您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
限流算法及各类常用方案介绍
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
限流算法及各类常用方案介绍
kansting
2023-05-04
IP归属:北京
880浏览
## 应用场景 现代互联网很多业务场景,比如秒杀、下单、查询商品详情,最大特点就是高并发,而往往我们的系统不能承受这么大的流量,继而产生了很多的应对措施:CDN、消息队列、多级缓存、异地多活。 但是无论如何优化,终究由硬件的物理特性决定了我们系统性能的上限,如果强行接收所有请求,往往造成雪崩。 这时候限流熔断就发挥作用了,限制请求数,快速失败,保证系统满负载又不超限。 > 极致的优化,就是将硬件使用率提高到100%,但永远不会超过100% ## 常用限流算法 #### 1. 计数器 直接计数,简单暴力,举个例子: 比如限流设定为1小时内10次,那么每次收到请求就计数加一,并判断这一小时内计数是否大于上限10,没超过上限就返回成功,否则返回失败。 这个算法的**缺点**就是在时间临界点会有较大瞬间流量。 继续上面的例子,理想状态下,请求匀速进入,系统匀速处理请求: 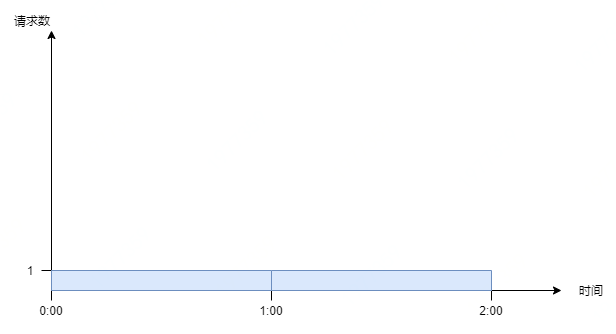 但实际情况中,请求往往不是匀速进入,假设第n小时59分59秒的时候突然进入10个请求,全部请求成功,到达下一个时间区间时刷新计数。那么第n+1小时刚开始又打进10个请求,等于瞬间进入20个请求,肯定不符合“1小时10次”的规则,这种现象叫做“突刺现象”。 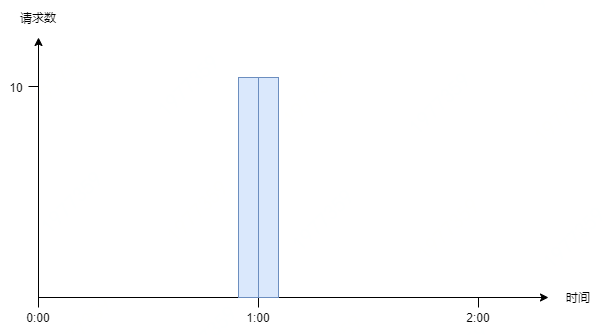 为解决这个问题,计数器算法经过优化后,产生了**滑动窗口**算法: 我们将时间间隔均匀分隔,比如将一分钟分为6个10秒,每一个10秒内单独计数,总的数量限制为这6个10秒的总和,我们把这6个10秒成为“**窗口**”。 那么每过10秒,窗口往前滑动一步,数量限制变为新的6个10秒的总和,如图所示: 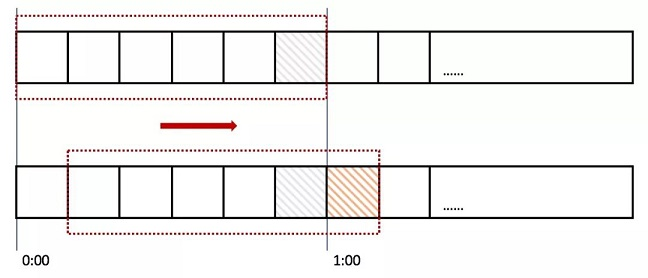 那么如果在临界时,收到10个请求(图中灰色格子),在下一个时间段来临时,橙色部分又进入10个请求,但窗口内包含灰色部分,所以已经到达请求上线,不再接收新的请求。 这就是**滑动窗口**算法。 但是滑动窗口仍然有缺陷,为了保证匀速,我们要划分尽可能多的格子,而格子越多,每一个格子能够接收的请求数就越少,这样就限制了系统瞬间处理能力。 #### 2. 漏桶 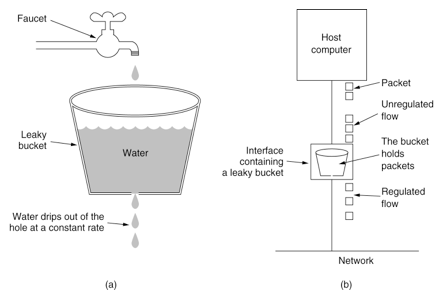 漏桶算法其实也很简单,假设我们有一个固定容量的桶,流速(系统处理能力)固定,如果一段时间水龙头水流太大,水就溢出了(请求被抛弃了)。 用编程的语言来说,每次请求进来都放入一个先进先出的队列中,队列满了,则直接返回失败。另外有一个线程池固定间隔不断地从这个队列中拉取请求。 消息队列、jdk的线程池,都有类似的设计。 #### 3. 令牌桶 令牌桶算法比漏桶算法稍显复杂。 首先,我们有一个固定容量的桶,桶里存放着令牌(token)。桶一开始是空的,token以一个固定的速率往桶里填充,直到达到桶的容量,多余的令牌将会被丢弃。每当一个请求过来时,就会尝试从桶里移除一个令牌,如果没有令牌的话,请求无法通过。 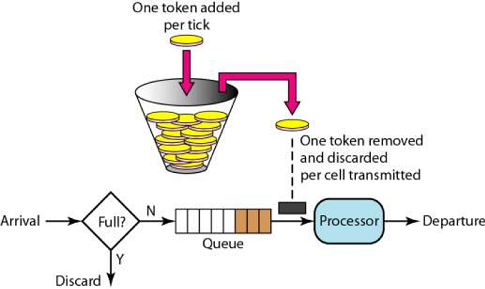 #### 漏桶和令牌桶算法的区别: 漏桶的特点是**消费能力固定**,当请求量超出消费能力时,提供一定的冗余能力,把请求缓存下来匀速消费。优点是对下游保护更好。 令牌桶遇到激增流量会更从容,只要存在令牌,则可以一并消费掉。适合有突发特征的流量,如秒杀场景。 ## 限流方案 ### 一、容器限流 #### 1. Tomcat tomcat能够配置连接器的最大线程数属性,该属性`maxThreads`是Tomcat的最大线程数,当请求的并发大于`maxThreads`时,请求就会排队执行(**排队数设置:accept-count**),这样就完成了限流的目的。 ```xml <Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" maxThreads="150" redirectPort="8443" /> ``` #### 2. Nginx Nginx 提供了两种限流手段:一是控制速率,二是控制并发连接数。 - **控制速率** 我们需要使用 `limit_req_zone`配置来限制单位时间内的请求数,即速率限制,示例配置如下: ```nginx limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s; ``` 第一个参数:$binary_remote_addr 表示通过remote_addr这个标识来做限制,“binary_”的目的是缩写内存占用量,是限制同一客户端ip地址。 第二个参数:zone=mylimit:10m表示生成一个大小为10M,名字为one的内存区域,用来存储访问的频次信息。 第三个参数:rate=2r/s表示允许相同标识的客户端的访问频次,这里限制的是每秒2次,还可以有比如30r/m的。 - **并发连接数** 利用 `limit_conn_zone` 和 `limit_conn` 两个指令即可控制并发数,示例配置如下 ```nginx limit_conn_zone $binary_remote_addr zone=perip:10m; limit_conn_zone $server_name zone=perserver:10m; server { ... limit_conn perip 10; # 限制同一个客户端ip limit_conn perserver 100; } ``` **只有当 request header 被后端处理后,这个连接才进行计数** ### 二、服务端限流 #### 1. Semaphore JUC包中提供的**信号量**工具,它的内部维护了一个同步队列,我们可以在每个请求进来的时候,尝试获取信号量,获取不到可以阻塞或者快速失败 简单样例: ```java Semaphore sp = new Semaphore(3); sp.require(); // 阻塞获取 System.out.println("执行业务逻辑"); sp.release(); ``` #### 2. RateLimiter Guava中基于令牌桶实现的一个限流工具,使用非常简单,通过方法`create()`创建一个桶,然后通过`acquire()`或者`tryAcquire()`获取令牌: ```java RateLimiter rateLimiter = RateLimiter.create(5); // 初始化令牌桶,每秒往桶里存放5个令牌 rateLimiter.acquire(); // 自旋阻塞获取令牌,返回阻塞的时间,单位为秒 rateLimiter.tryAcquire(); // 获取令牌,返回布尔结果,超过超时时间(默认为0,单位为毫秒)则返回失败 ``` RateLimiter在实现时,允许暴增请求的突发情况存在。 举个例子,我们有一个速率为每秒5个令牌的RateLimiter: 当令牌桶空了的时候,如果继续获取一个令牌,那么会在下一次补充令牌的时候返回结果 但如果直接获取5个令牌,并不是等待桶内补齐5个令牌后再返回,而是仍旧会在令牌桶补充**下一个**令牌的时候直接返回,而预支令牌所需的补充时间会在下一次请求时进行补偿 ```java public void testSmoothBursty() { RateLimiter r = RateLimiter.create(5); for (int i = 0; i++ < 2; ) { System.out.println("get 5 tokens: " + r.acquire(5) + "s"); System.out.println("get 1 tokens: " + r.acquire(1) + "s"); System.out.println("get 1 tokens: " + r.acquire(1) + "s"); System.out.println("get 1 tokens: " + r.acquire(1) + "s"); System.out.println("end"); } } /** * 控制台输出 * get 5 tokens: 0.0s 初始化时桶是空的,直接从空桶获取5个令牌 * get 1 tokens: 0.998068s 滞后效应,需要替前一个请求进行等待 * get 1 tokens: 0.196288s * get 1 tokens: 0.200391s * end * get 5 tokens: 0.195756s * get 1 tokens: 0.995625s 滞后效应,需要替前一个请求进行等待 * get 1 tokens: 0.194603s * get 1 tokens: 0.196866s * end */ ``` #### 3. Hystrix Netflix开源的熔断组件,支持两种资源隔离策略:THREAD(默认)或者SEMAPHORE - **线程池**:每个command运行在一个线程中,限流是通过线程池的大小来控制的 - **信号量**:command是运行在调用线程中,但是通过信号量的容量来进行限流 线程池策略对每一个资源创建一个线程池以进行流量管控,优点是资源隔离彻底,缺点是容易造成资源碎片化。 使用样例: ```java // HelloWorldHystrixCommand要使用Hystrix功能 public class HelloWorldHystrixCommand extends HystrixCommand { private final String name; public HelloWorldHystrixCommand(String name) { super(HystrixCommandGroupKey.Factory.asKey("ExampleGroup")); this.name = name; } // 如果继承的是HystrixObservableCommand,要重写Observable construct() @Override protected String run() { return "Hello " + name; } } ``` 调用该command: ```java String result = new HelloWorldHystrixCommand("HLX").execute(); System.out.println(result); // 打印出Hello HLX ``` **Hystrix已经在2018年停止开发,官方推荐替代项目[**Resilience4j**](https://resilience4j.readme.io/)** 更多使用介绍可查看:[Hystrix熔断器的使用](https://kang.fun/hystrix) #### 4. Sentinel 阿里开源的限流熔断组件,底层统计采用滑动窗口算法,限流方面有两种使用方式:API调用和注解,内部采插槽链来统计和执行校验规则。 通过为方法增加注解`@SentinelResource(String name)`或者手动调用`SphU.entry(String name)`方法开启流控。 **使用API手动调用流控示例:** ```java @Test public void testRule() { // 配置规则. initFlowRules(); int count = 0; while (true) { try (Entry entry = SphU.entry("HelloWorld")) { // 被保护的逻辑 System.out.println("run " + ++count + " times"); } catch (BlockException ex) { // 处理被流控的逻辑 System.out.println("blocked after " + count); break; } } } // 输出结果: // run 1 times // run 2 times // run 3 times ``` 关于Sentinel的详细介绍可查看:[Sentinel-分布式系统的流量哨兵](https://kang.fun/sentinel) ### 三、分布式下限流方案 线上环境下,如果对共用资源(如数据库、下游服务)做统一流量限制,那么单机限流显然不能满足,而需要分布式流控方案。 分布式限流主要采取中心系统流量管控的方案,由一个中心系统统一管控流量配额。 **这种方案的缺点就是中心系统的可靠性,所以一般需要备用方案,在中心系统不可用时,退化为单机流控。** #### 1. Tair通过incr方法实现简单窗口 实现方式是使用`incr()`自增方法来计数并与阈值进行大小比较。 ```java public boolean tryAcquire(String key) { // 以秒为单位构建tair的key String wrappedKey = wrapKey(key); // 每次请求+1,初始值为0,key的有效期设置5s Result<Integer> result = tairManager.incr(NAMESPACE, wrappedKey, 1, 0, 5); return result.isSuccess() && result.getValue() <= threshold; } private String wrapKey(String key) { long sec = System.currentTimeMillis() / 1000L; return key + ":" + sec; } ``` 【备注】incr方法的参数说明 ```c // 方法定义: Result incr(int namespace, Serializable key, int value, int defaultValue, int expireTime) /* 参数含义: namespace - 申请时分配的 namespace key - key 列表,不超过 1k value - 增加量 defaultValue - 第一次调用 incr 时的 key 的 count 初始值,第一次返回的值为 defaultValue + value。 expireTime - 数据过期时间,单位为秒,可设相对时间或绝对时间(Unix 时间戳)。 */ ``` #### 2. Redis通过lua脚本实现简单窗口 与Tair实现方式类似,不过redis的`incr()`方法不能原子性的设置过期时间,所以需要使用lua脚本,在第一次调用返回1时,设置下过期时间为1秒。 ```lua local current current = redis.call("incr",KEYS[1]) if tonumber(current) == 1 then redis.call("expire",KEYS[1],1) end return current ``` #### 3. Redis通过lua脚本实现令牌桶 实现思路是获取令牌后,用SET记录“请求时间”和“剩余token数量”。 每次请求令牌时,通过这两个参数和请求的时间、流速等参数进行计算,返回是否获取令牌成功。 **获取令牌lua脚本:** ```lua local ratelimit_info = redis.pcall('HMGET',KEYS[1],'last_time','current_token') local last_time = ratelimit_info[1] local current_token = tonumber(ratelimit_info[2]) local max_token = tonumber(ARGV[1]) local token_rate = tonumber(ARGV[2]) local current_time = tonumber(ARGV[3]) local reverse_time = 1000/token_rate if current_token == nil then current_token = max_token last_time = current_time else local past_time = current_time-last_time local reverse_token = math.floor(past_time/reverse_time) current_token = current_token+reverse_token last_time = reverse_time*reverse_token+last_time if current_token>max_token then current_token = max_token end end local result = 0 if(current_token>0) then result = 1 current_token = current_token-1 end redis.call('HMSET',KEYS[1],'last_time',last_time,'current_token',current_token) redis.call('pexpire',KEYS[1],math.ceil(reverse_time*(max_token-current_token)+(current_time-last_time))) return result ``` **初始化令牌桶lua脚本:** ```lua local result=1 redis.pcall("HMSET",KEYS[1],"last_mill_second",ARGV[1],"curr_permits",ARGV[2],"max_burst",ARGV[3],"rate",ARGV[4]) return result ```
上一篇:还在自己实现责任链?我建议你造轮子之前先看看这个开源项目
下一篇:Netty服务端开发及性能优化
kansting
文章数
10
阅读量
40525
作者其他文章
01
从原理聊JVM(四):JVM中的方法调用原理
1 引言多态是Java语言极为重要的一个特性,可以说是Java语言动态性的根本,那么线程执行一个方法时到底在内存中经历了什么,JVM又是如何确定方法执行版本的呢?2 栈帧JVM中由栈帧存储方法的局部变量表、操作数栈、动态连接和方法返回地址等信息。每一个方法的调用就是从入栈到出栈到过程。2.1 局部变量表局部变量表由变量槽组成,《Java虚拟机规范》指出:“每个变量槽都应该能存放一个boolean、
01
从原理聊JVM(三):详解现代垃圾回收器Shenandoah和ZGC
ShenandoahShenandoah一词来自于印第安语,十九世纪四十年代有一首著名的航海歌曲在水手中广为流传,讲述一位年轻富商爱上印第安酋长Shenandoah的女儿的故事。后来美国有一条位于Virginia州西部的小河以此命名,所以Shenandoah的中文译名为“情人渡”。Shenandoah首次出现在Open JDK12中,是由Red Hat开发,主要为了解决之前各种垃圾回收器处理大堆时
01
【架构与设计】常见微服务分层架构的区别和落地实践
前言从强调内外隔离的六边形架构,逐渐发展衍生出的层层递进、注重领域模型的洋葱架构,再到和DDD完美契合的整洁架构。架构风格的不断演进,其实就是为了适应软件需求越来越复杂的特点。可以看到,越现代的架构风格越倾向于清晰的职责定位,且让领域模型成为架构的核心。基于这些架构风格,在软件架构设计过程中又有非常多的架构分层模型。传统三层架构传统服务通常使用三层架构:门面层:作为服务暴露的入口,处理所有的外部请
01
从原理聊JVM(一):染色标记和垃圾回收算法
系列文章: 从原理聊JVM(二):从串行收集器到分区收集开创者G1 从原理聊JVM(三):详解现代垃圾回收器Shenandoah和ZGC 1 JVM运行时内存划分1.1 运行时数据区域方法区 属于共享内存区域,存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。运行时常量池,属于方法区的一部分,用于存放编译期生成的各种字面量和符号引用。 JDK1.8之前,Hot
kansting
文章数
10
阅读量
40525
作者其他文章
01
从原理聊JVM(四):JVM中的方法调用原理
01
从原理聊JVM(三):详解现代垃圾回收器Shenandoah和ZGC
01
【架构与设计】常见微服务分层架构的区别和落地实践
01
从原理聊JVM(一):染色标记和垃圾回收算法
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 kansting
kansting 2023-05-04
2023-05-04 880浏览
880浏览





