您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
Python自动化测试的配置层实现方式对标与落地
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
Python自动化测试的配置层实现方式对标与落地
自猿其说Tech
2023-06-09
IP归属:北京
1731浏览
Python
Python中什么是配置文件,配置文件如何使用,有哪些支持的配置文件等内容,话不多说,让我们一起看看吧~ # 1 什么是配置文件? 配置文件是用于配置计算机程序的参数和初始化设置的文件,如果没有这些配置程序可能无法运行或是影响运行(运行速度、便捷性等),使用配置文件的好处在于,部分内容以及环境运行时只需要修改配置文件的参数内容,而无需去代码里查找并修改,提高便捷性、提高可维护性。 # 2 配置文件有哪几种? 配置主要有四种形式: 1. 第一种是YAML、JSON、XML、TOML、INI、Linux系统中的.bashrc一类,主要应用于软件测试领域,在软件测试的领域行业中,大多数公司采用最新的YAML形式来作为配置文件,例如数据库地址、用例数据等内容的存放,而少部分公司仍然采用旧的INI配置形式 1. 第二种是excel表格的形式,在excel表格中会有固定的title代表每个字段列的含义,有多列,以此来进行配置,多用于游戏领域中,在游戏行业大量使用excel表格的形式,已经是一个常态了。 1. 第三种是py文件,py文件对于一个纯Python项目而言是非常方便的,它不需要做数据的读取操作,只需要进行导入即可,不好的点在于,没有YAML这一类灵活,YAML配置文件无论是Python、Java等语言,都是支持的,且数据类型支持很多,而py的配置文件,就只能用作于python,有一定的局限性。 1. 第四种是txt文本格式,通过读取的方式来识别到txt文本内容,通常而言是测开或者测试工程师制作的简便工具,供给业务层面的测试人员进行使用,降低了YAML这种配置的理解难度,也避免了打开excel的缓慢,用轻量级txt来代替是一个不错的选择。 ## 2.1 ini python3自带的ini .ini 文件是Initialization File的缩写,即初始化文件,是windows的系统配置文件所采用的存储格式,统管windows的各项配置 ### 2.1.1 ini文件的定义 .ini 文件通常由节(Section)、键(key)和值(value)组成。具体形式如下: ``` db.ini [mysql] host = 127.0.0.1 port = 3306 user = root password = 123456 database = test ``` ### 2.1.2 python读取ini文件 使用python内置的 configparser 标准库进行解析ini文件。 read() 读取文件内容 items() 获取指定节的所有键值对 ``` # -*- coding: utf-8 -*- ''' * @Author : wxy * @Date : 2022-08-24 11:11:06 * @Description : 读取ini文件 * @LastEditTime : 2022-08-24 11:11:06 ''' from configparser import ConfigParser from pprint import pprint import pymysql # ini文件路径 ini_file = './db.ini' # 读取ini的节(Section) db_name = 'mysql' # configparser实例化 text = ConfigParser() # 读取ini文件内容 text.read(ini_file) # text.items()返回list,元素为tuple,元组格式为 key,value db_tuple = text.items(db_name) print(db_tuple) # 将元组转换成dict db_dict = dict(text.items(db_name)) print(db_dict) ``` ## 2.2 json JSON(JavaScript Object Notation,) 是一种轻量级的数据交换格式。 ### 2.2.1 json文件的定义 简单的json示例 ``` { "mysql": { "host": "127.0.0.1", "port": 3306, "user": "root", "password": "123456", "database": "test" } } ``` ### 2.2.2 python读取json文件 load() 从json文件中读取json格式数据 loads() 将字符串类型数据转化为json格式数据 dump() 将json格式数据保存到文件 dumps() 将json格式数据保存为字符串类型 ``` # -*- coding: utf-8 -*- ''' * @Author : wxy * @Date : 2022-8-24 11:39:44 * @Description : 读取json文件 * @LastEditTime : 2022-8-24 11:39:44 ''' import json from pprint import pprint import pymysql json_file = "./db.json" db_name = "mysql" web = "web" with open(json_file) as f: cfg = json.load(f)[db_name] print(cfg) with open(json_file) as f: cfg = json.load(f)[web] print(cfg['user']) ``` ## 2.3 toml TOML 是 Github 联合创始人 Tom Preston-Werner 所提出的一种配置文件格式,是一种旨在成为一个小规模、易于使用的语义化的配置文件格式,它被设计为可以无二义性的转换为一个哈希表。 ### 2.3.1 定义toml文件 语法: TOML的语法广泛地由key = "value"、[节名]、#注释构成。 支持以下数据类型:字符串、整形、浮点型、布尔型、日期时间、数组和图表。 ``` # db.toml [mysql] [mysql.config] host = "127.0.0.1" user = "root" port = 3306 password = "123456" database = "test" [mysql.parameters] pool_size = 5 charset = "utf8" [mysql.fields] course_cols = ["cno", "cname", "ccredit", "cdept"] ``` ### 2.3.2 python读取toml文件 使用外部库 toml 解析toml文件 ``` # -*- coding: utf-8 -*- ''' * @Description : 读取toml文件 * @LastEditTime : 2022-08-14 11:31:07 ''' import toml from pprint import pprint import pymysql toml_file = "./db.toml" cfg = toml.load(toml_file)['mysql'] pprint(cfg) ``` ## 2.4 yaml YAML(YAML Ain't a Markup Language", YAML不是一种标记语言) 格式是目前较为流行的一种配置文件,它早在 2001 由一个名为 Clark Evans 的人提出;同时它也是目前被广泛使用的配置文件类型。 ### 2.4.1 定义yaml文件 ``` # db.yaml mysql: config: host: "127.0.0.1" port: 3306 user: "root" password: "" database: "stu_sys" parameters: pool_size: 5 charset: "utf8" fileds: course_cols: - cno - cname - ccredit - cdept ``` ### 2.4.2 python读取yaml文件 使用外部库 pyyaml 解析toml文件。 ``` # -*- coding: utf-8 -*- ''' * @Author : wxy * @Date : 2022-8-24 11:34:37 * @Description : 读取yaml文件 * @LastEditTime : 2022-8-24 11:34:37 ''' import yaml from pprint import pprint import pymysql yaml_file = "./db.yaml" with open(yaml_file, 'r') as f: cfg = yaml.safe_load(f) print(cfg) ``` ## 2.5 Python xlrd 读取 操作Excel python Excel库对比 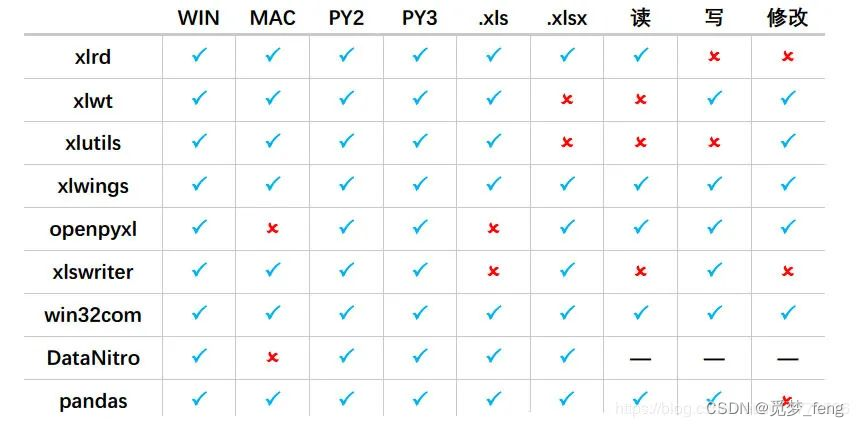 本次主要关注python xlrd读取 操作excel ### 2.5.1 xlrd模块介绍 1.什么是xlrd模块? python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库。 2.为什么使用xlrd模块? 在UI自动化或者接口自动化中数据维护是一个核心,所以此模块非常实用。 xlrd模块可以用于读取Excel的数据,速度非常快,推荐使用! 官方文档:https://xlrd.readthedocs.io/en/latest/ ### 2.5.2 安装xlrd模块 到python官网下载http://pypi.python.org/pypi/xlrd 模块安装,前提是已经安装了python 环境。 或者在cmd窗口 pip install xlrd 最新的xlrd不支持Excel xlsx文件的读取。所以需要安装旧版本 pip install xlrd==1.2.0 ### 2.5.3 使用介绍 1.常用单元格的数据类型 - empty(空的) - string(text) - number - date - boolean - error - blank(空白表格) 2.导入模块 ``` import xlrd ``` 3.打开Excel文件读取数据 ``` data = xlrd.open_workbook(filename)#文件名以及路径,如果路径或者文件名有中文给前面加一个 r ``` 4.常用的函数 excel中最重要的方法就是book和sheet的操作 - 获取book(excel文件)中一个工作表 ``` table = data.sheets()[0] #通过索引顺序获取 table = data.sheet_by_index(sheet_indx) #通过索引顺序获取 table = data.sheet_by_name(sheet_name) #通过名称获取 # 以上三个函数都会返回一个xlrd.sheet.Sheet()对象 names = data.sheet_names() #返回book中所有工作表的名字 data.sheet_loaded(sheet_name or indx) # 检查某个sheet是否导入完毕 ``` - 行的操作 ``` nrows = table.nrows # 获取该sheet中的行数,注,这里table.nrows后面不带(). table.row(rowx) # 返回由该行中所有的单元格对象组成的列表,这与tabel.raw()方法并没有区别。 table.row_slice(rowx) # 返回由该行中所有的单元格对象组成的列表 table.row_types(rowx, start_colx=0, end_colx=None) # 返回由该行中所有单元格的数据类型组成的列表; # 返回值为逻辑值列表,若类型为empy则为0,否则为1 table.row_values(rowx, start_colx=0, end_colx=None) # 返回由该行中所有单元格的数据组成的列表 table.row_len(rowx) # 返回该行的有效单元格长度,即这一行有多少个数据 ``` - 列(colnum)的操作 ``` ncols = table.ncols # 获取列表的有效列数 table.col(colx, start_rowx=0, end_rowx=None) # 返回由该列中所有的单元格对象组成的列表 table.col_slice(colx, start_rowx=0, end_rowx=None) # 返回由该列中所有的单元格对象组成的列表 table.col_types(colx, start_rowx=0, end_rowx=None) # 返回由该列中所有单元格的数据类型组成的列表 table.col_values(colx, start_rowx=0, end_rowx=None) # 返回由该列中所有单元格的数据组成的列表 ``` - 单元格的操作 ``` table.cell(rowx,colx) # 返回单元格对象 table.cell_type(rowx,colx) # 返回对应位置单元格中的数据类型 table.cell_value(rowx,colx) # 返回对应位置单元格中的数据 ``` ### 2.5.4 实战训练 使用xlrd模块进行读取: ``` import xlrd xlsx = xlrd.open_workbook('./3_1 xlrd 读取 操作练习.xlsx') # 通过sheet名查找:xlsx.sheet_by_name("sheet1") # 通过索引查找:xlsx.sheet_by_index(3) table = xlsx.sheet_by_index(0) # 获取单个表格值 (2,1)表示获取第3行第2列单元格的值 value = table.cell_value(2, 1) print("第3行2列值为",value) # 获取表格行数 nrows = table.nrows print("表格一共有",nrows,"行") # 获取第4列所有值(列表生成式) name_list = [str(table.cell_value(i, 3)) for i in range(1, nrows)] print("第4列所有的值:",name_list) ``` ## 2.6 Python xlwt 写入 操作Excel(仅限xls格式!) xlwt可以用于写入新的Excel表格或者在原表格基础上进行修改,速度也很快,推荐使用! 官方文档:https://xlwt.readthedocs.io/en/latest/ ### 2.6.1 pip安装xlwt ``` pip install xlwt ``` ### 2.6.2 使用xlwt创建新表格并写入 编写xlwt新表格写入程序: ``` # 3.2.2 使用xlwt创建新表格并写入 def fun3_2_2(): # 创建新的workbook(其实就是创建新的excel) workbook = xlwt.Workbook(encoding= 'ascii') # 创建新的sheet表 worksheet = workbook.add_sheet("My new Sheet") # 往表格写入内容 worksheet.write(0,0, "内容1") worksheet.write(2,1, "内容2") # 保存 workbook.save("新创建的表格.xls") ``` ### 2.6.3 xlwt 设置字体格式 程序示例: ``` # 3.2.3 xlwt设置字体格式 def fun3_2_3(): # 创建新的workbook(其实就是创建新的excel) workbook = xlwt.Workbook(encoding= 'ascii') # 创建新的sheet表 worksheet = workbook.add_sheet("My new Sheet") # 初始化样式 style = xlwt.XFStyle() # 创建字体样式 font = xlwt.Font() font.name = 'Times New Roman' #字体 font.bold = True #加粗 font.underline = True #下划线 font.italic = True #斜体 # 设置样式 style.font = font # 往表格写入内容 worksheet.write(0,0, "内容1") worksheet.write(2,1, "内容2",style) # 保存 workbook.save("新创建的表格.xls") # 设置列宽 worksheet.col(0).width = 256*20 # 设置行高 style = xlwt.easyxf('font:height 360;') # 18pt,类型小初的字号 row = worksheet.row(0) row.set_style(style) # 合并 第1行到第2行 的 第0列到第3列 worksheet.write_merge(1, 2, 0, 3, 'Merge Test') # 设置边框样式 borders = xlwt.Borders() # Create Borders borders.left = xlwt.Borders.DASHED borders.right = xlwt.Borders.DASHED borders.top = xlwt.Borders.DASHED borders.bottom = xlwt.Borders.DASHED borders.left_colour = 0x40 borders.right_colour = 0x40 borders.top_colour = 0x40 borders.bottom_colour = 0x40 ``` ## 2.7 Python xlutils 修改 操作Excel xlutils可用于拷贝原excel或者在原excel基础上进行修改,并保存; 官方文档:https://xlutils.readthedocs.io/en/latest/ ### 2.7.1 pip安装xlutils ``` pip install xlutils ``` ### 2.7.2 xlutils拷贝源文件(需配合xlrd使用) 程序示例: ``` # 3.3.2 拷贝源文件 def fun3_3_2(): workbook = xlrd.open_workbook('3_3 xlutils 修改操作练习.xlsx') # 打开工作簿 new_workbook = copy(workbook) # 将xlrd对象拷贝转化为xlwt对象 new_workbook.save("new_test.xls") # 保存工作簿 ``` ### 2.7.3 xlutils 读取 写入 (也就是修改)Excel 表格信息 程序示例: ``` # 3.3.3 xlutils读取 写入 Excel 表格信息 def fun3_3_3(): # file_path:文件路径,包含文件的全名称 # formatting_info=True:保留Excel的原格式(使用与xlsx文件) workbook = xlrd.open_workbook('3_3 xlutils 修改操作练习.xlsx') new_workbook = copy(workbook) # 将xlrd对象拷贝转化为xlwt对象 # 读取表格信息 sheet = workbook.sheet_by_index(0) col2 = sheet.col_values(1) # 取出第二列 cel_value = sheet.cell_value(1, 1) print(col2) print(cel_value) # 写入表格信息 write_save = new_workbook.get_sheet(0) write_save.write(0, 0, "xlutils写入!") new_workbook.save("new_test.xls") # 保存工作簿 ``` ## 2.8 Python xlwings 读取 写入 修改 操作Excel ### 2.8.1 pip安装xlwings pip install xlwings ### 2.8.2 基本操作 引入库 import xlwings as xw (1)打开已存在的Excel文档 ``` # 导入xlwings模块 import xlwings as xw # 打开Excel程序,默认设置:程序可见,只打开不新建工作薄,屏幕更新关闭 app=xw.App(visible=True,add_book=False) app.display_alerts=False app.screen_updating=False # 文件位置:filepath,打开test文档,然后保存,关闭,结束程序 filepath=r'g:\Python Scripts\test.xlsx' wb=app.books.open(filepath) wb.save() wb.close() app.quit() ``` (2)新建Excel文档,命名为test.xlsx,并保存在D盘 ``` import xlwings as xw app=xw.App(visible=True,add_book=False) wb=app.books.add() wb.save(r'd:\test.xlsx') wb.close() app.quit() ``` (3) xlwings 读写 Excel 新建test.xlsx,在sheet1的第一个单元格输入 “人生” ,然后保存关闭,退出Excel程序。 ``` def fun3_4_4(): # 新建Excle 默认设置:程序可见,只打开不新建工作薄,屏幕更新关闭 app = xw.App(visible=True, add_book=False) app.display_alerts = False app.screen_updating = False # 打开已存在的Excel文件 wb=app.books.open('./3_4 xlwings 修改操作练习.xlsx') # 获取sheet对象 print(wb.sheets) sheet = wb.sheets[0] # sheet = wb.sheets["sheet1"] # 读取Excel信息 cellB1_value = sheet.range('B1').value print("单元格B1内容为:",cellB1_value) # 清除单元格内容和格式 sheet.range('A1').clear() # 写入单元格 sheet.range('A1').value = "xlwings写入" # 保存工作簿 wb.save('example_3.xlsx') # 退出工作簿 wb.close() # 退出Excel app.quit()l ``` ## 2.9 Python openpyxl 读取 写入 修改 操作Excel 在openpyxl中,主要用到三个概念:Workbooks,Sheets,Cells。 Workbook就是一个excel工作表; Sheet是工作表中的一张表页; Cell就是简单的一个格。 openpyxl就是围绕着这三个概念进行的,不管读写都是“三板斧”:打开Workbook,定位Sheet,操作Cell。 官方文档:https://openpyxl.readthedocs.io/en/stable/ 1.安装 pip install openpyxl 2.打开文件 (1)新建 ``` from openpyxl import Workbook # 实例化 wb = Workbook() # 激活 worksheet ws = wb.active ``` (2)打开已有 ``` from openpyxl import load_workbook wb = load_workbook('文件名称.xlsx') ``` 3.写入数据 ``` # 方式一:数据可以直接分配到单元格中(可以输入公式) ws['A1'] = 42 # 方式二:可以附加行,从第一列开始附加(从最下方空白处,最左开始)(可以输入多行) ws.append([1, 2, 3]) # 方式三:Python 类型会被自动转换 ws['A3'] = datetime.datetime.now().strftime("%Y-%m-%d") ``` 4.创建表(sheet) ``` # 方式一:插入到最后(default) ws1 = wb.create_sheet("Mysheet") # 方式二:插入到最开始的位置 ws2 = wb.create_sheet("Mysheet", 0) ``` 5.选择表(sheet) ``` # sheet 名称可以作为 key 进行索引 >>> ws3 = wb["New Title"] >>> ws4 = wb.get_sheet_by_name("New Title") >>> ws is ws3 is ws4 True ``` 6.查看表名(sheet) ``` # 显示所有表名 >>> print(wb.sheetnames) ['Sheet2', 'New Title', 'Sheet1'] # 遍历所有表 >>> for sheet in wb: ... print(sheet.title) ``` 7.保存数据 ``` wb.save('文件名称.xlsx') ``` 8.其它 (1)改变sheet标签按钮颜色 ``` ws.sheet_properties.tabColor = "1072BA" # 色值为RGB16进制值 ``` (2)获取最大行,最大列 ``` # 获得最大列和最大行 print(sheet.max_row) print(sheet.max_column) ``` (3)获取每一行每一列 sheet.rows为生成器, 里面是每一行的数据,每一行又由一个tuple包裹。 sheet.columns类似,不过里面是每个tuple是每一列的单元格。 ``` # 因为按行,所以返回A1, B1, C1这样的顺序 for row in sheet.rows: for cell in row: print(cell.value) # A1, A2, A3这样的顺序 for column in sheet.columns: for cell in column: print(cell.value) ``` (4)根据数字得到字母,根据字母得到数字 ``` from openpyxl.utils import get_column_letter, column_index_from_string # 根据列的数字返回字母 print(get_column_letter(2)) # B # 根据字母返回列的数字 print(column_index_from_string('D')) # 4 ``` (5)删除工作表 ``` # 方式一 wb.remove(sheet) # 方式二 del wb[sheet] ``` 项目实操---UI自动化中实践项目 需求:业务写入拣货容器,使用一次不可使用第二次,且脚本中固定读取固定位置 ``` import openpyxl from openpyxl.cell.cell import ILLEGAL_CHARACTERS_RE from openpyxl.utils import get_column_letter, column_index_from_string # 向sheetobj中的columnname列从start_row开始写入listdata def insert_listdata_to_column(sheetobj,listdata,column_name,start_row=3): # 根据列名获取列索引 colindex = column_index_from_string(column_name) print('colindex为{}'.format(colindex)) # 循环从开始行数到数据写入后最后一行 for rowindex in range(start_row, start_row + len(listdata)): # 写入list数值根据索引取值,从0开始 val = listdata[rowindex - start_row] print('val{}'.format(val)) print('rowindex{}'.format(rowindex)) try: sheetobj.cell(row = rowindex,column = colindex,value = val) except: # 出现非法字符时,可以将字符串的非法字符替换掉 val = ILLEGAL_CHARACTERS_RE.sub(r'',val) sheetobj.cell(row = rowindex,column = colindex,value = val) delrow = start_row + len(listdata) print('*********{}'.format(delrow)) sheetobj.delete_rows(delrow) def del_excel(): xlsx = xlrd.open_workbook(r'D:\pytest\inbound_data.xlsx') table =xlsx.sheet_by_index(2) # 获取第2列所有值 cel_value =table.col_values(1) cel_value=cel_value[3::] wb = openpyxl.load_workbook(r'D:\pytest\inbound_data.xlsx') sheet = wb["B2B出库"] print(sheet) insert_listdata_to_column(sheet,cel_value,'B',3) wb.save(r'D:\pytest\inbound_data.xlsx') del_excel() ``` # 3 总结 在本文中,简单介绍了几种配置文件和使用。根据不同的用例,复杂的工具/框架并不总是比简单的软件包更好。但无论选择哪一种,都应始终考虑可读性,可维护性以及如何尽早地发现错误。事实上,可以说配置文件只是另一种类型的代码。可以根据自己的项目框架来灵活运用啦~ ------------ 自猿其说Tech-JDL京东物流技术与数据智能部 **作者:王小云**
原创文章,需联系作者,授权转载
上一篇:当“代码农”遇上“码农”:揭秘主干开发的那些事儿
下一篇:浅析本地缓存技术-Guava Cache
相关文章
【技术干货】企业级扫描平台EOS-Jenkins集群进阶之路
AutoML系列 | 01-自动化机器学习技术原理
Python安装教程介绍
自猿其说Tech
文章数
426
阅读量
2551475
作者其他文章
01
深入JDK中的Optional
本文将从Optional所解决的问题开始,逐层解剖,由浅入深,文中会出现Optioanl方法之间的对比,实践,误用情况分析,优缺点等。与大家一起,对这项Java8中的新特性,进行理解和深入。
01
Taro小程序跨端开发入门实战
为了让小程序开发更简单,更高效,我们采用 Taro 作为首选框架,我们将使用 Taro 的实践经验整理了出来,主要内容围绕着什么是 Taro,为什么用 Taro,以及 Taro 如何使用(正确使用的姿势),还有 Taro 背后的一些设计思想来进行展开,让大家能够对 Taro 有个完整的认识。
01
Flutter For Web实践
Flutter For Web 已经发布一年多时间,它的发布意味着我们可以真正地使用一套代码、一套资源部署整个大前端系统(包括:iOS、Android、Web)。渠道研发组经过一段时间的探索,使用Flutter For Web技术开发了移动端可视化编程平台—Flutter乐高,在这里希望和大家分享下使用Flutter For Web实践过程和踩坑实践
01
配运基础数据缓存瘦身实践
在基础数据的常规能力当中,数据的存取是最基础也是最重要的能力,为了整体提高数据的读取能力,缓存技术在基础数据的场景中得到了广泛的使用,下面会重点展示一下配运组近期针对数据缓存做的瘦身实践。
自猿其说Tech
文章数
426
阅读量
2551475
作者其他文章
01
深入JDK中的Optional
01
Taro小程序跨端开发入门实战
01
Flutter For Web实践
01
配运基础数据缓存瘦身实践
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号










