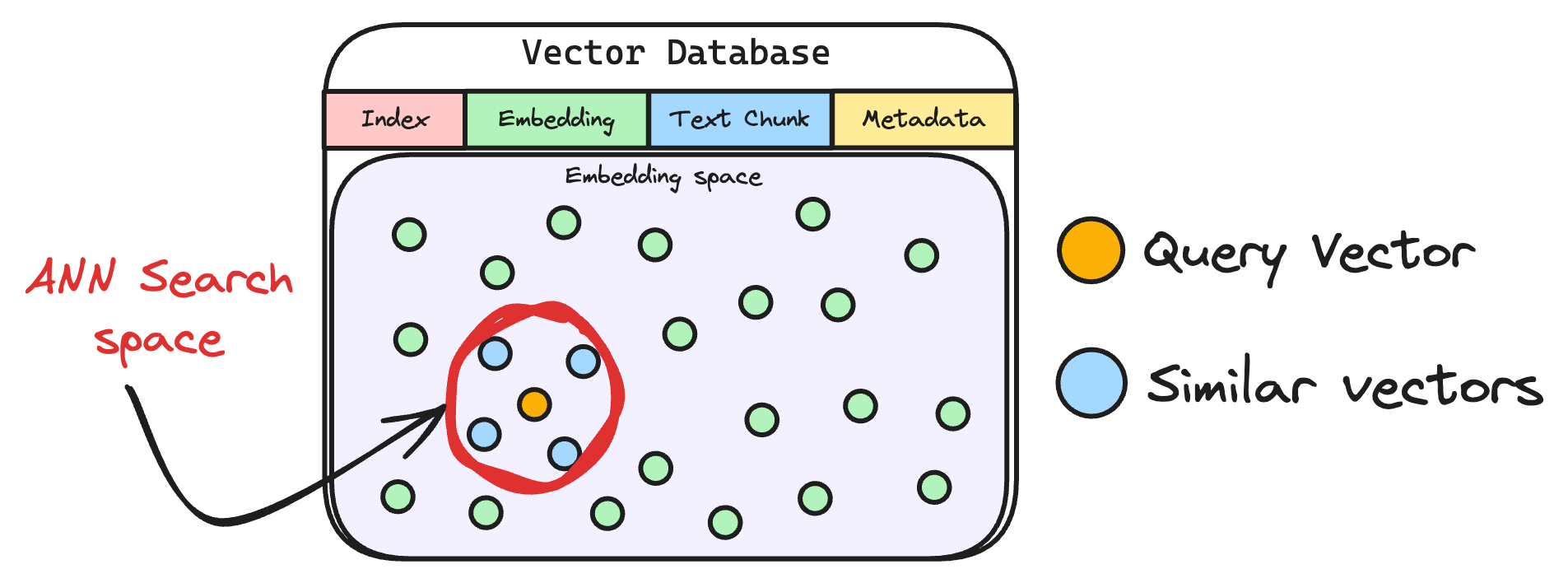
2. 然后,将向量化的查询与数据库中现有的向量进行比较,以找到最相似的信息。常规的向量检索ANN算法,我们还支kNN算法,向量库的表结构的基础字段索引,向量块,原始文本块,原数据字段。
3. TopK,通过预设的k阈值,我们只获取最相似的k条原始文本块返回,这是rank的流程。
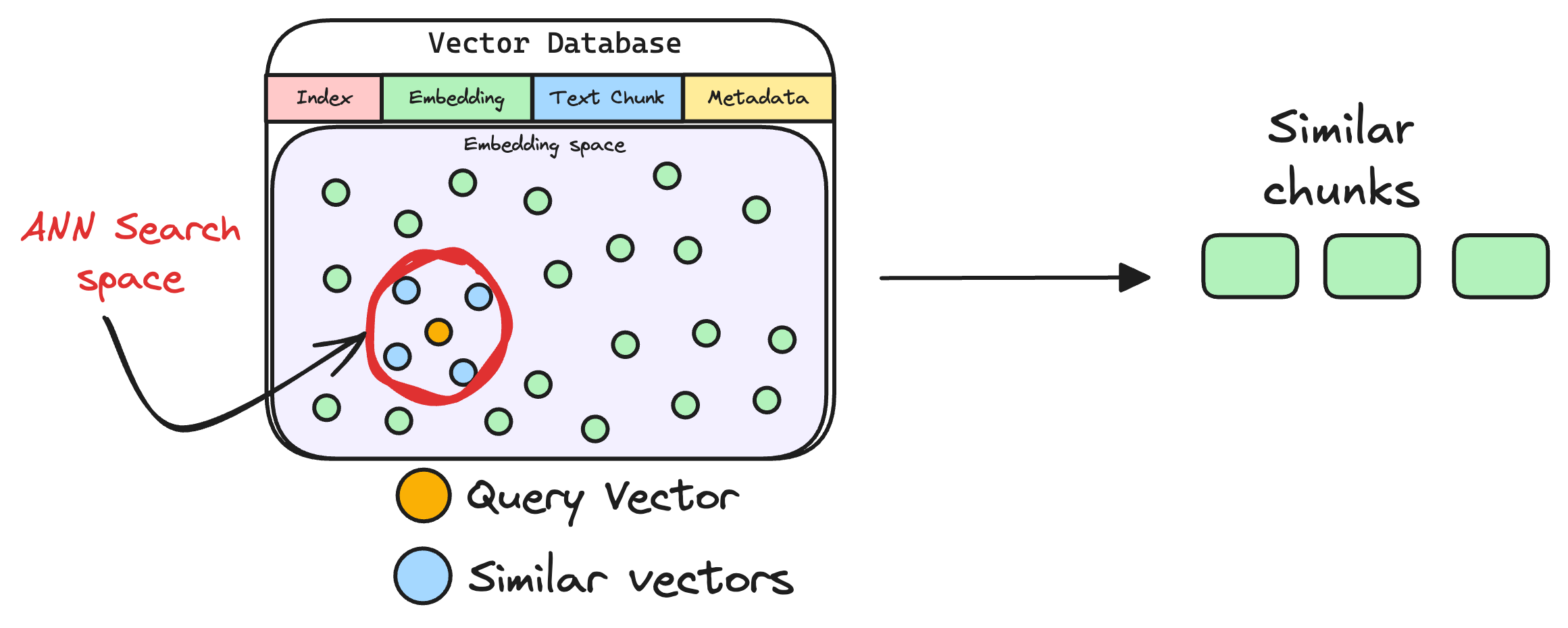
后处理的核心是排序:在精排(Rerank)也就是二段检索,之后会进行文本拼接,把结果拼接到上下文中生成Prompt,最后由LLM生成最终答案(Generate)。
Rerank不是一个必选项,Rerank模型会结合查询对检索到的初始文本块列表进行评估,为每个文本块分配一个相关性分数。这一过程会重新排序。
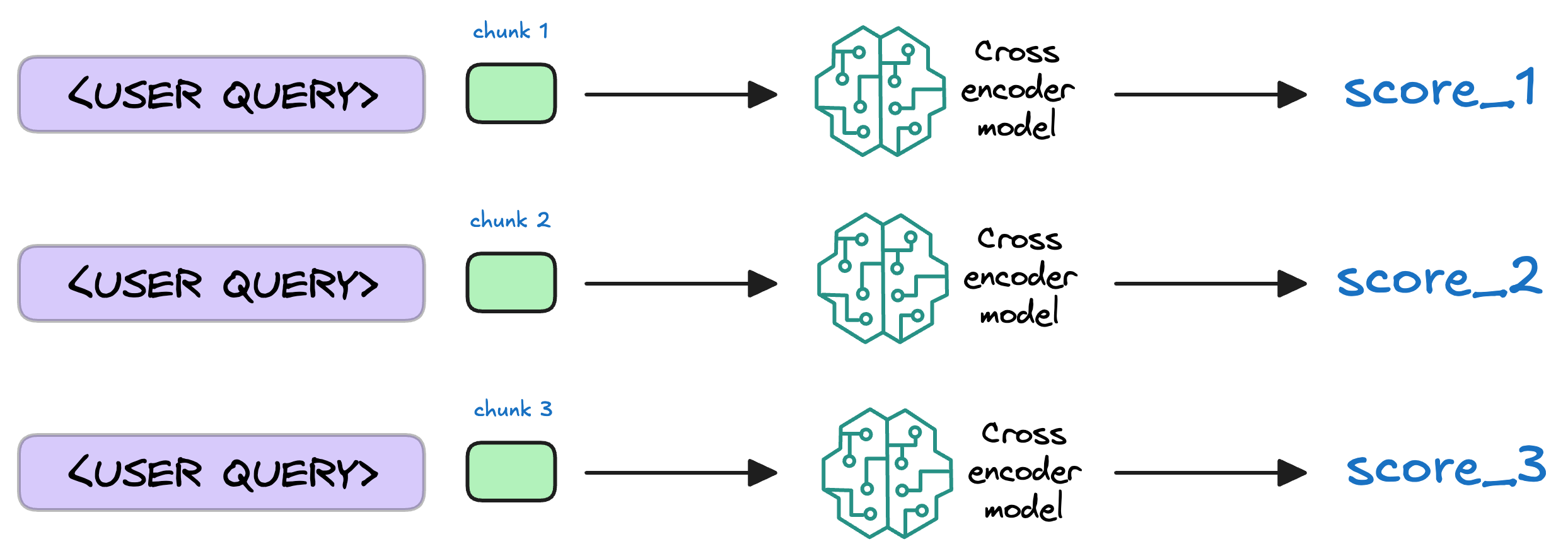
最后一步是生成结果,将原始的查询和检索到的文本块,拼接到Prompt中,由大模型生成最终的结果。
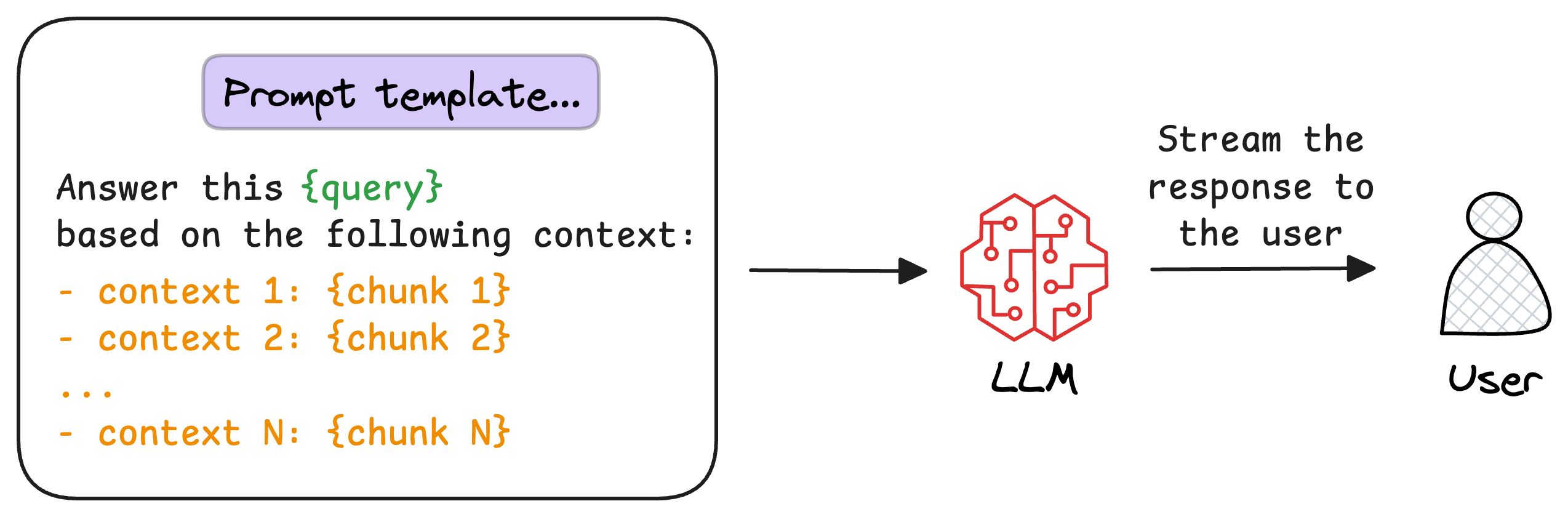
以上是基础RAG的全流程和技术细节点。从原理上看搭建一套基础RAG框架是容易的,但实际上从业务角度出发,搭建一套高性能的框架是完全不同的挑战。
倒退到2022年,基础的RAG方案是很OK的。随之模型发展到现在的Agentic Agent,需要解决的往往是对复杂问题的深度检索,基础的RAG这时显得非常的无力,但也促使RAG演进了新的范式:Graph RAG,Agentic RAG,DeepResearch
我们的RAG架构
我们的RAG产品架构上包含了“保险知识库+记忆库+文件库+智能体+搜索+测评”,是技术驱动由算法,工程,数据一起完成的。
算法AgenticRAG:我们学习了通义DeepResearch的开源WebWeaver架构,微软的开源GraphRAG,结合现在火热的ZEP、REFRAG的论文
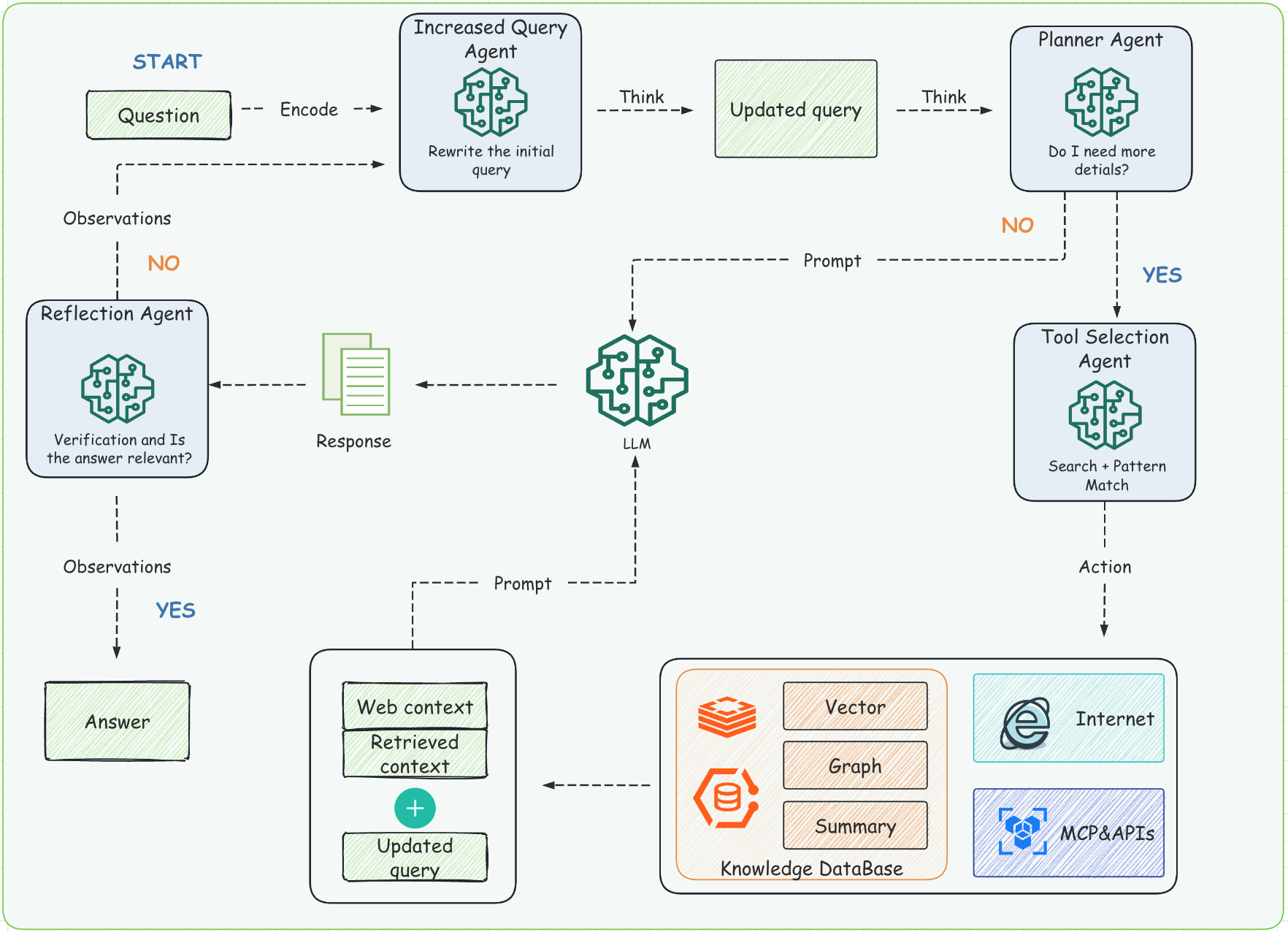
架构上实现了混合式检索“Agentic RAG+DeepResearch”,记忆实现了“情景记忆+程序记忆+语义记忆+时间记忆”,RAG智能体矩阵实现了“RAG查询增强智能体,规划师智能体,工具选择器智能体,反思和验证智能体,基于图结构的智能体,深度研究型智能体”。
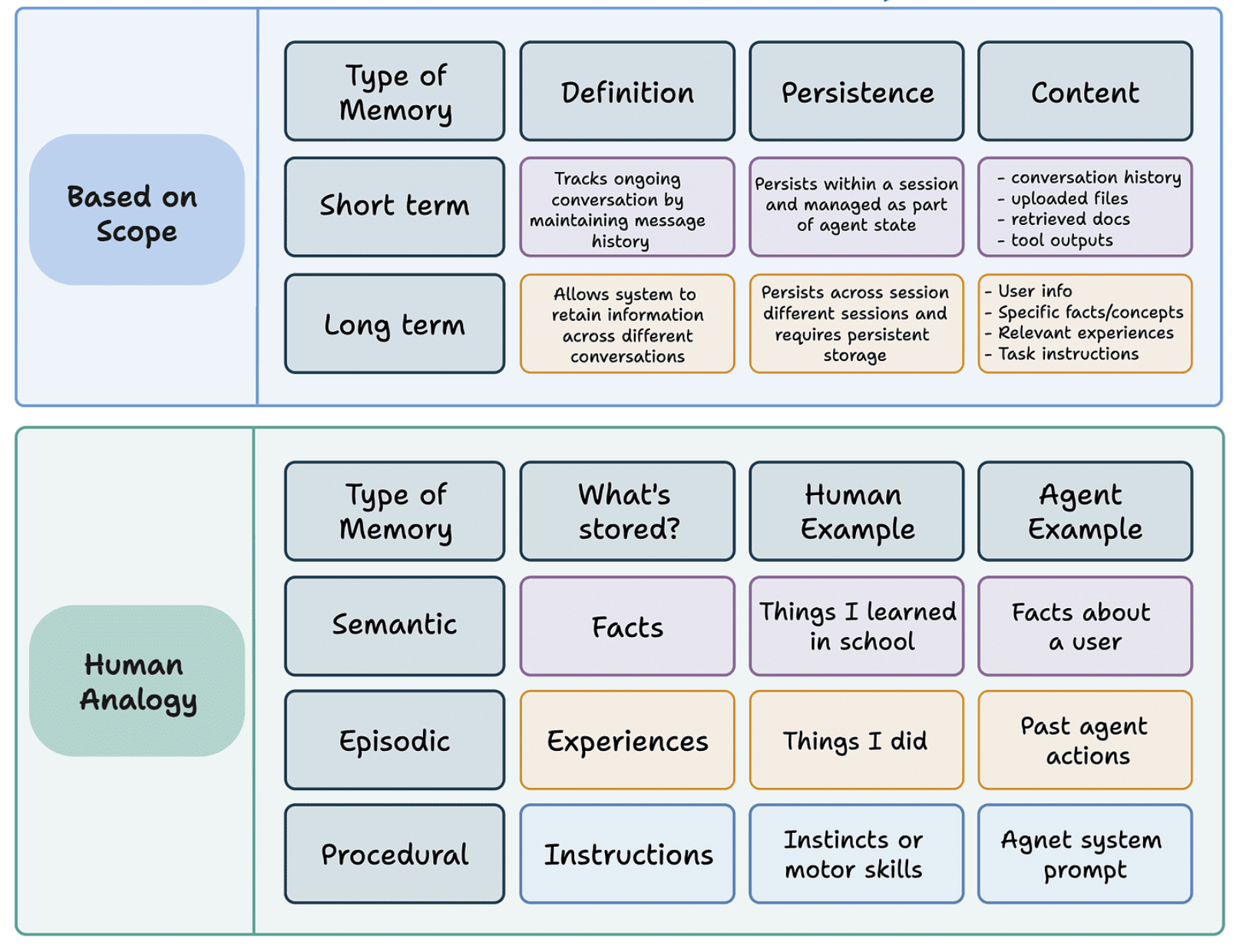
记忆设计:语义记忆图谱,程序记忆图谱,情景记忆图谱
工程RAG平台:承上启下串联全流程,承接业务Agent的检索、查询的需求,提供标准接口让Agent专注于模型训练迭代
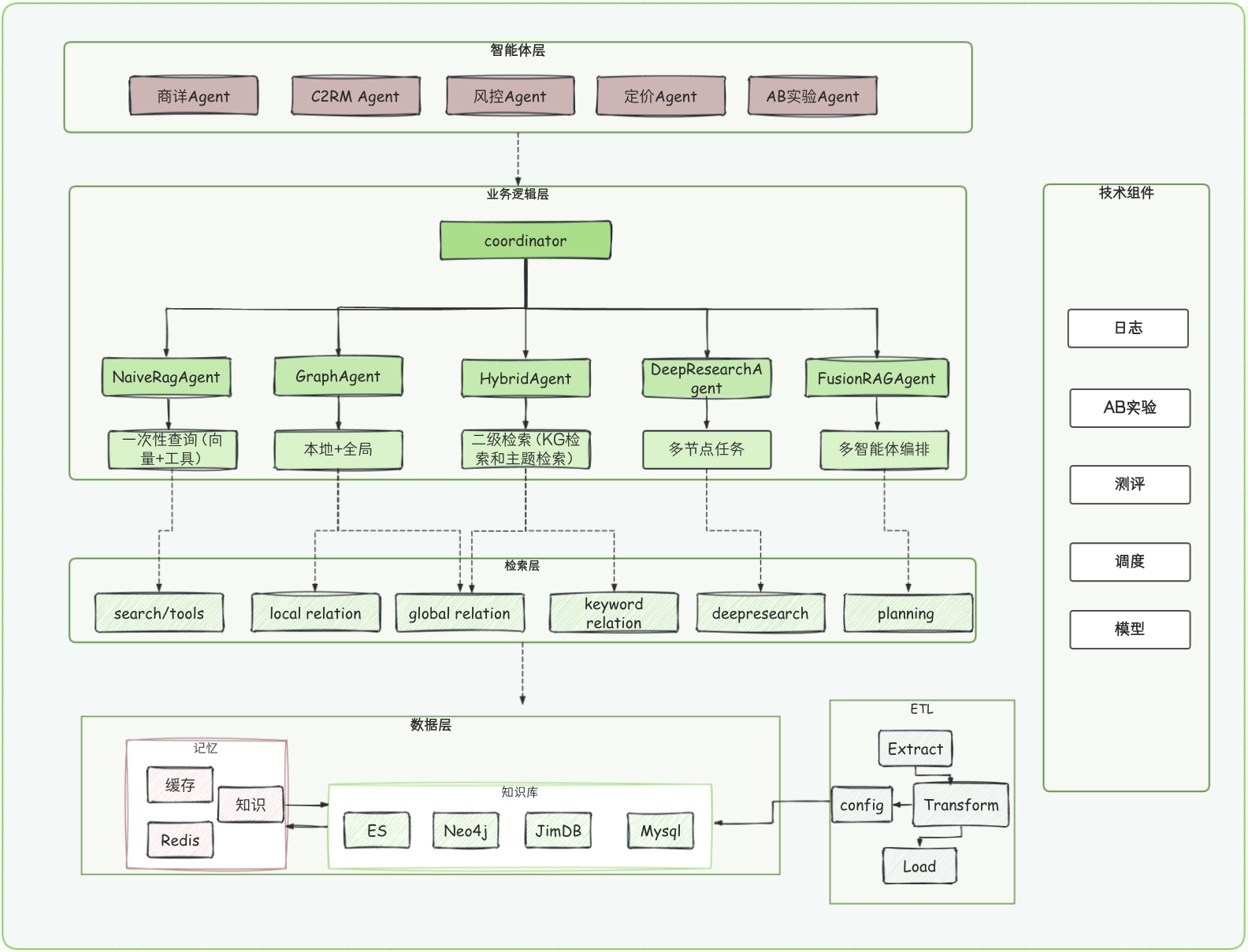
工程架构分了四层:智能体层,业务逻辑层,检索层,数据层;技术栈:Spring AI ,Elasticsearch8+,Neo4j,Redis,京东云;技术能力支持上支持Python Code和RAG Agent Workflow。
数据架构:保险知识库+记忆库+任务中心 组成三角矩阵
保险知识库架构:
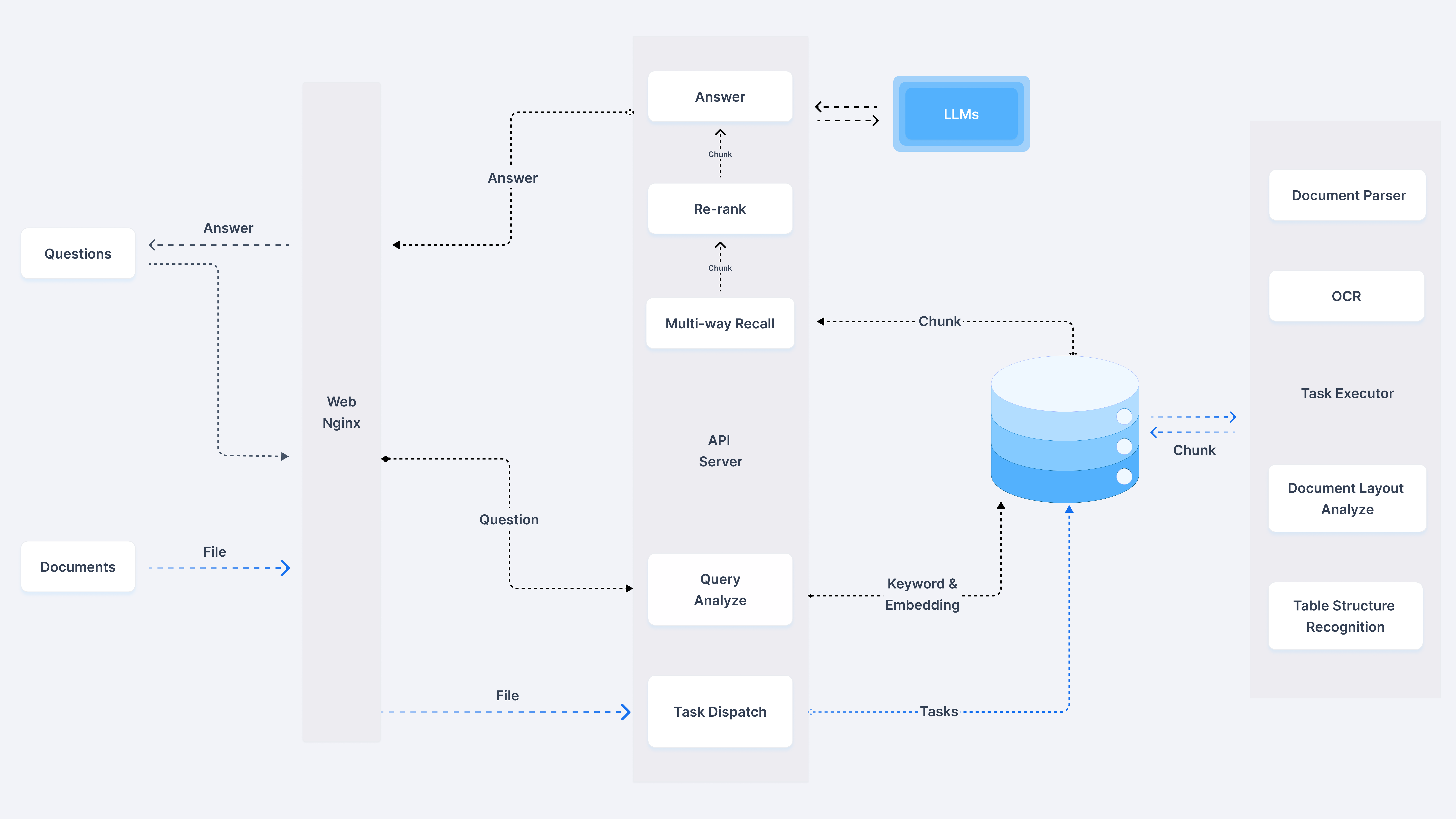
任务中心:
Chunck:学习Cognee参数调优的思想,提供了五种chunk策略。
记忆库:“语义记忆图谱,程序记忆图谱,情景记忆图谱”在此三类记忆上增加双时间字段,保证记忆的时效性。
为什么这样设计?
我们团队核心是一套由多智能体驱动业务的平台(Eva)。
- 我们是需要RAG是因为保险业务,保司的很多数据是网上没有的,并且内容很多,上百页甚至大几百页的文档比比皆是。
- 我们是ToB业务,是围绕业务发展的Agent,直面经营结果(规模/利润)。
- 我们的RAG平台隶属于Eva基础能力之一。
未来的RAG
不再过多揣测未来,乘风破浪即可。
- Agentic RAG里面包含了Deepsearch,Graph RAG,基础RAG,如果感兴趣我会像基础RAG一样,一层层剥开和大家交流。
- Python Code和RAG Agent Workflow是工程端的自研核心,如果感兴趣我会像基础RAG一样,一层层剥开和大家交流。
- 记忆库除了“语义记忆图谱,程序记忆图谱,情景记忆图谱”我们还在研发时间记忆图谱,如果感兴趣我会像基础RAG一样,一层层剥开和大家交流。
- Chunck绝对是核心,以至于让Cognee花了大半年时间在参数调优上,我们总结一份配置手册,如果感兴趣我会像基础RAG一样,一层层剥开和大家交流。
大家可以把感兴趣的留在评论区,也可以提出你们疑问想法,我们多交流。
团队核心成员
路遥、李睿琪、余洋、陈伟民、郭暾
参考
https://github.com/Alibaba-NLP/DeepResearch/blob/main/README.md
https://arxiv.org/pdf/2505.24478






