京东工业是2021独立出来成立的新事业群-京东工业事业群,包括工业品、工业服务、工业互联等四大板块业务。工业互联业务主要是搭建工业互联网平台,用于将实时现场工业数据汇入平台进行分析,做数据智能工作。目前支持业务有国家电网管理平台、综合能源、碳中和交易、电力交易等业务。本文重点介绍下京东云 ClickHouse 在京东工业的综合能源领域的应用。工业互联网场景的数据主要有如下三个特点:微型的客户几百个设备,大型的客户十几万个仪表设备,上报频率每分钟1~60条不等,上报数据量很大。大部分客户将大屏实时应用当做实时仪表盘用,随时盯盘,使用上最高频的应用就是实时应用。
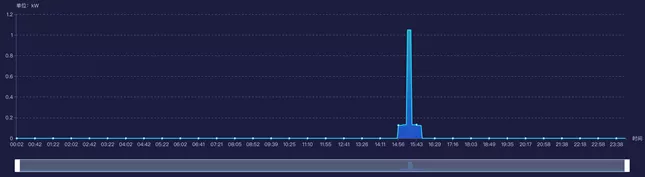
实时应用仪表盘举例
会经常发生底层环境的变动导致难以预料的脏数据,但是客户不允许错。比如设备错乱,出现过一堆设备部署错位置,导致很长一段时间上报数据都是数值错位;再比如新加字段,客户全局更新设备,导致需要引入新字段;或者更换单位,将t/h 转换成 kg/h,数值瞬间放大1000倍。
由于业务架构的演进,工业互联网平台也经历了以下技术架构的演进。

第一代的整体架构如下图,分为数据过滤、数据处理引擎、Influxdb和Kylin几个重要的组成部分。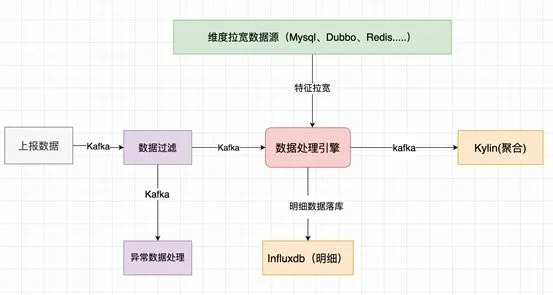
1、策略工厂过滤脏数据。通过全局通用规则+企业特定个性化规则来过滤。
2.、异常处理流程。可能前方环境变化导致误判,需要将异常数据转发暂存。如设备维度、组织架构维度、告警规则等,用于OLAP和算法模型- 如流量、电量等维度,方便复杂的查询瞬时状态以及复杂聚合
业务表现和感受
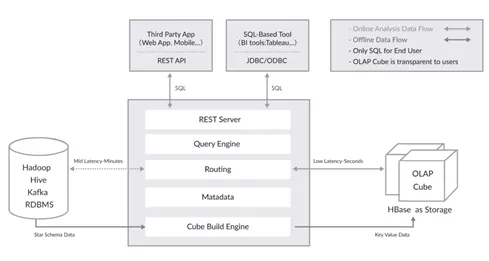
1、需要提前搭建依赖的各种hadoop环境,运维压力大。2、 需要提前预设好所有的cube、dimension、measures等等组合关系,上线后不能改。3、仅仅是基于预计算的查询引擎,并不存储数据,导致无法查询历史明细数据。
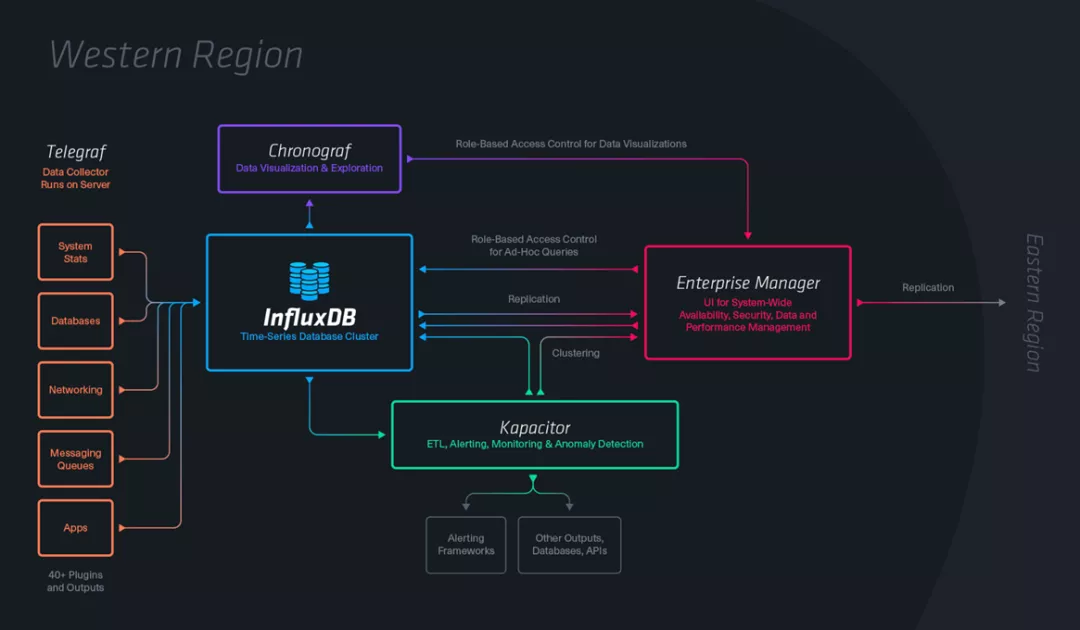
Influxdb架构图
1、 当时分布式版本还没开源,运维当时大部分没听说过这个新东西;2、 配套工具和文档很难找,入门困难,概念有点复杂,tag、series、fields…;1、 运维负担大:运维两套数据库,且kylin在性能一般的测试环境经常宕机3、数据一致性难保证:物联网和工业场景经常需要改数据4、架构基本满足需求,但是缺点大于优点,需要更好的架构方案
第二代架构使用的是ClickHouse官方推荐实践:Kafka引擎表+物化流程+本地表+分布式表
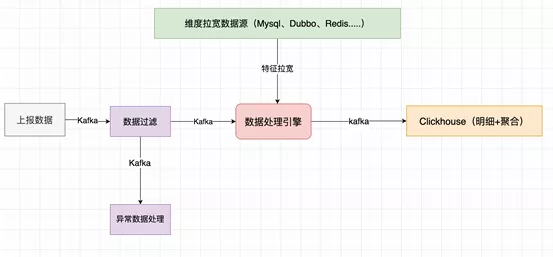
2、性能优秀。支持稳定大吞吐量数据写入,满足做中台建设的基础存储要求;超高的数据压缩率,节省磁盘存储;合理设置索引后,数据查询速度极快。
业务表现
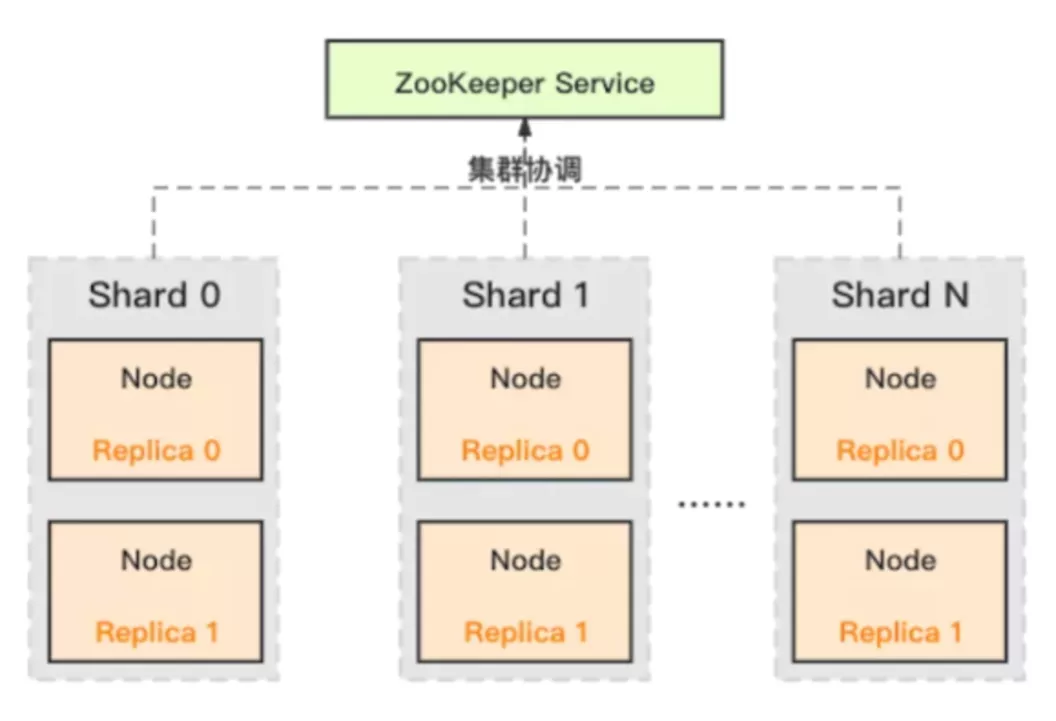
ClickHouse 架构图
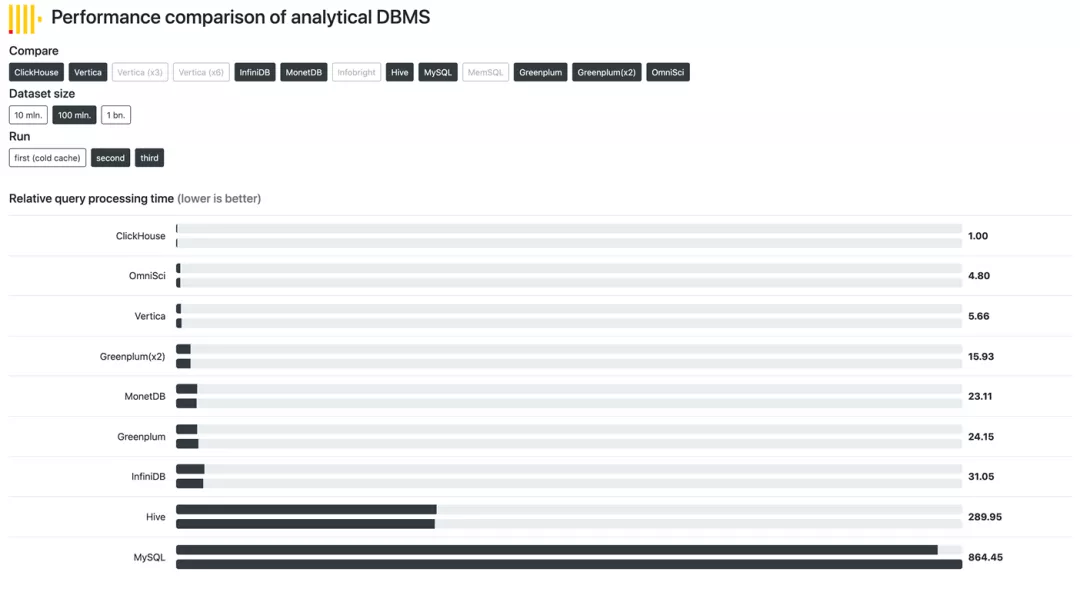
ClickHouse 性能对比图
一、 架构清晰简洁。最简单的多主分片结构,只依赖个zk,任何运维半天都能搭起来。二、 一站式方案,既能存数据,有能查数据,而且内部默认对查询的性能优化就很好。三、SQL友好,只要有mysql的基本技能就无缝衔接到ClickHouse的使用,没有入门门槛。总结一下,ClickHouse是很优秀的存储查询一揽子方案,对于需要大量group by和排序的聚合查询场景是几乎不二选择。对DBMS的支持目前也是够用的,像mysql的一样使用感受大大降低运维、研发等的使用门槛。
新的问题

数据基本按照日分区,如果切换到“年”,那么该接口就要瞬间聚合365个分区的数据,接口延时5~10s。大屏应用组件奇多,粗粗一算,刷新首页大屏瞬间十几个sql就提交到ClickHouse,如果都是跨越365分区的按年查询,压力更是暴增。
基于以上原因,下一代开始考虑尝试架构实时数仓:生产和消费相分离
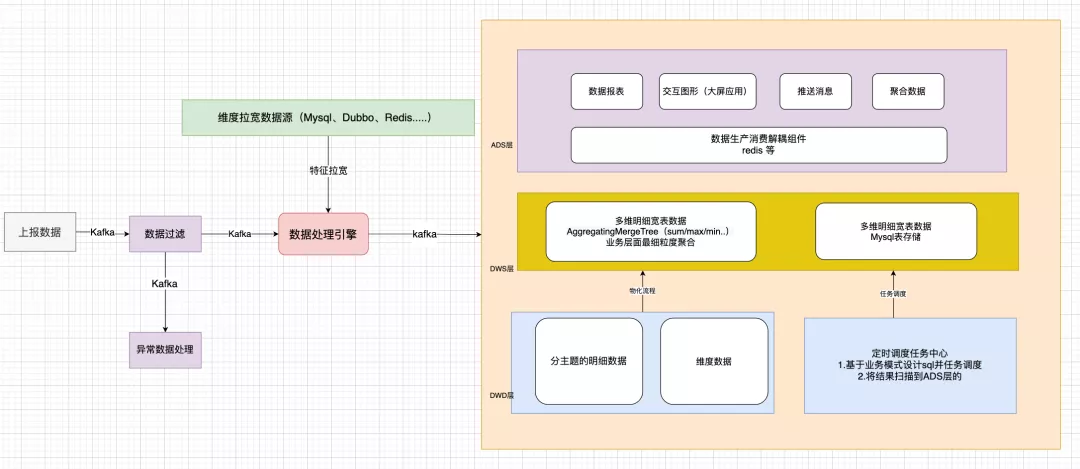
更建议提前维度拉宽,避免join;可以预留备用字段,业务上mapping使用。
面向:针对明细数据经常修改的场景,需要强数据一致性缺点:需要前期建设工作,包括分析提炼业务数据模式等1、数据生产消费解耦层:使用redis,按照QPS 5W+设计2、数据应用:直接使用redis里的数据,不需要访问下层数仓。
一、复杂查询聚合的OLAP场景,基本不支持OLTP场景典型特征是存在大量的group by、order by运算。
ClickHouse一般可以支持每秒几百MB的数据量写入,优化过的更高。裸奔使用,官方建议每秒最多查询100次,但是按照上述实时数仓方案优化过会大大提升。最适合在内部运营人员内部使用的场景上落地。四、当你OLAP聚合之外,也需要明细查询的场景,这是优秀的方案五、其它:不需要高级的DBMS功能,如事务性;不需要经常很复杂的表间操作,比如join。
ClickHouse的适用场景实践
一、官方提供的 kafka引擎表+物化流程+本地表+分布式表 的大宽表使用流程。尽可能使用提前的维度拉宽+大宽表+合理物化ETL流程解决问题,而不是复杂的表间join。使用好大量的mergeTree家族的不同表引擎,比如在数据去重,数据聚合等等特殊场景。二、所有的数据库方案都是数据仓库解决方案的一部分,需要站在数据仓库的高度上去想问题。
没有绝对的银弹可以解决所有数据问题,合理搭配去使用数据库,扬长避短,各司其职。