



数据库问题
案例1
这段 SQL 查询语句是用于获取最近更新的前 10 个销售订单 sales_order 关联的交付信息 sales_order_delivery_info。
SELECT
*
FROM
(
SELECT
*
FROM
sales_order a
WHERE
trans_type 订单交易类型 AND a.is_obsolete = '0'
ORDER BY
a.update_date DESC LIMIT 0,
10
)t
LEFT JOIN sales_order_delivery_info f ON t.order_id = f.sales_order_id order_id(订单ID) 和 sales_order_id(订单交付ID) 进行关联
ORDER BY
t.update_date DESC
a.trans_type = '0'
原始语句解析:
主要用于获取销售订单和相关的交付信息
#SELECT * FROM sales_order a WHERE a.trans_type = '0' AND a.is_obsolete = '0' ORDER BY a.update_date DESC LIMIT 0,10 在第一个子查询中,使用 WHERE 子句筛选条件来仅选择销售订单交易类型为0且未过时的记录。使用ORDER BY 子句和DESC关键字按更新日期降序排列,以确保最近的订单出现在顶部。LIMIT子句用于限制结果集大小,此处设置为仅显示前10个最近的订单。
# LEFT JOIN sales_order_delivery_info f ON t.order_id = f.sales_order_id
在主查询中,使用LEFT JOIN子句将销售订单子查询结果和sales_order_delivery_info表进行连接,使用ON子句指定连接条件,即在销售订单表和交付信息表之间使用销售订单ID进行连接。此查询将返回所有匹配的行,包括没有匹配的行。
#ORDER BY t.update_date DESC
最后,再次使用ORDER BY子句和DESC关键字按更新日期降序排列结果集。整个查询的结果将包括 sales_order 和sales_order_delivery_info 两个表的列,并将前10个最近的销售订单和相关的交付信息作为结果返回。问题分析:
mysql数据库版本: 8.0
问题前提条件: 单表有40多万数据
出现问题: sql执行 order By执行效率下降
常规思路: 优化全表扫描查询只查询相关字段优化子查询基于上面的问题向 GPT 进行提问
接下来的对话你将以一名数据库管理工程师的身份和我聊天
目前我们使用的数据库版本为 mysql 8.0 在单表中数据有40多万 sql语句在分页前进行order By 执行效率立刻下降 请根据上述的业务 sql 给出优化建议 具体 sql 如下:
SELECT
* FROM
( SELECT
* FROM
sales_order a
WHERE
a.trans_type = '0'
AND a.is_obsolete = '0'
ORDER BY
a.update_date DESC
LIMIT 0,
10
)t
LEFT JOIN sales_order_delivery_info f ON t.order_id = f.sales_order_id
ORDER BY
t.update_date DESC
我的业务要求 sql 语句查询高效并且支持高并发业务场景基于这个业务前提请再给我一份优化后的 sql 语句并详细解释一下优化后的 sql 语句
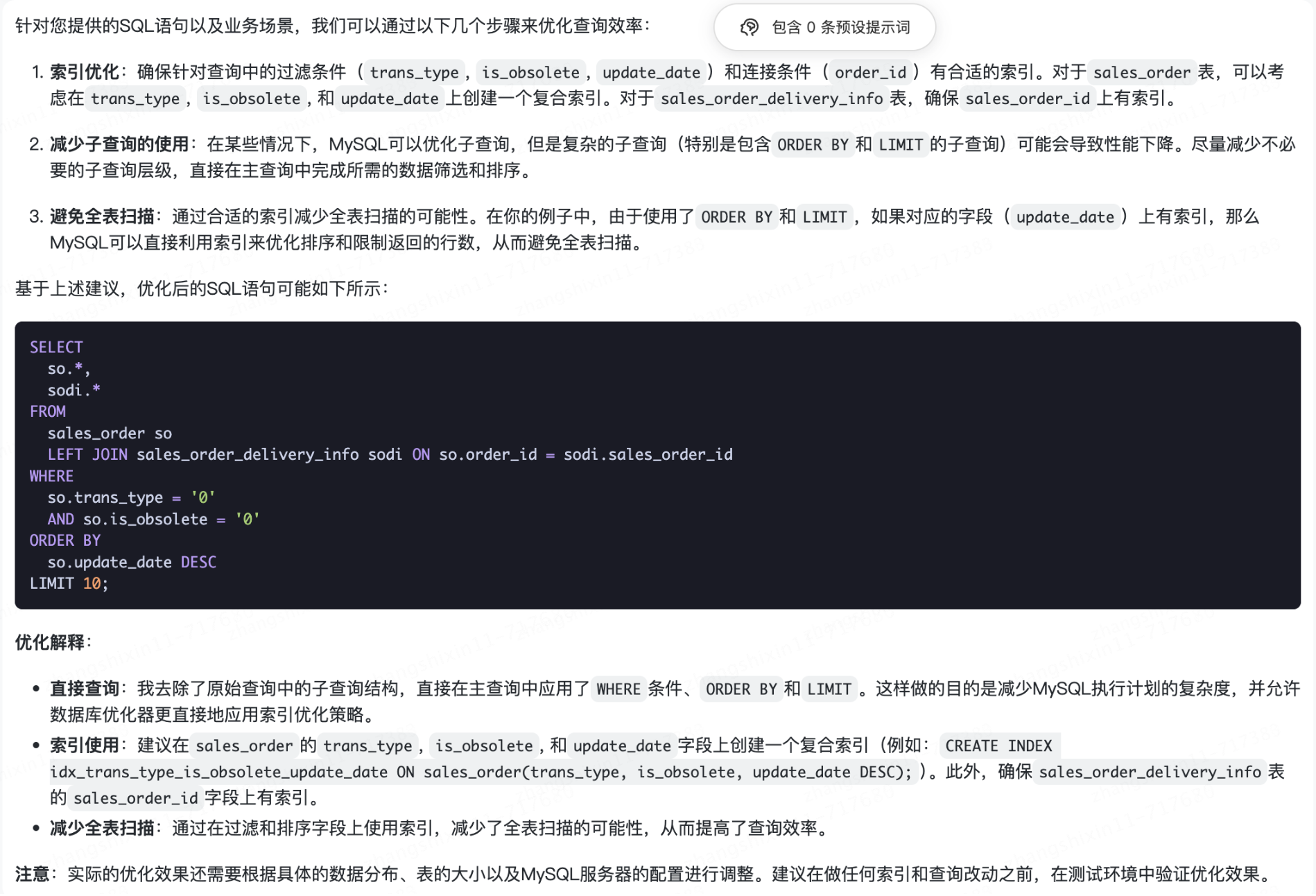
项目问题思路实现以及案例
案例一
项目中 一张客户表有 1 亿条记录,如果要删除其中的 10 万条记录能有什么处理方法和步骤
问题分析
mysql数据库版本: 8.0
问题前提条件:
表结构: 这个表包含了客户的基本信息,包括 ID、名字、邮箱、电话、地址、城市、省、邮政编码等。还有两个时间戳字段,用于记录该记录的创建时间和最后更新时间 出现问题: 要删除其中的10万条记录
常规思路: 根据条件进行执行删除分页基于上面的问题向GPT进行提问
接下来的对话你将以一名数据库管理工程师的身份和我聊天,我的数据库版本为 mysql8.0 在项目中一张客户表有1亿条记录,其中表包含了客户的基本信息,包括:ID、名字、邮箱、电话、地址、城市、省、邮政编码等。还有两个时间戳字段,用于记录该记录的创建时间和最后更新时间,要删除其中的符合条件10万条记录,请提供思路以及实现步骤,同时详细解释下为什么这样做
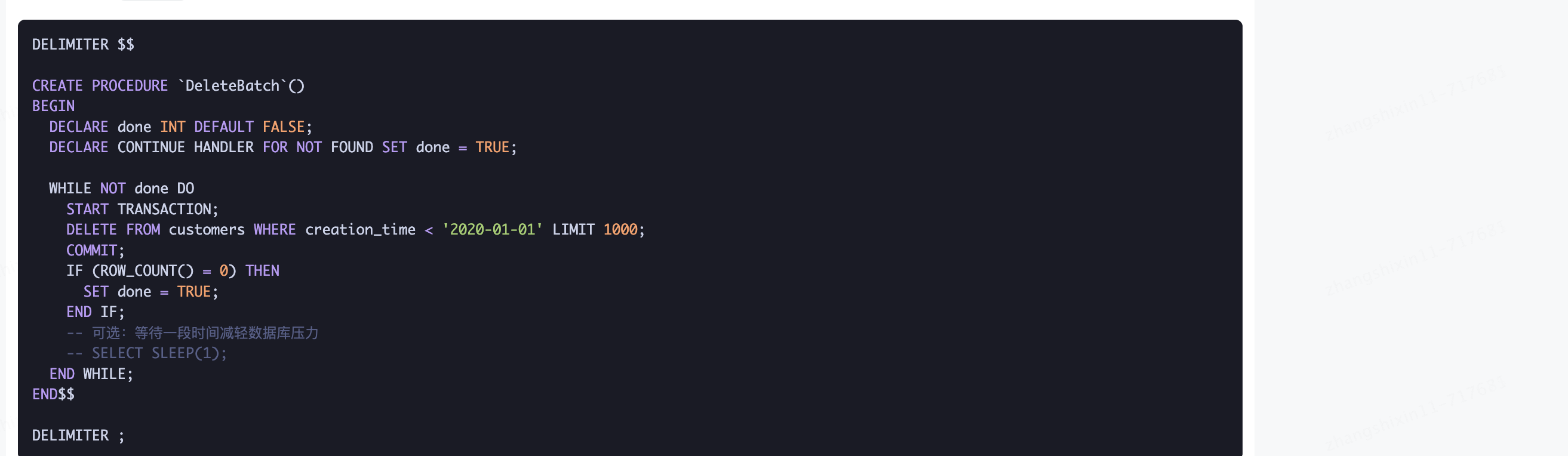

请在上述基础上进行性能优化 提供实现具体代码并详细阐述过程 在代码中要有详细注释

环境问题提问技巧
案例一
使用 docker 启动 redis,redis 再 docker 中的配置文件在哪?容器中 redis 的配置文件不能用默认的,所以想修改。
问题分析
环境记录 : centos 7.6.1
dokcer/redis版本: CE(社区版本最新的) /5.0.2
问题前置条件: 使用 docker 启动 redis
问题内容: redis 在 docker 中的配置文件在哪?
常规思路: 直接使用 -v 文件:docker目录(挂载名)进行目录挂载基于上面的问题向 GPT 进行提问
接下来的对话你将以一名运维工程师的身份和我聊天,我的环境系统环境 centos 7.6.1,系统中 docker 的版本是最新稳定版,docker 中部署的 redis 版本为 5.0.2,docker部署的 redis 默认配置文件在哪?请问如何修改以及如何将它挂载到本地文件。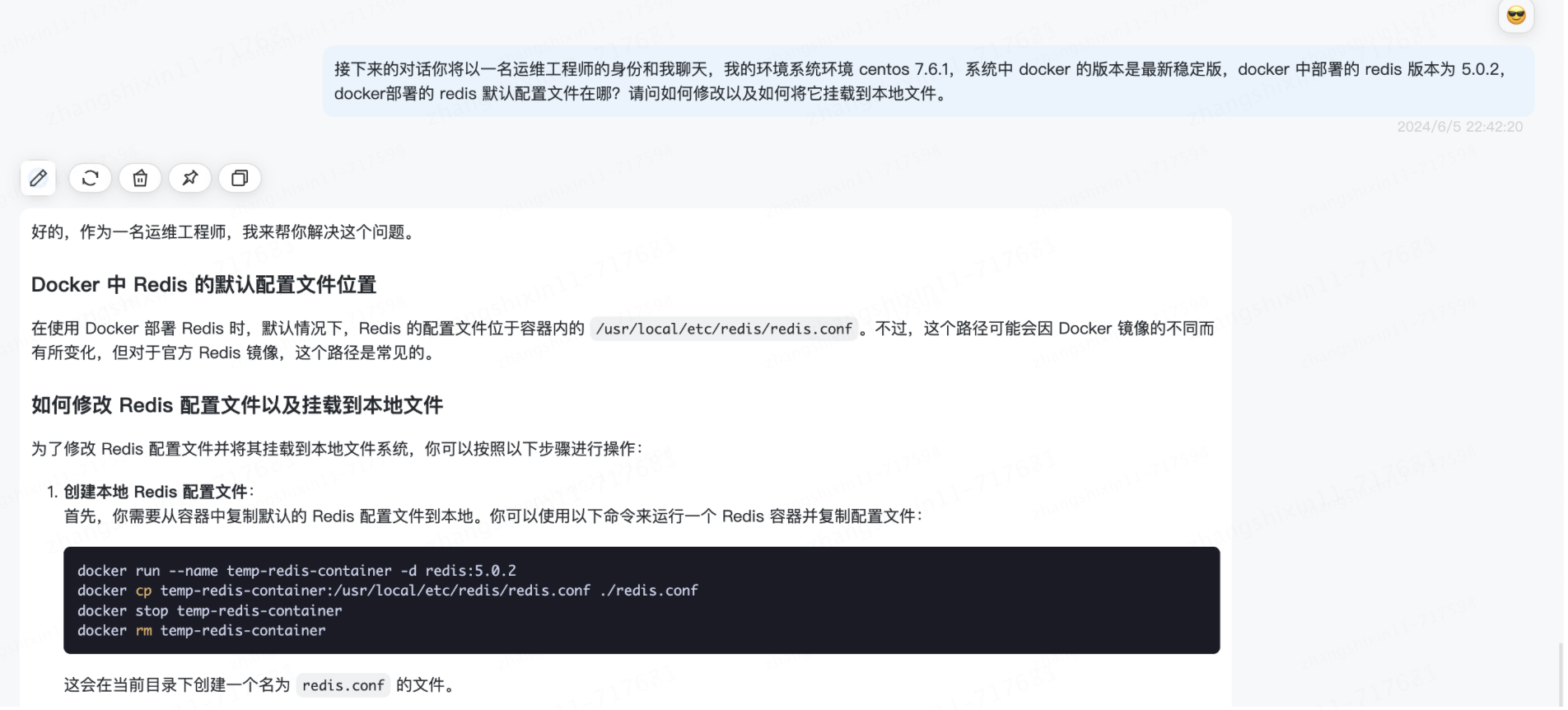

请详细解释每条命令的含义


GPT 辅助源码学习
在研究 nacos 源码时遇到的问题
对该方法不明白
grpcconn.setPayloadstreamobserver(payloadstream0bserver); 在 nacos 的源码中为什么这个 set 方法一调用就往服务端发一个请求。问题分析 :
nacos源码问题 : 版本 2.0
问题描述:在 nacos 的源码中为什么这个 set 方法一调用就往服务端发一个请求grpcconn.setPayloadstreamobserver(payloadstream0bserver);
常规理解:这段代码的目的是为 gRPC 连接设置一个观察者,以便在异步通信中处理从服务器返回的负载数据流。基于上面的问题向GPT进行提问
接下来的对话你将以一名 java 高级开发工程师的身份和我聊天,在 nacos 2.0 版本中的源码里面为什么这个 set 方法一调用就往服务端发一个请求,请详细阐述 grpcconn.setPayloadstreamobserver(payloadstream0bserver);


总结
- 源码阅读准备:在开始阅读源码之前,确保对 Java 语言有足够的了解,熟悉常用的设计模式和数据结构。对于 GPT 可以询问一些Java 编程知识或设计模式的问题,以帮助更好地理解源码;
- 提出问题:在阅读源码时,有针对性地提出问题,例如:询问某个类或方法的作用、某个设计模式在代码中的应用等。通过与 GPT 的互动了解代码的功能和结构;
- 请求代码解释:当遇到难以理解的代码片段时,可以将代码片段复制并粘贴到 GPT 中,请求解释代码的功能和作用。GPT 可以帮助理解这部分代码的逻辑和执行过程;
- 代码重构与优化:如果觉得源码中有可以改进的地方,可以请教 GPT 关于重构和优化的建议。GPT 可以提供一些实用的代码优化建议,帮助提高代码质量;
- 编写测试用例:为了确保源码的稳定性和可靠性,可以请教 GPT 如何编写针对特定功能的测试用例。GPT 可以提供测试用例的示例和建议,帮助编写有效的测试;
- 学习新技术:当在阅读源码时,可能会遇到一些不熟悉的技术和框架。在这种情况下,可以向 GPT 咨询相关技术的使用方法和最佳实践,以便更好地理解和应用这些技术;
- 问题总结与反馈:在源码学习过程中,整理遇到的问题和疑惑,并向 GPT 进行反馈。GPT 可以帮助总结这些问题的解决方案,巩固在源码学习过程中的收获。






